Evaluating Speaker Identity Coding in Self-supervised Models and Humans
2406.10401
0
0
👨🏫
Abstract
Speaker identity plays a significant role in human communication and is being increasingly used in societal applications, many through advances in machine learning. Speaker identity perception is an essential cognitive phenomenon that can be broadly reduced to two main tasks: recognizing a voice or discriminating between voices. Several studies have attempted to identify acoustic correlates of identity perception to pinpoint salient parameters for such a task. Unlike other communicative social signals, most efforts have yielded inefficacious conclusions. Furthermore, current neurocognitive models of voice identity processing consider the bases of perception as acoustic dimensions such as fundamental frequency, harmonics-to-noise ratio, and formant dispersion. However, these findings do not account for naturalistic speech and within-speaker variability. Representational spaces of current self-supervised models have shown significant performance in various speech-related tasks. In this work, we demonstrate that self-supervised representations from different families (e.g., generative, contrastive, and predictive models) are significantly better for speaker identification over acoustic representations. We also show that such a speaker identification task can be used to better understand the nature of acoustic information representation in different layers of these powerful networks. By evaluating speaker identification accuracy across acoustic, phonemic, prosodic, and linguistic variants, we report similarity between model performance and human identity perception. We further examine these similarities by juxtaposing the encoding spaces of models and humans and challenging the use of distance metrics as a proxy for speaker proximity. Lastly, we show that some models can predict brain responses in Auditory and Language regions during naturalistic stimuli.
Create account to get full access
Overview
- This paper investigates how different machine learning models perform on the task of speaker identification, and how their performance relates to human perception of speaker identity.
- The researchers explore acoustic, phonemic, prosodic, and linguistic features to better understand how machine models and humans process speaker identity information.
- They find that self-supervised representations from various model families (generative, contrastive, predictive) outperform traditional acoustic features for speaker identification.
- The paper also examines the similarities and differences between model performance and human perception of speaker identity.
Plain English Explanation
When we talk to someone, we don't just hear the words they say - we also perceive information about the speaker's identity, like who they are and what they sound like. This speaker identity plays a crucial role in human communication and is increasingly being used in various societal applications, often through advances in machine learning.
Recognizing a voice or distinguishing between different voices are two key tasks involved in perceiving speaker identity. Researchers have tried to identify the acoustic characteristics that contribute to this identity perception, but have generally struggled to find clear, consistent patterns.
Current models of how the brain processes voice information suggest it relies on things like pitch, noise levels, and formant frequencies. However, these models don't fully capture the complexity of real-world, natural speech, which can vary a lot even for the same speaker.
In this study, the researchers explored whether newer self-supervised machine learning models could do a better job of capturing speaker identity information compared to traditional acoustic features. Self-supervised learning models are trained on large datasets without direct supervision, allowing them to discover patterns on their own.
The researchers found that these self-supervised models, from different families like generative, contrastive, and predictive models, consistently outperformed traditional acoustic features at identifying speakers.
By analyzing how well the models and human listeners performed on different aspects of speaker identity (like accents, emotions, etc.), the researchers were able to gain insights into the underlying representation of speaker identity information in both machine models and the human brain. They found some interesting similarities and differences between the two.
Overall, this work sheds light on how machine learning models and the human brain process the crucial social cue of speaker identity, and opens up new avenues for understanding and potentially improving speech technologies.
Technical Explanation
The paper examines the ability of various machine learning models to perform speaker identification tasks, and how their performance relates to human perceptions of speaker identity. The researchers evaluated acoustic, phonemic, prosodic, and linguistic features to better understand how models and humans encode speaker identity information.
They found that self-supervised representations from generative, contrastive, and predictive machine learning models significantly outperformed traditional acoustic features for speaker identification. This suggests these models are better able to capture the complex, naturalistic patterns in speech that contribute to perceived speaker identity.
By comparing model performance to human listener performance on various aspects of speaker identity, the researchers observed some similarities and differences between machine and human processing of this information. For example, they found correlations between model and human performance on tasks like identifying speaker accent or emotion.
The researchers also looked at the encoding spaces of the models and compared them to measures of human perceptions of speaker proximity. This allowed them to investigate whether distance metrics in the model representations aligned with human judgments of how "close" different speakers sound.
Finally, the paper demonstrates that some of the self-supervised models can even predict brain activity in auditory and language regions when people listen to natural speech stimuli. This suggests these models may be capturing relevant representations of speech processing that are reflective of human neurocognitive mechanisms.
Overall, this work provides valuable insights into the nature of speaker identity processing in both machine learning models and the human brain. By bridging the gap between artificial and biological systems, it opens up new directions for improving speech technologies and understanding human communication.
Critical Analysis
The paper makes a strong case for the advantages of self-supervised machine learning models over traditional acoustic features for capturing speaker identity information. The researchers' comprehensive evaluation across various feature types and model architectures is a particular strength of the work.
However, the paper does not delve deeply into the specific mechanisms or representations within the self-supervised models that enable their superior performance. While the authors provide some analysis of the model encoding spaces, a more detailed examination of the learned features could further elucidate the underlying basis of speaker identity perception.
Additionally, the paper focuses primarily on speaker identification, which is an important but limited aspect of speaker identity processing. Extending the analysis to other relevant tasks, such as speaker diarization or emotion recognition, could provide a more holistic understanding of how machine models and humans process speaker-related information.
Some of the comparisons between model and human performance are intriguing, but the paper could benefit from a more thorough discussion of the potential reasons for the observed similarities and differences. Exploring potential confounding factors or alternative explanations for the patterns observed would strengthen the conclusions.
Finally, while the ability of some models to predict brain activity is an interesting finding, the paper could delve deeper into the implications and potential applications of this capability. Connecting these neural correlates to specific cognitive mechanisms or behavioral outcomes could further enhance the impact of this research.
Overall, this paper makes a valuable contribution to the understanding of speaker identity processing in both artificial and biological systems. Addressing the potential limitations and expanding the scope of the analysis could lead to even more impactful insights in this important area of speech and communication research.
Conclusion
This study demonstrates the power of self-supervised machine learning models for capturing the complex, naturalistic patterns that contribute to human perceptions of speaker identity. By outperforming traditional acoustic features on speaker identification tasks, these models suggest they are better able to represent the crucial social cues conveyed through a person's voice.
The researchers' comparative analysis of model and human performance provides intriguing insights into the similarities and differences between artificial and biological systems in processing speaker-related information. This work lays the groundwork for further exploring the neurocognitive mechanisms underlying speaker identity perception, with potential applications in improving speech technologies and understanding human communication.
Overall, this paper represents an important step forward in bridging the gap between machine learning and human cognition in the domain of speaker identity processing. By continuing to investigate these parallels, researchers can gain deeper insights into the fundamental nature of speech and voice perception, with far-reaching implications for both artificial intelligence and our understanding of the human mind.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

How Should We Extract Discrete Audio Tokens from Self-Supervised Models?
Pooneh Mousavi, Jarod Duret, Salah Zaiem, Luca Della Libera, Artem Ploujnikov, Cem Subakan, Mirco Ravanelli
0
0
Discrete audio tokens have recently gained attention for their potential to bridge the gap between audio and language processing. Ideal audio tokens must preserve content, paralinguistic elements, speaker identity, and many other audio details. Current audio tokenization methods fall into two categories: Semantic tokens, acquired through quantization of Self-Supervised Learning (SSL) models, and Neural compression-based tokens (codecs). Although previous studies have benchmarked codec models to identify optimal configurations, the ideal setup for quantizing pretrained SSL models remains unclear. This paper explores the optimal configuration of semantic tokens across discriminative and generative tasks. We propose a scalable solution to train a universal vocoder across multiple SSL layers. Furthermore, an attention mechanism is employed to identify task-specific influential layers, enhancing the adaptability and performance of semantic tokens in diverse audio applications.
6/18/2024
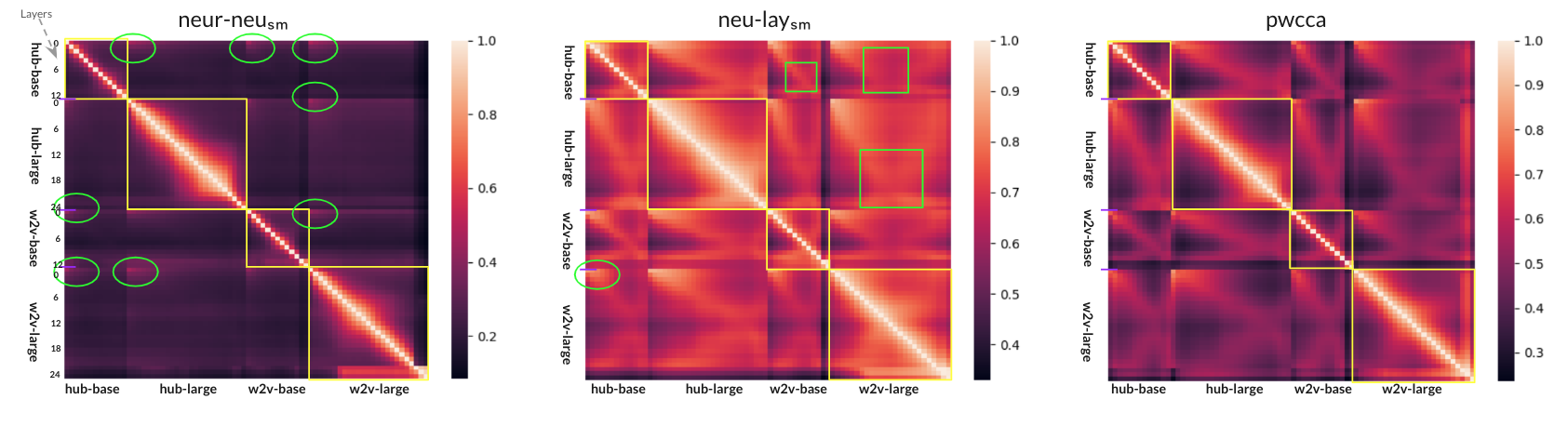
Speech Representation Analysis based on Inter- and Intra-Model Similarities
Yassine El Kheir, Ahmed Ali, Shammur Absar Chowdhury
0
0
Self-supervised models have revolutionized speech processing, achieving new levels of performance in a wide variety of tasks with limited resources. However, the inner workings of these models are still opaque. In this paper, we aim to analyze the encoded contextual representation of these foundation models based on their inter- and intra-model similarity, independent of any external annotation and task-specific constraint. We examine different SSL models varying their training paradigm -- Contrastive (Wav2Vec2.0) and Predictive models (HuBERT); and model sizes (base and large). We explore these models on different levels of localization/distributivity of information including (i) individual neurons; (ii) layer representation; (iii) attention weights and (iv) compare the representations with their finetuned counterparts.Our results highlight that these models converge to similar representation subspaces but not to similar neuron-localized conceptsfootnote{A concept represents a coherent fragment of knowledge, such as ``a class containing certain objects as elements, where the objects have certain properties. We made the code publicly available for facilitating further research, we publicly released our code.
6/26/2024

The Brain's Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
Dulhan Jayalath, Gilad Landau, Brendan Shillingford, Mark Woolrich, Oiwi Parker Jones
0
0
The past few years have produced a series of spectacular advances in the decoding of speech from brain activity. The engine of these advances has been the acquisition of labelled data, with increasingly large datasets acquired from single subjects. However, participants exhibit anatomical and other individual differences, and datasets use varied scanners and task designs. As a result, prior work has struggled to leverage data from multiple subjects, multiple datasets, multiple tasks, and unlabelled datasets. In turn, the field has not benefited from the rapidly growing number of open neural data repositories to exploit large-scale data and deep learning. To address this, we develop an initial set of neuroscience-inspired self-supervised objectives, together with a neural architecture, for representation learning from heterogeneous and unlabelled neural recordings. Experimental results show that representations learned with these objectives generalise across subjects, datasets, and tasks, and are also learned faster than using only labelled data. In addition, we set new benchmarks for two foundational speech decoding tasks. Taken together, these methods now unlock the potential for training speech decoding models with orders of magnitude more existing data.
6/7/2024
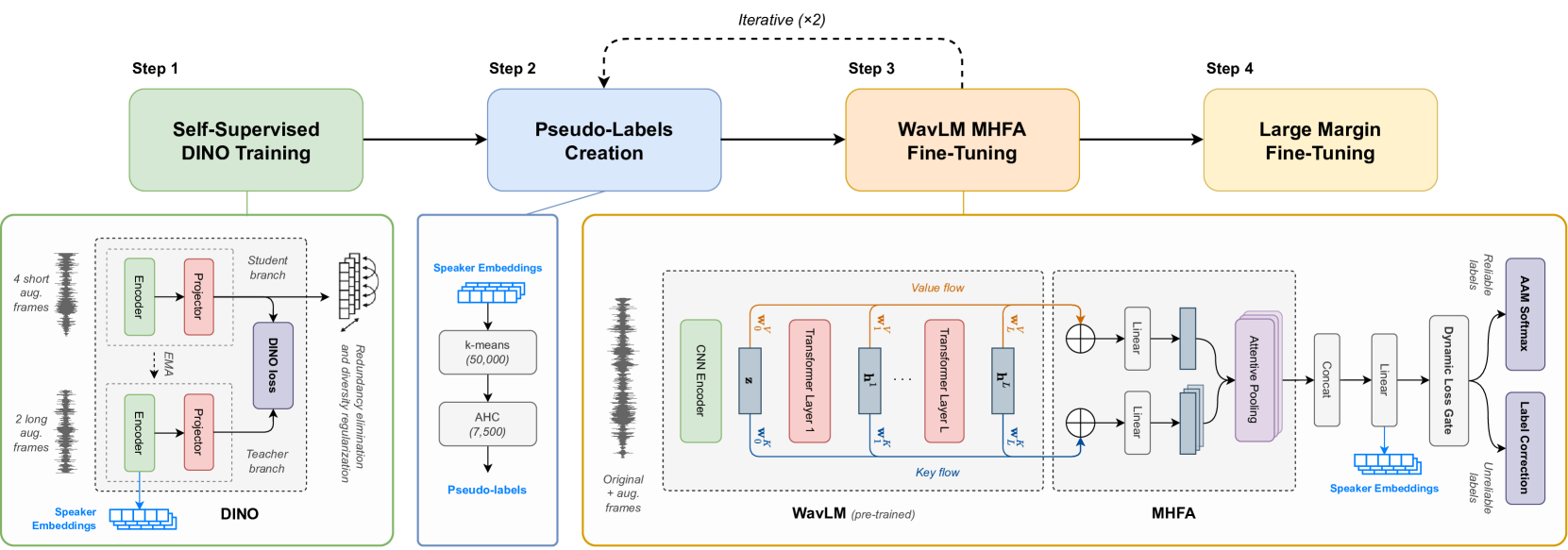
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024