Large Language Models on Fine-grained Emotion Detection Dataset with Data Augmentation and Transfer Learning
2403.06108
0
0

Abstract
This paper delves into enhancing the classification performance on the GoEmotions dataset, a large, manually annotated dataset for emotion detection in text. The primary goal of this paper is to address the challenges of detecting subtle emotions in text, a complex issue in Natural Language Processing (NLP) with significant practical applications. The findings offer valuable insights into addressing the challenges of emotion detection in text and suggest directions for future research, including the potential for a survey paper that synthesizes methods and performances across various datasets in this domain.
Create account to get full access
Overview
- Examines the use of large language models for fine-grained emotion detection
- Explores data augmentation and transfer learning techniques to improve model performance
- Compares the effectiveness of different language models on an emotion detection dataset
Plain English Explanation
This research paper investigates the use of large language models, such as BERT and GPT-3, for the task of fine-grained emotion detection. Fine-grained emotion detection refers to the ability to identify subtle emotional states in text, such as annoyance, excitement, or remorse, rather than just broad categories like "positive" or "negative".
The researchers explore two key strategies to improve the performance of these language models on the emotion detection task: data augmentation and transfer learning. Data augmentation involves artificially expanding the training dataset by applying transformations to existing examples, such as paraphrasing or injecting noise. Transfer learning, on the other hand, involves using a model that has been pre-trained on a large general-purpose dataset and fine-tuning it on the specific emotion detection task.
By combining these techniques, the researchers aim to develop more accurate and robust emotion detection models, which could have applications in areas like customer service, mental health monitoring, and content moderation.
Technical Explanation
The researchers conducted experiments on a fine-grained emotion detection dataset, comparing the performance of several large language models, including BERT, GPT-3, and RoBERTa. They explored the use of data augmentation techniques, such as back-translation and word-level perturbation, to expand the training dataset and improve model generalization.
Additionally, the researchers investigated the effectiveness of transfer learning, where the language models were first pre-trained on large general-purpose datasets and then fine-tuned on the emotion detection task. This approach leverages the rich semantic and contextual knowledge captured by the pre-trained models, which can be further refined and specialized for the target task.
The results of the experiments showed that the combination of data augmentation and transfer learning led to significant improvements in the models' performance on the fine-grained emotion detection task, outperforming baseline models that did not use these techniques.
Critical Analysis
The paper presents a thorough investigation of the use of large language models for fine-grained emotion detection, and the proposed strategies of data augmentation and transfer learning appear to be effective in improving model performance. However, the researchers acknowledge certain limitations of their work.
One limitation is the reliance on a single emotion detection dataset, which may limit the generalizability of the findings. It would be valuable to evaluate the proposed techniques on a wider range of datasets and domains to better understand their broader applicability.
Additionally, the paper does not provide a detailed error analysis or discussion of the types of emotions that the models struggle to detect accurately. Understanding the specific challenges and limitations of the models could guide future research in improving their robustness and accuracy.
Furthermore, the paper does not explore the potential biases or fairness issues that may arise from the use of large language models, which are known to exhibit biases present in their training data. Addressing these concerns is crucial for the deployment of such models in real-world applications, especially those involving sensitive domains like mental health or content moderation.
Conclusion
This research paper presents a promising approach to leveraging large language models for fine-grained emotion detection, with the use of data augmentation and transfer learning techniques leading to significant performance improvements. The findings suggest that these strategies can help overcome the challenges associated with limited training data and the complexity of the emotion detection task.
The insights gained from this work could have important implications for various applications, such as customer service, mental health monitoring, and content moderation, where the ability to accurately detect and understand emotions in text can be crucial. However, the researchers acknowledge the need for further investigation to address the limitations and potential biases of the models, as well as their broader applicability across different datasets and domains.
Overall, this paper contributes to the ongoing efforts to develop more advanced and reliable emotion detection systems, which could have far-reaching impacts on various industries and applications that rely on understanding human sentiment and emotional states.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Augmenting emotion features in irony detection with Large language modeling
Yucheng Lin, Yuhan Xia, Yunfei Long
0
0
This study introduces a novel method for irony detection, applying Large Language Models (LLMs) with prompt-based learning to facilitate emotion-centric text augmentation. Traditional irony detection techniques typically fall short due to their reliance on static linguistic features and predefined knowledge bases, often overlooking the nuanced emotional dimensions integral to irony. In contrast, our methodology augments the detection process by integrating subtle emotional cues, augmented through LLMs, into three benchmark pre-trained NLP models - BERT, T5, and GPT-2 - which are widely recognized as foundational in irony detection. We assessed our method using the SemEval-2018 Task 3 dataset and observed substantial enhancements in irony detection capabilities.
4/23/2024
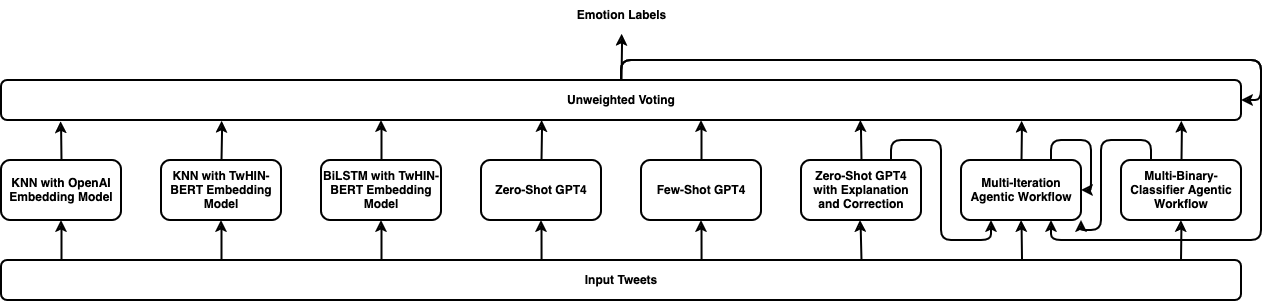
TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
Long Cheng, Qihao Shao, Christine Zhao, Sheng Bi, Gina-Anne Levow
0
0
Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
5/28/2024

Evaluating the Effectiveness of Data Augmentation for Emotion Classification in Low-Resource Settings
Aashish Arora, Elsbeth Turcan
0
0
Data augmentation has the potential to improve the performance of machine learning models by increasing the amount of training data available. In this study, we evaluated the effectiveness of different data augmentation techniques for a multi-label emotion classification task using a low-resource dataset. Our results showed that Back Translation outperformed autoencoder-based approaches and that generating multiple examples per training instance led to further performance improvement. In addition, we found that Back Translation generated the most diverse set of unigrams and trigrams. These findings demonstrate the utility of Back Translation in enhancing the performance of emotion classification models in resource-limited situations.
6/11/2024

Can Large Language Models Aid in Annotating Speech Emotional Data? Uncovering New Frontiers
Siddique Latif, Muhammad Usama, Mohammad Ibrahim Malik, Bjorn W. Schuller
0
0
Despite recent advancements in speech emotion recognition (SER) models, state-of-the-art deep learning (DL) approaches face the challenge of the limited availability of annotated data. Large language models (LLMs) have revolutionised our understanding of natural language, introducing emergent properties that broaden comprehension in language, speech, and vision. This paper examines the potential of LLMs to annotate abundant speech data, aiming to enhance the state-of-the-art in SER. We evaluate this capability across various settings using publicly available speech emotion classification datasets. Leveraging ChatGPT, we experimentally demonstrate the promising role of LLMs in speech emotion data annotation. Our evaluation encompasses single-shot and few-shots scenarios, revealing performance variability in SER. Notably, we achieve improved results through data augmentation, incorporating ChatGPT-annotated samples into existing datasets. Our work uncovers new frontiers in speech emotion classification, highlighting the increasing significance of LLMs in this field moving forward.
6/21/2024