Evaluating language models as risk scores

0

Sign in to get full access
Overview
- The paper evaluates how well language models can be used as risk scores for various applications.
- It explores the model's ability to predict risk-related outcomes, such as financial risk and cybersecurity threats.
- The research aims to provide a framework for assessing the reliability and safety of large language models for real-world risk-related tasks.
Plain English Explanation
The research paper examines how well large language models can be used to assess and predict different types of risk, such as financial risk or cybersecurity threats. The researchers wanted to understand if these powerful AI models, which are trained on vast amounts of text data, could be leveraged to identify and quantify risk-related outcomes.
To do this, the researchers designed a series of experiments to test the model's ability to generate "risk scores" - numerical values that indicate the level of risk associated with a particular input or scenario. They evaluated the models on a range of risk-related tasks, including predicting financial defaults, detecting cybersecurity vulnerabilities, and assessing the safety and reliability of language models themselves.
The key finding was that language models can indeed provide useful risk scores, but their performance varies depending on the specific task and the way the model is used. In some cases, the models were quite accurate at predicting risk, while in others, they struggled to capture the nuances and complexities of real-world risk scenarios.
The researchers conclude that language models have significant potential for risk-related applications, but also highlight the importance of carefully evaluating their limitations and potential biases. They provide a framework for assessing the reliability and safety of these models, which could help guide their responsible development and deployment in high-stakes domains.
Technical Explanation
The paper presents a comprehensive evaluation of large language models as risk scoring systems. The researchers developed a set of benchmarks to assess the models' ability to generate reliable risk scores across a variety of domains, including financial risk, cybersecurity threats, and the risk posed by the language models themselves.
To test the models, the researchers curated datasets related to financial defaults, cybersecurity vulnerabilities, and language model safety. They then fine-tuned large language models (such as GPT-3) on these datasets and evaluated the models' ability to generate risk scores that accurately reflected the true level of risk.
The key findings were:
- Financial Risk: The language models were able to generate risk scores that were predictive of financial defaults, outperforming traditional credit scoring methods in some cases.
- Cybersecurity Risk: The models demonstrated the ability to identify cybersecurity vulnerabilities and assess the risk of potential attacks, though their performance was more modest compared to financial risk.
- Language Model Risk: The researchers also developed benchmarks to assess the safety and reliability of the language models themselves, identifying potential risks such as the generation of harmful or biased content.
The paper provides a comprehensive framework for evaluating language models as risk scoring systems, including guidelines for dataset curation, model fine-tuning, and performance evaluation. The researchers argue that this approach can help guide the responsible development and deployment of these powerful AI models in high-stakes applications.
Critical Analysis
The paper presents a well-designed and thorough evaluation of language models as risk scoring systems. The researchers have done an admirable job of identifying key risk-related domains and developing appropriate benchmarks to assess the models' performance.
One potential limitation of the study is the reliance on a relatively small set of datasets, which may not fully capture the complexity and diversity of real-world risk scenarios. Additionally, the researchers acknowledge that the language models' performance can be heavily influenced by the way they are fine-tuned and deployed, suggesting the need for further research on best practices for model development and deployment.
Another area for further exploration is the potential biases and limitations of the language models themselves. While the researchers have assessed the models' safety and reliability, it is important to continue investigating the potential for these models to perpetuate or amplify societal biases, particularly in high-stakes applications like risk assessment.
Overall, the paper provides a valuable framework for evaluating language models as risk scoring systems, and the findings have important implications for the responsible development and deployment of these powerful AI tools in real-world applications.
Conclusion
This research paper presents a comprehensive evaluation of large language models as risk scoring systems, exploring their potential for a range of applications, including financial risk assessment, cybersecurity threat detection, and the models' own safety and reliability.
The key findings suggest that language models can generate useful risk scores, but their performance varies depending on the specific task and how they are deployed. The researchers provide a framework for assessing the reliability and safety of these models, which could help guide their responsible development and deployment in high-stakes domains.
Overall, this work represents an important step forward in understanding the capabilities and limitations of language models for risk-related applications, and it highlights the need for continued research and careful evaluation to ensure these powerful AI tools are used in a safe and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating language models as risk scores
Andr'e F. Cruz, Moritz Hardt, Celestine Mendler-Dunner
Current question-answering benchmarks predominantly focus on accuracy in realizable prediction tasks. Conditioned on a question and answer-key, does the most likely token match the ground truth? Such benchmarks necessarily fail to evaluate language models' ability to quantify outcome uncertainty. In this work, we focus on the use of language models as risk scores for unrealizable prediction tasks. We introduce folktexts, a software package to systematically generate risk scores using large language models, and evaluate them against benchmark prediction tasks. Specifically, the package derives natural language tasks from US Census data products, inspired by popular tabular data benchmarks. A flexible API allows for any task to be constructed out of 28 census features whose values are mapped to prompt-completion pairs. We demonstrate the utility of folktexts through a sweep of empirical insights on 16 recent large language models, inspecting risk scores, calibration curves, and diverse evaluation metrics. We find that zero-shot risk sores have high predictive signal while being widely miscalibrated: base models overestimate outcome uncertainty, while instruction-tuned models underestimate uncertainty and generate over-confident risk scores.
Read more7/23/2024

0
Risk Aware Benchmarking of Large Language Models
Apoorva Nitsure, Youssef Mroueh, Mattia Rigotti, Kristjan Greenewald, Brian Belgodere, Mikhail Yurochkin, Jiri Navratil, Igor Melnyk, Jerret Ross
We propose a distributional framework for benchmarking socio-technical risks of foundation models with quantified statistical significance. Our approach hinges on a new statistical relative testing based on first and second order stochastic dominance of real random variables. We show that the second order statistics in this test are linked to mean-risk models commonly used in econometrics and mathematical finance to balance risk and utility when choosing between alternatives. Using this framework, we formally develop a risk-aware approach for foundation model selection given guardrails quantified by specified metrics. Inspired by portfolio optimization and selection theory in mathematical finance, we define a metrics portfolio for each model as a means to aggregate a collection of metrics, and perform model selection based on the stochastic dominance of these portfolios. The statistical significance of our tests is backed theoretically by an asymptotic analysis via central limit theorems instantiated in practice via a bootstrap variance estimate. We use our framework to compare various large language models regarding risks related to drifting from instructions and outputting toxic content.
Read more6/11/2024
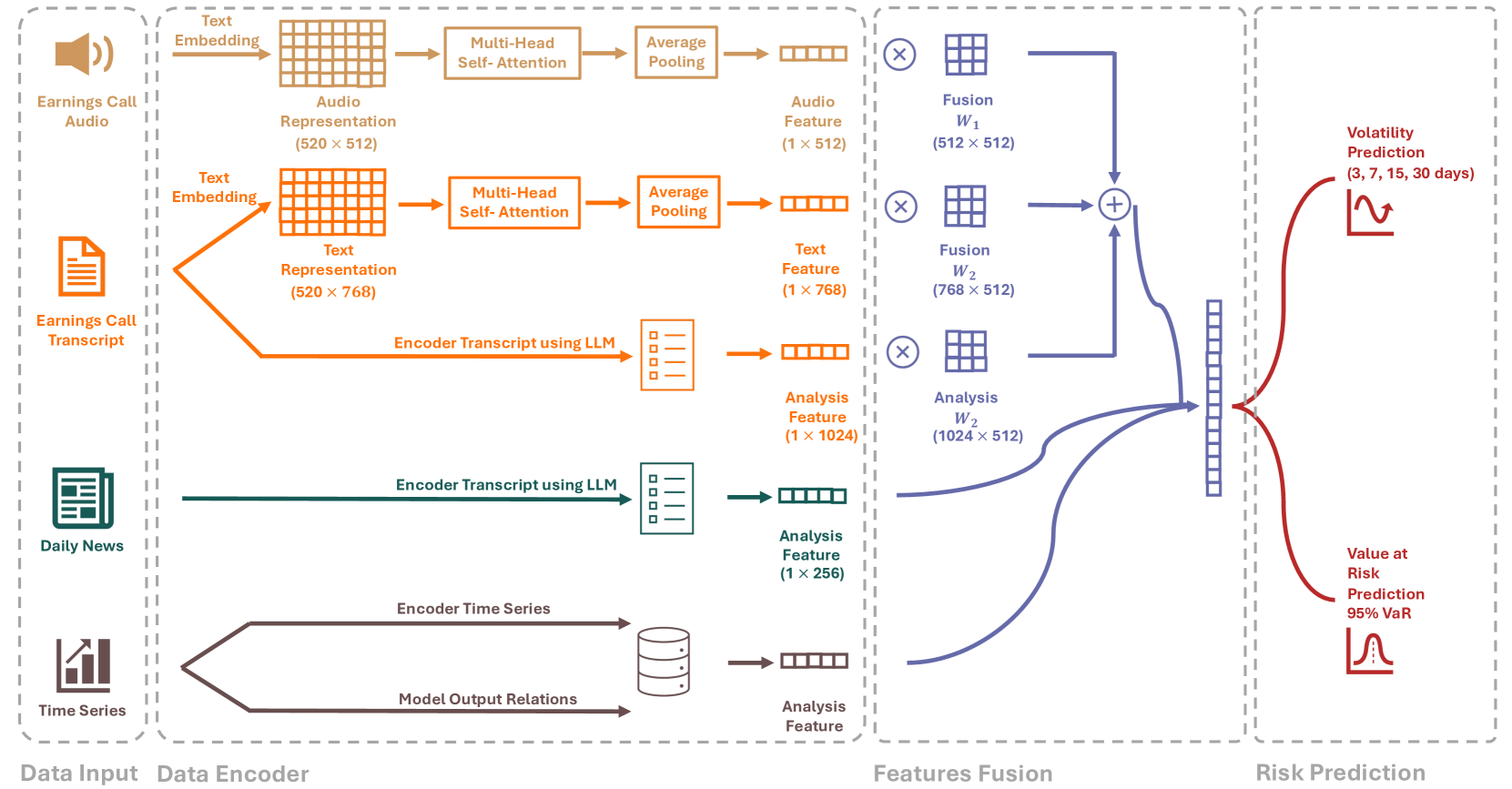
0
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data
Yupeng Cao, Zhi Chen, Qingyun Pei, Fabrizio Dimino, Lorenzo Ausiello, Prashant Kumar, K. P. Subbalakshmi, Papa Momar Ndiaye
The integration of Artificial Intelligence (AI) techniques, particularly large language models (LLMs), in finance has garnered increasing academic attention. Despite progress, existing studies predominantly focus on tasks like financial text summarization, question-answering (Q$&$A), and stock movement prediction (binary classification), with a notable gap in the application of LLMs for financial risk prediction. Addressing this gap, in this paper, we introduce textbf{RiskLabs}, a novel framework that leverages LLMs to analyze and predict financial risks. RiskLabs uniquely combines different types of financial data, including textual and vocal information from Earnings Conference Calls (ECCs), market-related time series data, and contextual news data surrounding ECC release dates. Our approach involves a multi-stage process: initially extracting and analyzing ECC data using LLMs, followed by gathering and processing time-series data before the ECC dates to model and understand risk over different timeframes. Using multimodal fusion techniques, RiskLabs amalgamates these varied data features for comprehensive multi-task financial risk prediction. Empirical experiment results demonstrate RiskLab's effectiveness in forecasting both volatility and variance in financial markets. Through comparative experiments, we demonstrate how different data sources contribute to financial risk assessment and discuss the critical role of LLMs in this context. Our findings not only contribute to the AI in finance application but also open new avenues for applying LLMs in financial risk assessment.
Read more4/12/2024
💬
0
Beyond Words: On Large Language Models Actionability in Mission-Critical Risk Analysis
Matteo Esposito, Francesco Palagiano, Valentina Lenarduzzi, Davide Taibi
Context. Risk analysis assesses potential risks in specific scenarios. Risk analysis principles are context-less; the same methodology can be applied to a risk connected to health and information technology security. Risk analysis requires a vast knowledge of national and international regulations and standards and is time and effort-intensive. A large language model can quickly summarize information in less time than a human and can be fine-tuned to specific tasks. Aim. Our empirical study aims to investigate the effectiveness of Retrieval-Augmented Generation and fine-tuned LLM in risk analysis. To our knowledge, no prior study has explored its capabilities in risk analysis. Method. We manually curated 193 unique scenarios leading to 1283 representative samples from over 50 mission-critical analyses archived by the industrial context team in the last five years. We compared the base GPT-3.5 and GPT-4 models versus their Retrieval-Augmented Generation and fine-tuned counterparts. We employ two human experts as competitors of the models and three other human experts to review the models and the former human experts' analysis. The reviewers analyzed 5,000 scenario analyses. Results and Conclusions. Human experts demonstrated higher accuracy, but LLMs are quicker and more actionable. Moreover, our findings show that RAG-assisted LLMs have the lowest hallucination rates, effectively uncovering hidden risks and complementing human expertise. Thus, the choice of model depends on specific needs, with FTMs for accuracy, RAG for hidden risks discovery, and base models for comprehensiveness and actionability. Therefore, experts can leverage LLMs as an effective complementing companion in risk analysis within a condensed timeframe. They can also save costs by averting unnecessary expenses associated with implementing unwarranted countermeasures.
Read more9/10/2024