Evaluating the Effectiveness of Data Augmentation for Emotion Classification in Low-Resource Settings
2406.05190
0
0

Abstract
Data augmentation has the potential to improve the performance of machine learning models by increasing the amount of training data available. In this study, we evaluated the effectiveness of different data augmentation techniques for a multi-label emotion classification task using a low-resource dataset. Our results showed that Back Translation outperformed autoencoder-based approaches and that generating multiple examples per training instance led to further performance improvement. In addition, we found that Back Translation generated the most diverse set of unigrams and trigrams. These findings demonstrate the utility of Back Translation in enhancing the performance of emotion classification models in resource-limited situations.
Create account to get full access
Overview
- This paper evaluates the effectiveness of data augmentation techniques for improving emotion classification in low-resource settings.
- The authors explore the use of various data augmentation methods, such as targeted augmentation for low-resource event extraction, using machine translation to augment multilingual classification, and empowering large language models with textual data augmentation.
- The goal is to understand how these techniques can help overcome the challenge of limited training data in emotion classification tasks, particularly for low-resource languages or domains.
Plain English Explanation
Emotion classification is the task of identifying the emotional state expressed in a piece of text, such as a social media post or customer review. This is an important capability for many applications, such as customer service, mental health monitoring, and sentiment analysis.
However, building accurate emotion classification models can be challenging, especially in low-resource settings where there is limited training data available. This is where data augmentation can help. Data augmentation is the process of artificially creating new training examples by applying various transformations to the existing data, such as paraphrasing, translation, or adding noise.
The authors of this paper investigate the effectiveness of different data augmentation techniques for improving emotion classification performance in low-resource settings. They explore methods like targeted augmentation for low-resource event extraction, which focuses on generating relevant examples, and using machine translation to augment multilingual classification, which can help bridge the gap between languages.
The key idea is to leverage these data augmentation techniques to overcome the challenge of limited training data and improve the accuracy of emotion classification models, particularly in domains or languages where resources are scarce.
Technical Explanation
The paper begins by highlighting the importance of emotion classification in various applications and the challenge of limited training data in low-resource settings. To address this, the authors investigate the use of different data augmentation techniques.
They evaluate the effectiveness of several methods, including targeted augmentation for low-resource event extraction, using machine translation to augment multilingual classification, and empowering large language models with textual data augmentation. These techniques aim to generate relevant and diverse synthetic training examples to improve the model's performance in low-resource scenarios.
The authors conduct experiments on several emotion classification datasets, including a low-resource dataset, to assess the impact of the data augmentation methods. They compare the classification accuracy of models trained with and without data augmentation, and analyze the results to understand the strengths and limitations of each approach.
The key insights from the technical examination include the identification of the most effective data augmentation techniques for emotion classification in low-resource settings, the potential trade-offs between data quality and quantity, and the role of large language models in leveraging augmented data for improved performance.
Critical Analysis
The paper provides a comprehensive evaluation of data augmentation techniques for emotion classification in low-resource settings. The authors have carefully designed their experiments and considered various factors, such as dataset characteristics, model architectures, and the impact of data quality and quantity.
One potential limitation of the study is the reliance on a single low-resource dataset, which may not fully represent the diversity of real-world scenarios. It would be valuable to explore the generalizability of the findings by evaluating the techniques on a broader range of low-resource datasets, including different languages, domains, and data types.
Additionally, the paper does not delve into the potential biases or ethical considerations that may arise from the use of data augmentation techniques, particularly in sensitive applications such as mental health monitoring or sentiment analysis. Large language models for fine-grained emotion detection may introduce their own biases that could be amplified by data augmentation.
Overall, the paper makes a valuable contribution by providing empirical evidence on the effectiveness of data augmentation for emotion classification in low-resource settings. The insights can inform future research and guide practitioners in selecting and optimizing data augmentation strategies for their specific applications.
Conclusion
This paper presents a comprehensive evaluation of data augmentation techniques for improving emotion classification in low-resource settings. The authors explore the use of various methods, such as targeted augmentation for low-resource event extraction, using machine translation to augment multilingual classification, and empowering large language models with textual data augmentation, to overcome the challenge of limited training data.
The findings suggest that data augmentation can significantly improve the performance of emotion classification models in low-resource settings, with certain techniques proving more effective than others. The insights from this research can inform the development of more robust and accessible emotion classification systems, which have important applications in various domains, such as customer service, mental health monitoring, and social media analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Targeted Augmentation for Low-Resource Event Extraction
Sijia Wang, Lifu Huang
0
0
Addressing the challenge of low-resource information extraction remains an ongoing issue due to the inherent information scarcity within limited training examples. Existing data augmentation methods, considered potential solutions, struggle to strike a balance between weak augmentation (e.g., synonym augmentation) and drastic augmentation (e.g., conditional generation without proper guidance). This paper introduces a novel paradigm that employs targeted augmentation and back validation to produce augmented examples with enhanced diversity, polarity, accuracy, and coherence. Extensive experimental results demonstrate the effectiveness of the proposed paradigm. Furthermore, identified limitations are discussed, shedding light on areas for future improvement.
5/15/2024

Large Language Models on Fine-grained Emotion Detection Dataset with Data Augmentation and Transfer Learning
Kaipeng Wang, Zhi Jing, Yongye Su, Yikun Han
0
0
This paper delves into enhancing the classification performance on the GoEmotions dataset, a large, manually annotated dataset for emotion detection in text. The primary goal of this paper is to address the challenges of detecting subtle emotions in text, a complex issue in Natural Language Processing (NLP) with significant practical applications. The findings offer valuable insights into addressing the challenges of emotion detection in text and suggest directions for future research, including the potential for a survey paper that synthesizes methods and performances across various datasets in this domain.
4/10/2024

Evaluation and Comparison of Emotionally Evocative Image Augmentation Methods
Jan Ignatowicz, Krzysztof Kutt, Grzegorz J. Nalepa
0
0
Experiments in affective computing are based on stimulus datasets that, in the process of standardization, receive metadata describing which emotions each stimulus evokes. In this paper, we explore an approach to creating stimulus datasets for affective computing using generative adversarial networks (GANs). Traditional dataset preparation methods are costly and time consuming, prompting our investigation of alternatives. We conducted experiments with various GAN architectures, including Deep Convolutional GAN, Conditional GAN, Auxiliary Classifier GAN, Progressive Augmentation GAN, and Wasserstein GAN, alongside data augmentation and transfer learning techniques. Our findings highlight promising advances in the generation of emotionally evocative synthetic images, suggesting significant potential for future research and improvements in this domain.
6/26/2024
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
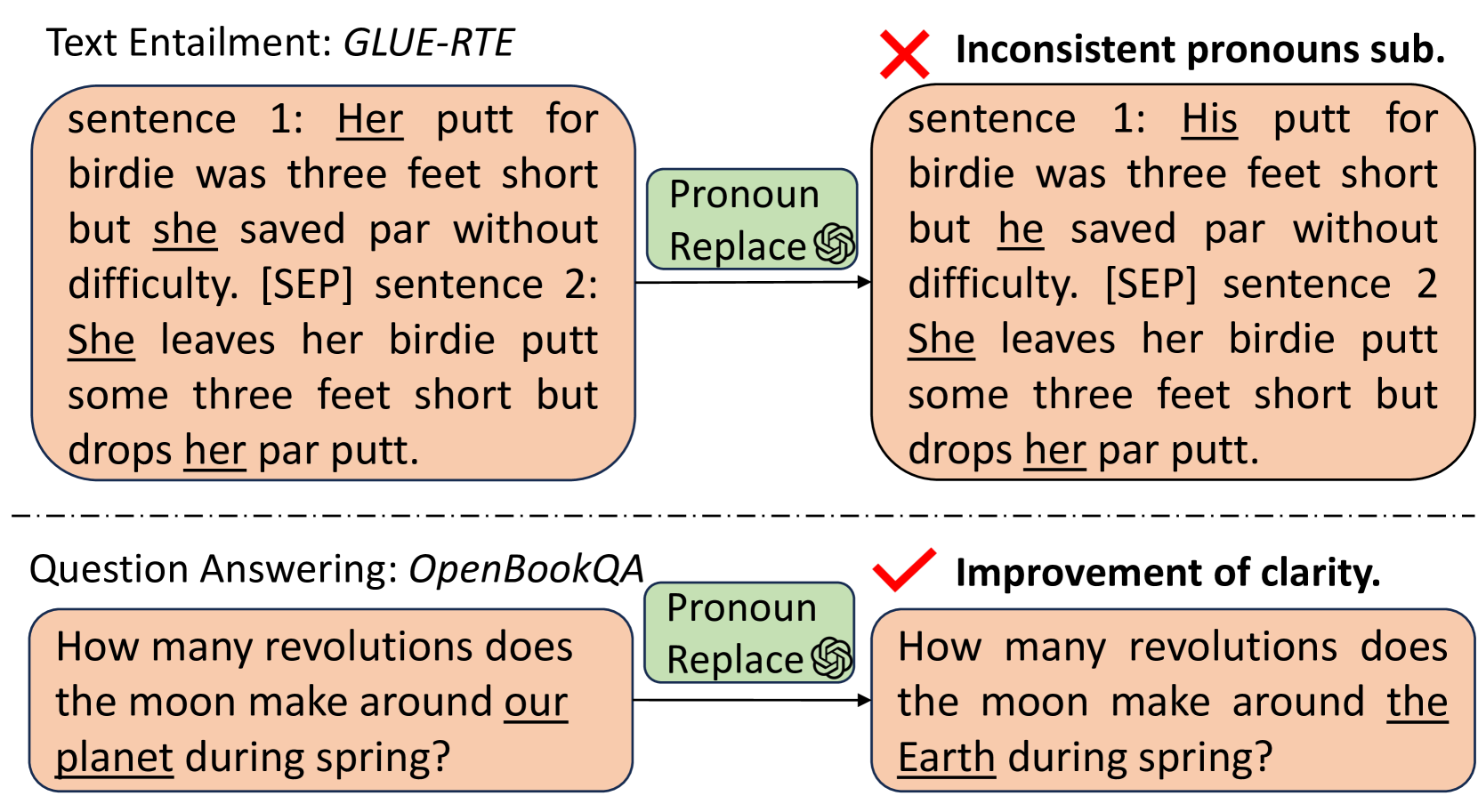
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024