An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases

0
Sign in to get full access
Overview
- This paper presents an actionable framework for assessing bias and fairness in the use of large language models (LLMs).
- The framework provides a structured approach to identify and mitigate potential biases and fairness issues in LLM-based applications.
- It covers key steps, including scoping the use case, auditing for biases, and developing mitigation strategies.
- The framework is designed to be flexible and adaptable to different LLM use cases, from natural language processing to content generation.
Plain English Explanation
The paper outlines a practical guide for evaluating and addressing potential biases and fairness concerns when using large language models (LLMs) in real-world applications. LLMs are powerful AI systems that can generate human-like text, but they can also reflect and amplify societal biases present in the data used to train them.
The proposed framework breaks down the process into key steps, making it easier for organizations to systematically identify and mitigate these issues. It starts by clearly defining the intended use case for the LLM, then audits the system for various types of biases, such as stereotyping or demographic biases. Finally, the framework suggests strategies to address any problems found, such as adjusting the training data or modifying the model's architecture.
The goal is to help organizations ensure their use of LLMs is ethical and fair, without compromising the technology's powerful capabilities. By proactively addressing bias and fairness issues, the framework aims to build trust in LLM-powered applications and mitigate potential harms to individuals or communities.
Technical Explanation
The paper presents a comprehensive framework for assessing bias and fairness in large language model (LLM) use cases. The framework consists of three main steps:
-
Scoping the Use Case: This involves clearly defining the intended purpose and context of the LLM application, including the target users, the expected outputs, and any relevant regulatory or ethical considerations.
-
Auditing for Biases: The framework guides users through a thorough audit of the LLM for various types of biases, such as stereotyping, demographic biases, and intersectional biases. This involves testing the model's outputs across a diverse range of inputs and evaluating the fairness and consistency of the results.
-
Developing Mitigation Strategies: Based on the bias audit, the framework guides users in developing appropriate mitigation strategies. These can include adjusting the training data, modifying the model's architecture, or implementing post-processing techniques to debias the model's outputs.
The authors emphasize the importance of ongoing monitoring and evaluation to ensure the continued fairness of the LLM-powered application over time. They also highlight the need for interdisciplinary collaboration between domain experts, ethicists, and AI researchers to effectively address these complex challenges.
Critical Analysis
The proposed framework is a valuable contribution to the growing field of responsible AI development, as it provides a structured approach to identifying and mitigating bias and fairness issues in LLM use cases. The authors acknowledge the inherent complexity of these challenges, noting that there is no one-size-fits-all solution.
One potential limitation of the framework is its reliance on human auditors to evaluate the LLM's outputs for biases. While the framework provides guidance on how to conduct these audits, the process may be time-consuming and subject to individual biases or oversights. Automated bias detection tools could potentially enhance the efficiency and objectivity of this step.
Additionally, the framework focuses on the assessment and mitigation of biases, but it does not provide detailed guidance on how to prioritize and balance different fairness considerations, which can sometimes be in tension with one another. Further research and practical case studies may be needed to help organizations navigate these trade-offs effectively.
Overall, the framework presented in this paper represents a significant step forward in addressing the critical challenge of ensuring the responsible and ethical deployment of large language models. By providing a structured, actionable approach, the authors have laid the groundwork for more widespread adoption of bias and fairness assessments in the development of LLM-powered applications.
Conclusion
The paper introduces a comprehensive framework for assessing and mitigating bias and fairness risks in the use of large language models (LLMs). By breaking down the process into clear steps, the framework empowers organizations to systematically identify and address potential biases, ensuring their LLM-powered applications are more equitable and trustworthy.
The framework's emphasis on ongoing monitoring and interdisciplinary collaboration underscores the importance of proactively managing the ethical and societal implications of these powerful AI systems. As the use of LLMs continues to expand across various domains, this framework can serve as a valuable tool for organizations committed to responsible and inclusive AI development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases
Dylan Bouchard
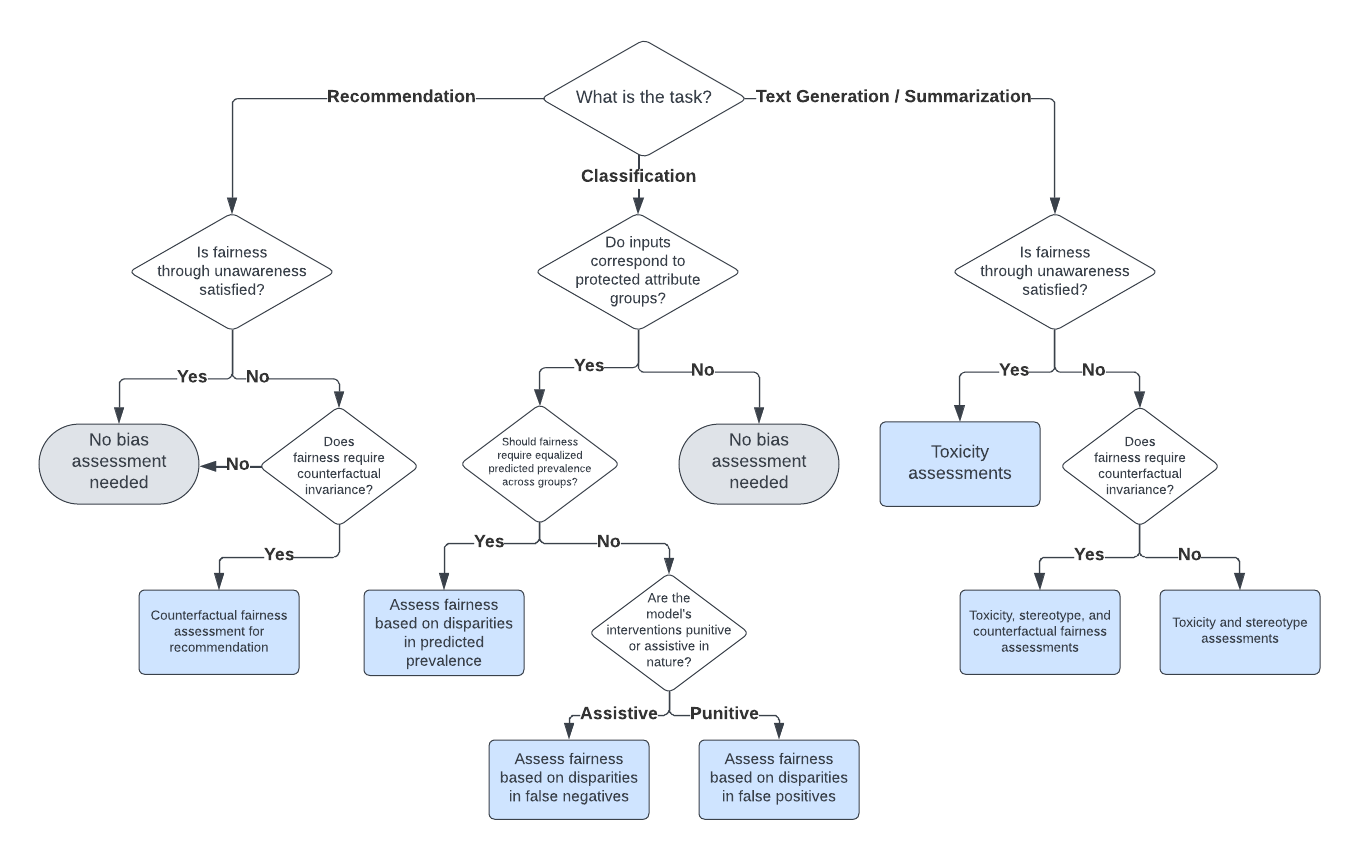
Large language models (LLMs) can exhibit bias in a variety of ways. Such biases can create or exacerbate unfair outcomes for certain groups within a protected attribute, including, but not limited to sex, race, sexual orientation, or age. This paper aims to provide a technical guide for practitioners to assess bias and fairness risks in LLM use cases. The main contribution of this work is a decision framework that allows practitioners to determine which metrics to use for a specific LLM use case. To achieve this, this study categorizes LLM bias and fairness risks, maps those risks to a taxonomy of LLM use cases, and then formally defines various metrics to assess each type of risk. As part of this work, several new bias and fairness metrics are introduced, including innovative counterfactual metrics as well as metrics based on stereotype classifiers. Instead of focusing solely on the model itself, the sensitivity of both prompt-risk and model-risk are taken into account by defining evaluations at the level of an LLM use case, characterized by a model and a population of prompts. Furthermore, because all of the evaluation metrics are calculated solely using the LLM output, the proposed framework is highly practical and easily actionable for practitioners.
Read more8/9/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
💬
0
Fairness in Large Language Models in Three Hour
Thang Doan Viet, Zichong Wang, Minh Nhat Nguyen, Wenbin Zhang
Large Language Models (LLMs) have demonstrated remarkable success across various domains but often lack fairness considerations, potentially leading to discriminatory outcomes against marginalized populations. Unlike fairness in traditional machine learning, fairness in LLMs involves unique backgrounds, taxonomies, and fulfillment techniques. This tutorial provides a systematic overview of recent advances in the literature concerning fair LLMs, beginning with real-world case studies to introduce LLMs, followed by an analysis of bias causes therein. The concept of fairness in LLMs is then explored, summarizing the strategies for evaluating bias and the algorithms designed to promote fairness. Additionally, resources for assessing bias in LLMs, including toolkits and datasets, are compiled, and current research challenges and open questions in the field are discussed. The repository is available at url{https://github.com/LavinWong/Fairness-in-Large-Language-Models}.
Read more8/6/2024
💬
0
Fairness in Large Language Models: A Taxonomic Survey
Zhibo Chu, Zichong Wang, Wenbin Zhang
Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
Read more4/3/2024