Evaluating Fairness in Transaction Fraud Models: Fairness Metrics, Bias Audits, and Challenges

0
Sign in to get full access
Overview
- This paper evaluates fairness in transaction fraud detection models, examining fairness metrics, bias audits, and the challenges involved.
- It explores how to assess and mitigate algorithmic bias in these high-stakes models.
- Key topics include fairness definitions, bias measurement techniques, and the complex socio-technical factors impacting model fairness.
Plain English Explanation
This research paper focuses on the important issue of fairness in machine learning models used for transaction fraud detection. Fraud detection models play a critical role in financial services, helping to identify suspicious activity and prevent losses. However, there are growing concerns that these models may exhibit algorithmic bias, unfairly targeting or disadvantaging certain groups of people.
The researchers in this paper explore different ways to evaluate the fairness of these fraud detection models. They look at various fairness metrics that can be used to quantify bias, and describe how to conduct bias audits to identify potential issues.
Importantly, the paper highlights the complex, socio-technical nature of fairness in this domain. Fairness is not just a technical problem that can be solved with algorithms alone. Rather, it involves navigating tradeoffs, understanding the broader context, and addressing deep-rooted societal biases.
The key takeaway is that evaluating and ensuring fairness in high-stakes models like fraud detection requires a multifaceted approach. It involves carefully defining fairness, rigorously measuring bias, and grappling with the inherent challenges and tensions that arise.
Technical Explanation
The paper begins by outlining the importance of fairness in transaction fraud detection models. These models play a critical role in financial services, helping to identify suspicious activity and prevent losses. However, there are growing concerns that they may exhibit algorithmic bias, unfairly targeting or disadvantaging certain groups of people.
To address this issue, the researchers explore different ways to evaluate the fairness of fraud detection models. They review several fairness metrics, such as demographic parity, equal opportunity, and disparate impact, and discuss how to apply these metrics in the context of multivariate time series classification tasks.
The paper also describes a process for conducting bias audits of fraud detection models. This involves analyzing the model's performance across different demographic groups, identifying potential sources of bias, and exploring mitigation strategies.
Importantly, the researchers highlight the complex, socio-technical nature of fairness in this domain. Fairness is not just a technical problem that can be solved with algorithms alone. Rather, it involves navigating tradeoffs, understanding the broader context, and addressing deep-rooted societal biases.
The paper concludes by outlining several key challenges and areas for further research, such as the difficulty of defining fairness in the presence of imbalanced data and the need to consider the broader socio-technical factors that can influence model fairness.
Critical Analysis
The paper raises important considerations around the challenges of ensuring fairness in transaction fraud detection models. The researchers acknowledge the inherent tensions and tradeoffs involved, and the need to go beyond technical solutions to address the deeper socio-technical factors at play.
One key strength of the paper is its recognition that fairness is not a straightforward, one-size-fits-all concept. The authors explore multiple fairness definitions and metrics, highlighting the importance of carefully selecting the appropriate approach based on the specific context and goals.
However, the paper could have delved deeper into some of the practical challenges of implementing these fairness evaluations in real-world settings. For example, the authors mention the difficulty of dealing with imbalanced data, but more details on how this impacts fairness measurement and mitigation would be helpful.
Additionally, the paper could have provided more concrete examples or case studies to illustrate the key concepts and insights. This would help readers better understand the practical implications and trade-offs involved in ensuring fairness in high-stakes models like fraud detection.
Overall, this paper makes a valuable contribution to the growing body of research on algorithmic fairness, particularly in the context of financial services. By highlighting the complex, socio-technical nature of fairness in this domain, the authors encourage readers to think critically about the challenges and to pursue holistic, multifaceted solutions.
Conclusion
This research paper provides a comprehensive examination of the challenges involved in evaluating and ensuring fairness in transaction fraud detection models. The authors explore a range of fairness metrics, bias audit techniques, and the broader socio-technical factors that impact model fairness.
The key takeaway is that fairness in high-stakes models like fraud detection is a multifaceted issue that requires a nuanced, contextual approach. It involves carefully defining fairness, rigorously measuring bias, and navigating the inherent tensions and trade-offs that arise.
By highlighting these important considerations, the paper encourages researchers and practitioners to think critically about algorithmic fairness and to pursue holistic, interdisciplinary solutions that address the complex realities of real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Fairness in Transaction Fraud Models: Fairness Metrics, Bias Audits, and Challenges
Parameswaran Kamalaruban, Yulu Pi, Stuart Burrell, Eleanor Drage, Piotr Skalski, Jason Wong, David Sutton
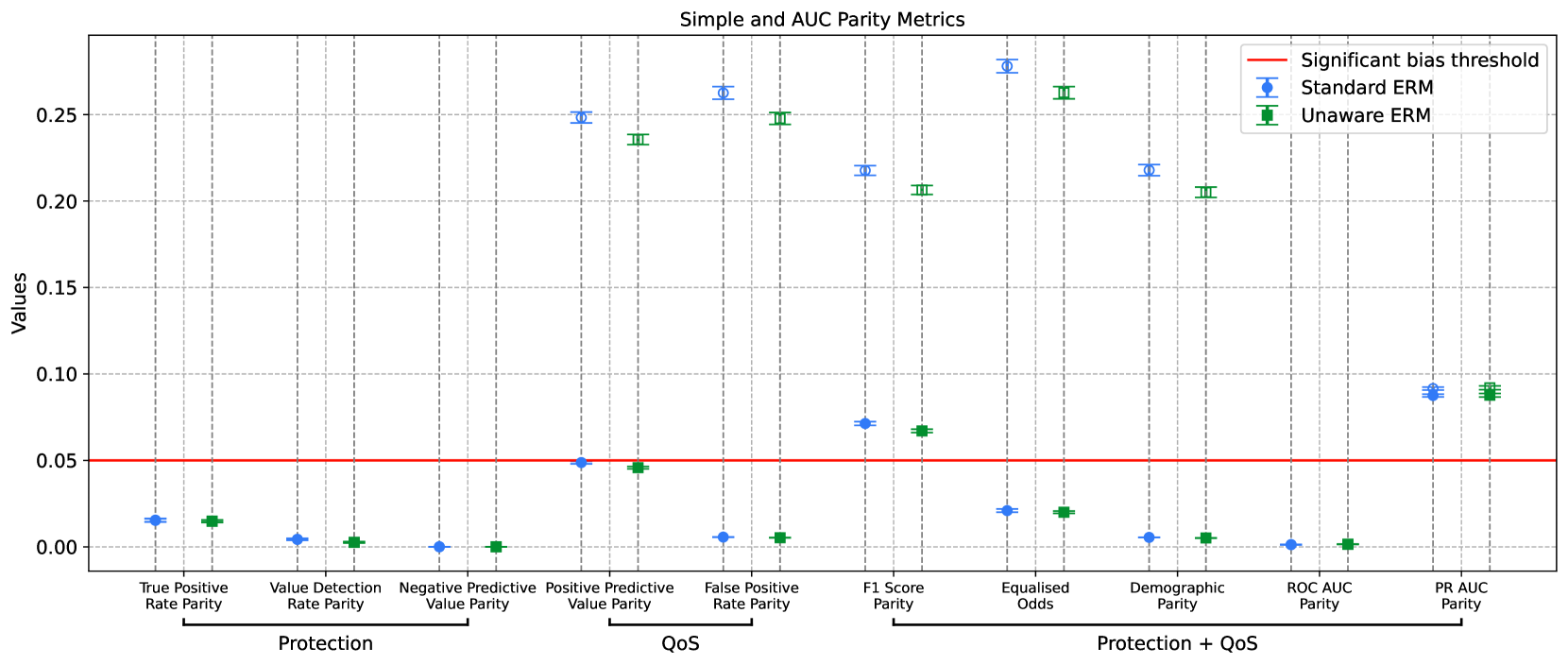
Ensuring fairness in transaction fraud detection models is vital due to the potential harms and legal implications of biased decision-making. Despite extensive research on algorithmic fairness, there is a notable gap in the study of bias in fraud detection models, mainly due to the field's unique challenges. These challenges include the need for fairness metrics that account for fraud data's imbalanced nature and the tradeoff between fraud protection and service quality. To address this gap, we present a comprehensive fairness evaluation of transaction fraud models using public synthetic datasets, marking the first algorithmic bias audit in this domain. Our findings reveal three critical insights: (1) Certain fairness metrics expose significant bias only after normalization, highlighting the impact of class imbalance. (2) Bias is significant in both service quality-related parity metrics and fraud protection-related parity metrics. (3) The fairness through unawareness approach, which involved removing sensitive attributes such as gender, does not improve bias mitigation within these datasets, likely due to the presence of correlated proxies. We also discuss socio-technical fairness-related challenges in transaction fraud models. These insights underscore the need for a nuanced approach to fairness in fraud detection, balancing protection and service quality, and moving beyond simple bias mitigation strategies. Future work must focus on refining fairness metrics and developing methods tailored to the unique complexities of the transaction fraud domain.
Read more9/9/2024

0
Thinking Racial Bias in Fair Forgery Detection: Models, Datasets and Evaluations
Decheng Liu, Zongqi Wang, Chunlei Peng, Nannan Wang, Ruimin Hu, Xinbo Gao
Due to the successful development of deep image generation technology, forgery detection plays a more important role in social and economic security. Racial bias has not been explored thoroughly in the deep forgery detection field. In the paper, we first contribute a dedicated dataset called the Fair Forgery Detection (FairFD) dataset, where we prove the racial bias of public state-of-the-art (SOTA) methods. Different from existing forgery detection datasets, the self-constructed FairFD dataset contains a balanced racial ratio and diverse forgery generation images with the largest-scale subjects. Additionally, we identify the problems with naive fairness metrics when benchmarking forgery detection models. To comprehensively evaluate fairness, we design novel metrics including Approach Averaged Metric and Utility Regularized Metric, which can avoid deceptive results. We also present an effective and robust post-processing technique, Bias Pruning with Fair Activations (BPFA), which improves fairness without requiring retraining or weight updates. Extensive experiments conducted with 12 representative forgery detection models demonstrate the value of the proposed dataset and the reasonability of the designed fairness metrics. By applying the BPFA to the existing fairest detector, we achieve a new SOTA. Furthermore, we conduct more in-depth analyses to offer more insights to inspire researchers in the community.
Read more9/4/2024
🌐
0
When mitigating bias is unfair: multiplicity and arbitrariness in algorithmic group fairness
Natasa Krco, Thibault Laugel, Vincent Grari, Jean-Michel Loubes, Marcin Detyniecki
Most research on fair machine learning has prioritized optimizing criteria such as Demographic Parity and Equalized Odds. Despite these efforts, there remains a limited understanding of how different bias mitigation strategies affect individual predictions and whether they introduce arbitrariness into the debiasing process. This paper addresses these gaps by exploring whether models that achieve comparable fairness and accuracy metrics impact the same individuals and mitigate bias in a consistent manner. We introduce the FRAME (FaiRness Arbitrariness and Multiplicity Evaluation) framework, which evaluates bias mitigation through five dimensions: Impact Size (how many people were affected), Change Direction (positive versus negative changes), Decision Rates (impact on models' acceptance rates), Affected Subpopulations (who was affected), and Neglected Subpopulations (where unfairness persists). This framework is intended to help practitioners understand the impacts of debiasing processes and make better-informed decisions regarding model selection. Applying FRAME to various bias mitigation approaches across key datasets allows us to exhibit significant differences in the behaviors of debiasing methods. These findings highlight the limitations of current fairness criteria and the inherent arbitrariness in the debiasing process.
Read more5/24/2024
0
An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases
Dylan Bouchard
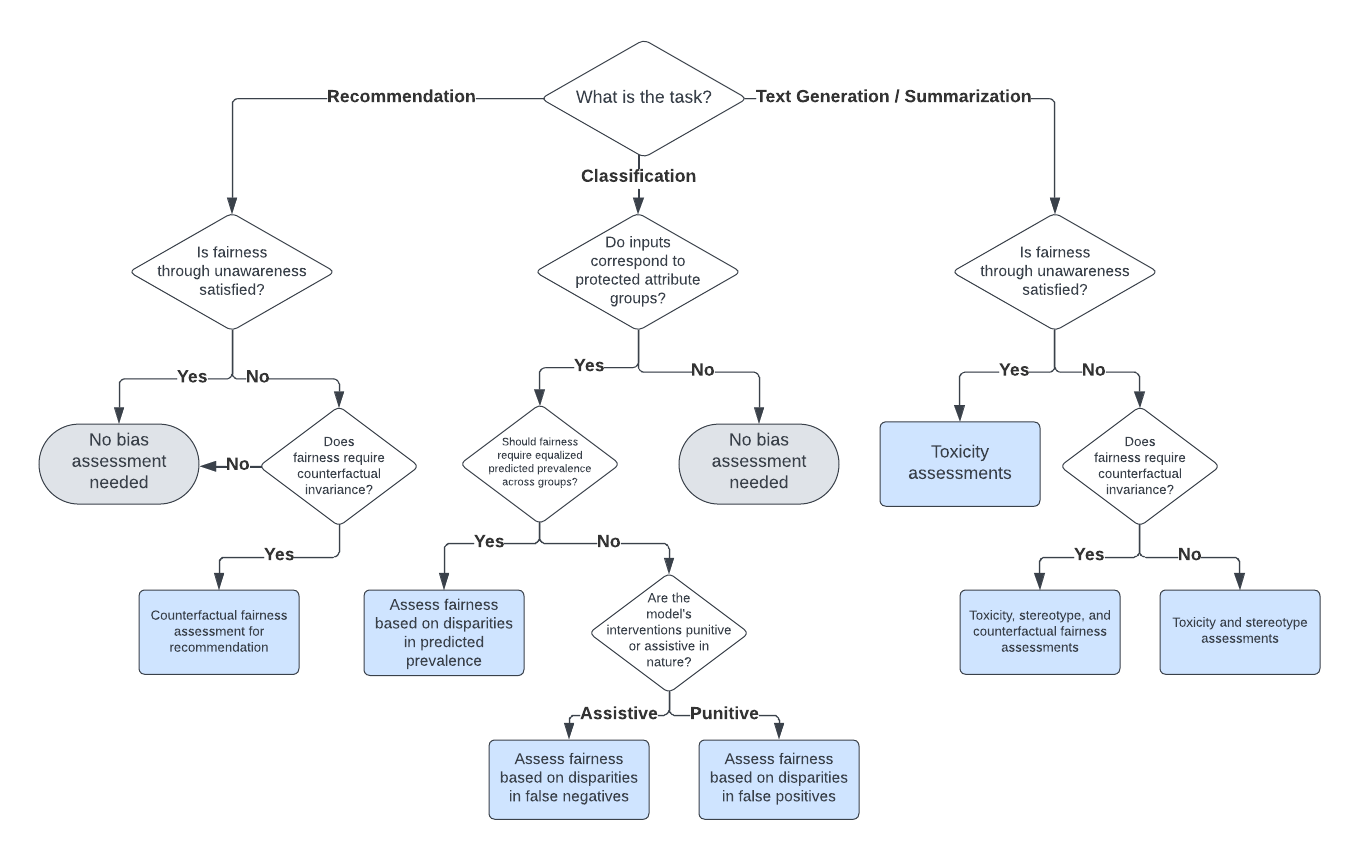
Large language models (LLMs) can exhibit bias in a variety of ways. Such biases can create or exacerbate unfair outcomes for certain groups within a protected attribute, including, but not limited to sex, race, sexual orientation, or age. This paper aims to provide a technical guide for practitioners to assess bias and fairness risks in LLM use cases. The main contribution of this work is a decision framework that allows practitioners to determine which metrics to use for a specific LLM use case. To achieve this, this study categorizes LLM bias and fairness risks, maps those risks to a taxonomy of LLM use cases, and then formally defines various metrics to assess each type of risk. As part of this work, several new bias and fairness metrics are introduced, including innovative counterfactual metrics as well as metrics based on stereotype classifiers. Instead of focusing solely on the model itself, the sensitivity of both prompt-risk and model-risk are taken into account by defining evaluations at the level of an LLM use case, characterized by a model and a population of prompts. Furthermore, because all of the evaluation metrics are calculated solely using the LLM output, the proposed framework is highly practical and easily actionable for practitioners.
Read more8/9/2024