Evaluation of ChatGPT Usability as A Code Generation Tool
2402.03130
0
0
🛸
Abstract
With the rapid advance of machine learning (ML) technology, large language models (LLMs) are increasingly explored as an intelligent tool to generate program code from natural language specifications. However, existing evaluations of LLMs have focused on their capabilities in comparison with humans. It is desirable to evaluate their usability when deciding on whether to use a LLM in software production. This paper proposes a user centric method. It includes metadata in the test cases of a benchmark to describe their usages, conducts testing in a multi-attempt process that mimic the uses of LLMs, measures LLM generated solutions on a set of quality attributes that reflect usability, and evaluates the performance based on user experiences in the uses of LLMs as a tool. The paper reports an application of the method in the evaluation of ChatGPT usability as a code generation tool for the R programming language. Our experiments demonstrated that ChatGPT is highly useful for generating R program code although it may fail on hard programming tasks. The user experiences are good with overall average number of attempts being 1.61 and the average time of completion being 47.02 seconds. Our experiments also found that the weakest aspect of usability is conciseness, which has a score of 3.80 out of 5. Our experiment also shows that it is hard for human developers to learn from experiences to improve the skill of using ChatGPT to generate code.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores the use of large language models (LLMs) like ChatGPT as tools for generating programming code from natural language descriptions.
- Existing evaluations have focused on comparing LLM capabilities to humans, but this paper proposes a user-centric method to evaluate the usability of LLMs for software production.
- The method includes adding metadata to test cases, multi-attempt testing, measuring quality attributes, and evaluating user experiences.
- The paper reports an application of this method to evaluate the usability of ChatGPT for generating R programming code.
Plain English Explanation
As machine learning (ML) technology advances rapidly, large language models (LLMs) like ChatGPT are increasingly being explored as tools to generate computer program code from natural language descriptions. However, previous evaluations have mainly focused on comparing the capabilities of these LLMs to human programmers.
This paper argues that it's important to also evaluate the usability of LLMs when deciding whether to use them in software development. The researchers propose a new method that looks at the user experience of working with these AI models. This includes adding information about how the test cases are supposed to be used, testing the models through multiple attempts to mimic real-world use, measuring the quality of the generated code, and getting feedback from users on their experiences.
The paper then applies this method to evaluate the usability of ChatGPT as a tool for generating R programming code. The experiments showed that ChatGPT is generally very useful for this task, although it may struggle with more complex programming problems. Users reported a good overall experience, with an average of only 1.61 attempts needed and an average completion time of 47.02 seconds. However, the researchers found that the generated code could sometimes lack conciseness, scoring 3.8 out of 5 on that metric.
The paper also discovered that it's difficult for human developers to consistently improve their ability to use ChatGPT effectively over time. This suggests that more research is needed to understand how to best leverage these AI tools in software development.
Technical Explanation
The paper proposes a user-centric method for evaluating the usability of large language models (LLMs) like ChatGPT as tools for generating programming code from natural language descriptions. The key elements of this method include:
-
Metadata in Test Cases: The researchers add metadata to the test cases that describes the intended usage of each case, such as the type of programming task, target audience, and expected outcome.
-
Multi-Attempt Testing: The testing process involves multiple attempts by the LLM to complete each task, mimicking how users would interact with the model in real-world scenarios.
-
Quality Attribute Measurement: The generated code solutions are evaluated against a set of quality attributes that reflect usability, such as correctness, completeness, conciseness, and readability.
-
User Experience Evaluation: The performance of the LLM is assessed based on user feedback and experiences in using the model as a programming assistance tool.
The paper reports an application of this method to evaluate the usability of ChatGPT for generating R programming code. The experiments showed that ChatGPT is highly useful for this task, with an average of only 1.61 attempts needed and an average completion time of 47.02 seconds. However, the weakest aspect of usability was found to be conciseness, with a score of 3.8 out of 5.
The paper also discovered that it is difficult for human developers to consistently improve their ability to use ChatGPT effectively over time, suggesting the need for further research on how to best leverage these AI tools in software development.
Critical Analysis
The paper presents a novel and valuable approach to evaluating the usability of large language models (LLMs) like ChatGPT as programming assistance tools, moving beyond the typical focus on capability comparisons with humans. By incorporating user-centric factors and real-world usage scenarios, the proposed method provides a more holistic assessment that can inform decisions about the practical deployment of these AI models in software development.
However, the paper acknowledges some limitations of the study. For example, the evaluation was limited to the R programming language, and the set of quality attributes measured may not capture all aspects of usability. Additionally, the paper does not delve into the underlying reasons why users struggled to improve their ChatGPT usage skills over time, an area that warrants further investigation.
Future research could expand the evaluation to cover a broader range of programming languages and tasks, as well as explore strategies to enhance the user experience and learning curve when working with LLMs in software engineering. Ultimately, this paper represents an important step towards a more comprehensive understanding of the strengths, weaknesses, and usability considerations of these AI-powered programming assistance tools.
Conclusion
This paper proposes a user-centric method for evaluating the usability of large language models (LLMs) like ChatGPT as tools for generating programming code from natural language descriptions. By incorporating metadata, multi-attempt testing, quality attribute measurement, and user experience evaluation, the researchers provide a more holistic assessment that can inform decisions about the practical deployment of these AI models in software development.
The application of this method to the evaluation of ChatGPT for R programming code generation demonstrated the model's overall usefulness, although it also identified areas for improvement, such as the conciseness of the generated code. The paper's findings highlight the importance of going beyond simply comparing LLM capabilities to humans and instead focusing on the real-world usability of these tools from the user's perspective.
As machine learning technology continues to advance, this user-centric approach to evaluating LLMs can help ensure that the adoption of these AI-powered programming assistance tools in software production is driven by a thorough understanding of their strengths, weaknesses, and the user experience they provide.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Ranim Khojah, Mazen Mohamad, Philipp Leitner, Francisco Gomes de Oliveira Neto
0
0
Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
4/24/2024
💬
ChatGPT as an inventor: Eliciting the strengths and weaknesses of current large language models against humans in engineering design
Daniel Nyg{aa}rd Ege, Henrik H. {O}vreb{o}, Vegar Stubberud, Martin Francis Berg, Christer Elverum, Martin Steinert, H{aa}vard Vestad
0
0
This study compares the design practices and performance of ChatGPT 4.0, a large language model (LLM), against graduate engineering students in a 48-hour prototyping hackathon, based on a dataset comprising more than 100 prototypes. The LLM participated by instructing two participants who executed its instructions and provided objective feedback, generated ideas autonomously and made all design decisions without human intervention. The LLM exhibited similar prototyping practices to human participants and finished second among six teams, successfully designing and providing building instructions for functional prototypes. The LLM's concept generation capabilities were particularly strong. However, the LLM prematurely abandoned promising concepts when facing minor difficulties, added unnecessary complexity to designs, and experienced design fixation. Communication between the LLM and participants was challenging due to vague or unclear descriptions, and the LLM had difficulty maintaining continuity and relevance in answers. Based on these findings, six recommendations for implementing an LLM like ChatGPT in the design process are proposed, including leveraging it for ideation, ensuring human oversight for key decisions, implementing iterative feedback loops, prompting it to consider alternatives, and assigning specific and manageable tasks at a subsystem level.
4/30/2024
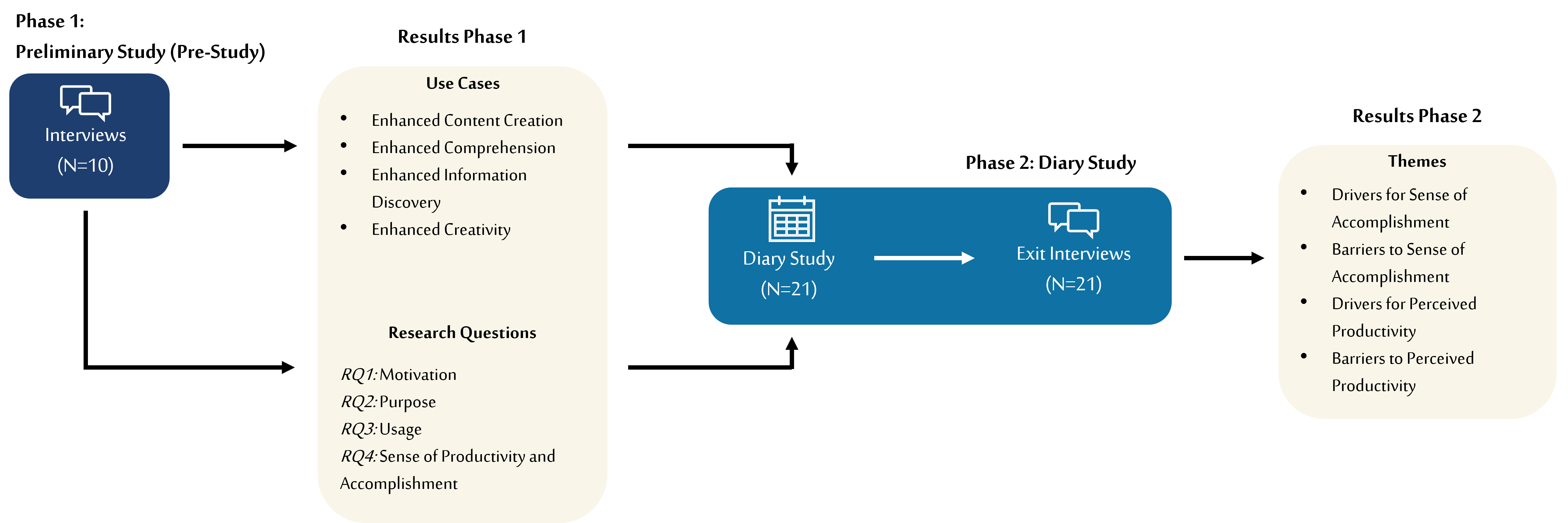
If the Machine Is As Good As Me, Then What Use Am I? -- How the Use of ChatGPT Changes Young Professionals' Perception of Productivity and Accomplishment
Charlotte Kobiella, Yarhy Said Flores L'opez, Fiona Draxler, Albrecht Schmidt
0
0
Large language models (LLMs) like ChatGPT have been widely adopted in work contexts. We explore the impact of ChatGPT on young professionals' perception of productivity and sense of accomplishment. We collected LLMs' main use cases in knowledge work through a preliminary study, which served as the basis for a two-week diary study with 21 young professionals reflecting on their ChatGPT use. Findings indicate that ChatGPT enhanced some participants' perceptions of productivity and accomplishment by enabling greater creative output and satisfaction from efficient tool utilization. Others experienced decreased perceived productivity and accomplishment, driven by a diminished sense of ownership, perceived lack of challenge, and mediocre results. We found that the suitability of task delegation to ChatGPT varies strongly depending on the task nature. It's especially suitable for comprehending broad subject domains, generating creative solutions, and uncovering new information. It's less suitable for research tasks due to hallucinations, which necessitate extensive validation.
4/22/2024
🌐
ChatGPT Is Here to Help, Not to Replace Anybody -- An Evaluation of Students' Opinions On Integrating ChatGPT In CS Courses
Bruno Pereira Cipriano, Pedro Alves
0
0
Large Language Models (LLMs) like GPT and Bard are capable of producing code based on textual descriptions, with remarkable efficacy. Such technology will have profound implications for computing education, raising concerns about cheating, excessive dependence, and a decline in computational thinking skills, among others. There has been extensive research on how teachers should handle this challenge but it is also important to understand how students feel about this paradigm shift. In this research, 52 first-year CS students were surveyed in order to assess their views on technologies with code-generation capabilities, both from academic and professional perspectives. Our findings indicate that while students generally favor the academic use of GPT, they don't over rely on it, only mildly asking for its help. Although most students benefit from GPT, some struggle to use it effectively, urging the need for specific GPT training. Opinions on GPT's impact on their professional lives vary, but there is a consensus on its importance in academic practice.
4/29/2024