Evaluating Large Language Models Using Contrast Sets: An Experimental Approach
2404.01569
0
0
💬
Abstract
In the domain of Natural Language Inference (NLI), especially in tasks involving the classification of multiple input texts, the Cross-Entropy Loss metric is widely employed as a standard for error measurement. However, this metric falls short in effectively evaluating a model's capacity to understand language entailments. In this study, we introduce an innovative technique for generating a contrast set for the Stanford Natural Language Inference (SNLI) dataset. Our strategy involves the automated substitution of verbs, adverbs, and adjectives with their synonyms to preserve the original meaning of sentences. This method aims to assess whether a model's performance is based on genuine language comprehension or simply on pattern recognition. We conducted our analysis using the ELECTRA-small model. The model achieved an accuracy of 89.9% on the conventional SNLI dataset but showed a reduced accuracy of 72.5% on our contrast set, indicating a substantial 17% decline. This outcome led us to conduct a detailed examination of the model's learning behaviors. Following this, we improved the model's resilience by fine-tuning it with a contrast-enhanced training dataset specifically designed for SNLI, which increased its accuracy to 85.5% on the contrast sets. Our findings highlight the importance of incorporating diverse linguistic expressions into datasets for NLI tasks. We hope that our research will encourage the creation of more inclusive datasets, thereby contributing to the development of NLI models that are both more sophisticated and effective.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers introduce a new technique for generating a "contrast set" to evaluate natural language inference (NLI) models
- They find that a popular NLI model performs well on a standard dataset, but struggles on the contrast set
- The researchers then fine-tune the model using the contrast set, improving its performance
Plain English Explanation
Understanding language is a core challenge in artificial intelligence. One important task is natural language inference (NLI), where an AI system must determine if one sentence logically follows from another.
Researchers often use a popular dataset called SNLI to train and test NLI models. However, the standard way of evaluating these models, using a metric called "cross-entropy loss," doesn't fully capture how well the models truly understand language.
The researchers in this study came up with a clever way to create "contrast sets" - slightly modified versions of the SNLI sentences that preserve the original meaning. For example, they might replace a verb with a synonym. This tests whether the model is just memorizing patterns, or actually comprehending the language.
When they tested a popular NLI model on these contrast sets, its performance dropped significantly - from 90% accuracy on the standard dataset down to only 72.5%. This revealed limitations in the model's understanding.
To address this, the researchers fine-tuned the model using the contrast sets during training. This boosted its performance back up to 85.5% on the contrast tasks, showing it had become more robust.
The key insight is that standard datasets may not fully capture the complexities of language. By creating more diverse datasets with subtle linguistic variations, researchers can build AI systems that truly understand, rather than just recognize, natural language.
Technical Explanation
The paper focuses on evaluating natural language inference (NLI) models, which aim to determine if one sentence logically follows from another. The authors note that the commonly used cross-entropy loss metric does not adequately assess a model's capacity for genuine language understanding.
To address this, the researchers developed a technique to automatically generate "contrast sets" for the Stanford Natural Language Inference (SNLI) dataset. Their approach involves substituting verbs, adverbs, and adjectives in the SNLI sentences with synonyms, preserving the original meaning.
They tested the ELECTRA-small NLI model on both the standard SNLI dataset and their newly created contrast sets. The model achieved 89.9% accuracy on the standard dataset but only 72.5% on the contrast sets, a significant 17% drop.
Further analysis revealed insights into the model's learning behaviors. To improve its robustness, the researchers fine-tuned the ELECTRA-small model using a contrast-enhanced training dataset. This increased the model's accuracy on the contrast sets to 85.5%.
The authors argue that incorporating more diverse linguistic expressions into NLI datasets is crucial for developing models with genuine language comprehension, rather than just pattern recognition. They hope their work will inspire the creation of more inclusive datasets and lead to the development of more sophisticated and effective NLI models.
Critical Analysis
The researchers present a compelling approach to evaluating NLI models, highlighting the limitations of relying solely on standard dataset performance metrics. Their contrast set generation technique is a clever and systematic way to probe the models' true language understanding capabilities.
However, the authors acknowledge that their contrast sets may not capture the full breadth of linguistic variability. Additionally, the fine-tuning process, while effective, may not be scalable or practical for real-world deployment. Further research is needed to explore more efficient ways of improving model robustness.
It would also be valuable to see how other NLI models, beyond just ELECTRA-small, perform on the contrast sets. Applying this evaluation method to a wider range of architectures could provide deeper insights into the strengths and weaknesses of different approaches to natural language understanding.
Overall, this study underscores the importance of moving beyond simplistic benchmark scores and toward more nuanced assessments of language AI systems. Continued work in this direction has the potential to drive meaningful advancements in the field.
Conclusion
This research demonstrates the limitations of existing approaches to evaluating natural language inference models. By introducing a novel contrast set generation technique, the authors were able to uncover significant shortcomings in a popular NLI model's performance, despite its strong results on a standard benchmark.
The findings highlight the crucial need for more diverse and linguistically sophisticated datasets to assess the true language understanding capabilities of AI systems. Through fine-tuning on the contrast-enhanced data, the researchers showed it is possible to improve model robustness, paving the way for the development of more sophisticated and effective natural language processing technologies.
As the field of AI continues to advance, studies like this one will be instrumental in guiding the creation of language models that can genuinely comprehend and reason about human communication, rather than simply pattern-match. Ultimately, this work represents an important step towards building AI systems that can interact with us in more natural and meaningful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Customizing Language Model Responses with Contrastive In-Context Learning
Xiang Gao, Kamalika Das
0
0
Large language models (LLMs) are becoming increasingly important for machine learning applications. However, it can be challenging to align LLMs with our intent, particularly when we want to generate content that is preferable over others or when we want the LLM to respond in a certain style or tone that is hard to describe. To address this challenge, we propose an approach that uses contrastive examples to better describe our intent. This involves providing positive examples that illustrate the true intent, along with negative examples that show what characteristics we want LLMs to avoid. The negative examples can be retrieved from labeled data, written by a human, or generated by the LLM itself. Before generating an answer, we ask the model to analyze the examples to teach itself what to avoid. This reasoning step provides the model with the appropriate articulation of the user's need and guides it towards generting a better answer. We tested our approach on both synthesized and real-world datasets, including StackExchange and Reddit, and found that it significantly improves performance compared to standard few-shot prompting
4/9/2024

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024
💬
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
Fatema Tuj Johora Faria, Mukaffi Bin Moin, Asif Iftekher Fahim, Pronay Debnath, Faisal Muhammad Shah
0
0
Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled entailment. If the hypothesis contradicts the premise, the pair receives the contradiction label. When there is insufficient evidence to establish a connection, the pair is described as neutral. Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.
5/8/2024
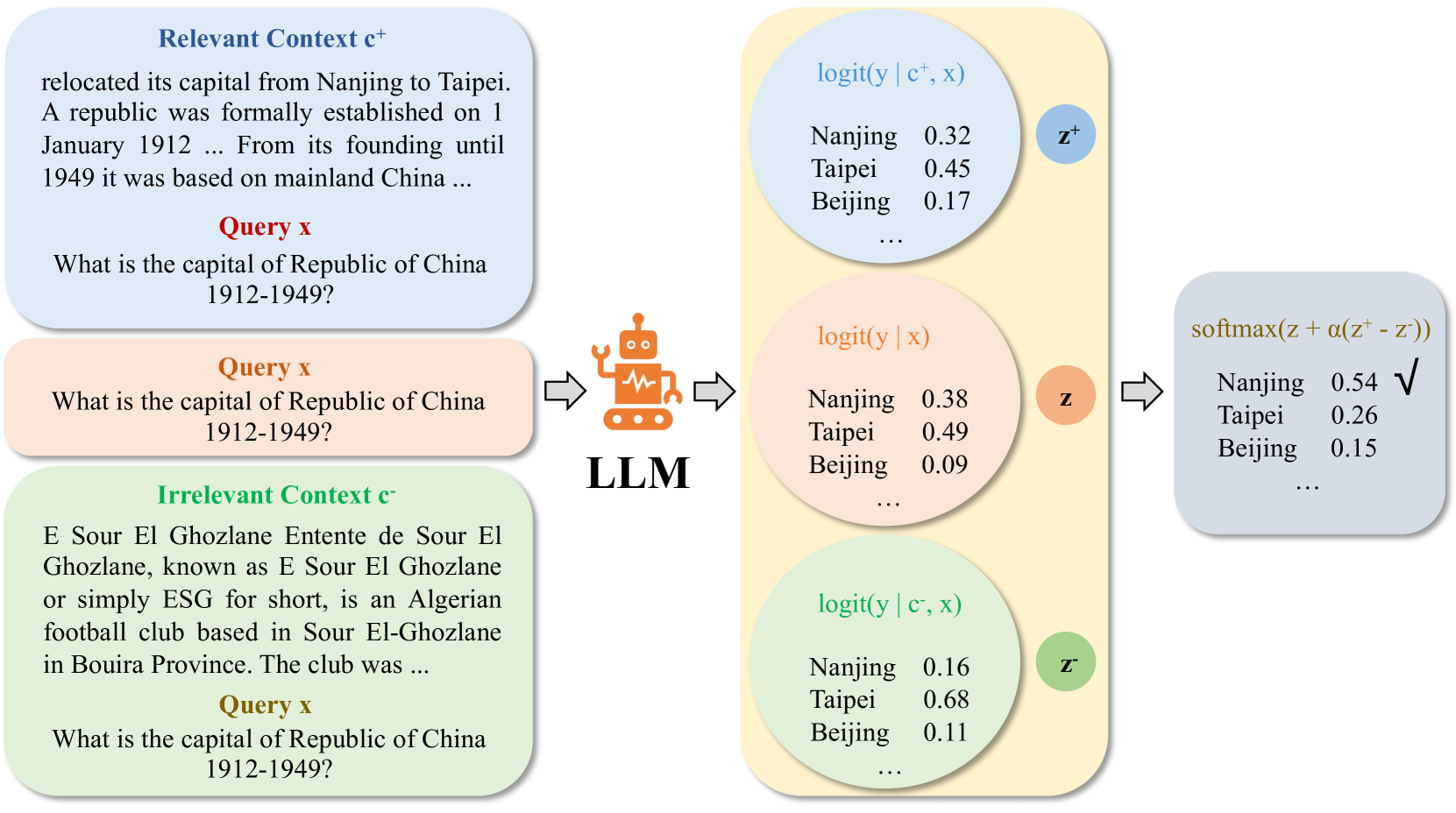
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
0
0
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
5/7/2024