Evaluation of an LLM in Identifying Logical Fallacies: A Call for Rigor When Adopting LLMs in HCI Research
2404.05213
0
0

Abstract
There is increasing interest in the adoption of LLMs in HCI research. However, LLMs may often be regarded as a panacea because of their powerful capabilities with an accompanying oversight on whether they are suitable for their intended tasks. We contend that LLMs should be adopted in a critical manner following rigorous evaluation. Accordingly, we present the evaluation of an LLM in identifying logical fallacies that will form part of a digital misinformation intervention. By comparing to a labeled dataset, we found that GPT-4 achieves an accuracy of 0.79, and for our intended use case that excludes invalid or unidentified instances, an accuracy of 0.90. This gives us the confidence to proceed with the application of the LLM while keeping in mind the areas where it still falls short. The paper describes our evaluation approach, results and reflections on the use of the LLM for our intended task.
Create account to get full access
Overview
- This paper evaluates the performance of a large language model (LLM) in identifying logical fallacies in text.
- The authors argue that as LLMs become more prevalent in human-computer interaction (HCI) research, it is crucial to rigorously evaluate their capabilities and limitations.
- The study examines how well an LLM can detect common logical fallacies, which are flaws in reasoning that can undermine the validity of an argument.
Plain English Explanation
The researchers in this study wanted to see how well a powerful artificial intelligence system, known as a large language model (LLM), could identify logical fallacies in written text. Logical fallacies are errors in reasoning that can make an argument invalid or misleading, even if the words themselves seem convincing.
As LLMs become more widely used in human-computer interaction (HCI) research, the authors argue it's important to carefully evaluate their capabilities and limitations. LLMs are complex AI models that can understand and generate human-like text, but they may not always reason as well as humans.
The researchers tested an LLM's ability to detect common logical fallacies, such as appeals to emotion, slippery slope arguments, and hasty generalizations. By understanding how well an LLM can identify these flaws in reasoning, researchers can better determine when and how to use these powerful AI systems in their work.
Technical Explanation
The paper evaluates the performance of a large language model (LLM) in identifying 12 common logical fallacies. The authors created a dataset of over 3,000 argument-fallacy pairs and used this to test the LLM's ability to correctly classify the presence or absence of a logical fallacy.
The researchers found that the LLM achieved an overall accuracy of 78% in identifying logical fallacies, with some fallacies (such as appeals to emotion) being easier to detect than others (such as hasty generalizations). The authors also noted that the LLM's performance varied depending on the length and complexity of the arguments.
The study highlights the potential for using LLMs to assist in verifying the truthfulness of claims and arguments, but also underscores the need for caution when adopting these models in HCI research. The authors argue that researchers should thoroughly evaluate the capabilities and limitations of LLMs before relying on them in their work.
Critical Analysis
The authors acknowledge several limitations of their study, including the relatively small dataset and the use of a single LLM architecture. They also note that the LLM's performance may be influenced by factors such as the specific task, dataset, and model used.
One potential concern is that the study only evaluated the LLM's ability to detect logical fallacies in isolation, without considering the broader context or quality of the arguments. In real-world scenarios, assessing the validity of an argument may require a more holistic understanding of the topic, the speaker's intent, and the overall persuasiveness of the reasoning.
Additionally, the paper does not address the potential for LLMs to be used to generate or perpetuate logical fallacies, which could be an important consideration for researchers and policymakers. As these models become more advanced and widely used, it will be crucial to understand their potential misuse and to develop safeguards against such abuse.
Conclusion
This study provides a valuable contribution to the ongoing evaluation of large language models (LLMs) and their use in human-computer interaction (HCI) research. The authors demonstrate that while LLMs can be reasonably effective at identifying logical fallacies, their performance is not perfect and may be influenced by various factors.
As LLMs become more prevalent in HCI research and applications, it is critical that researchers and practitioners approach their adoption with rigorous evaluation and a clear understanding of the models' capabilities and limitations. This study serves as a call for such diligence, encouraging the HCI community to think critically about the role of LLMs and to maintain a high standard of research integrity when incorporating these powerful AI systems into their work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
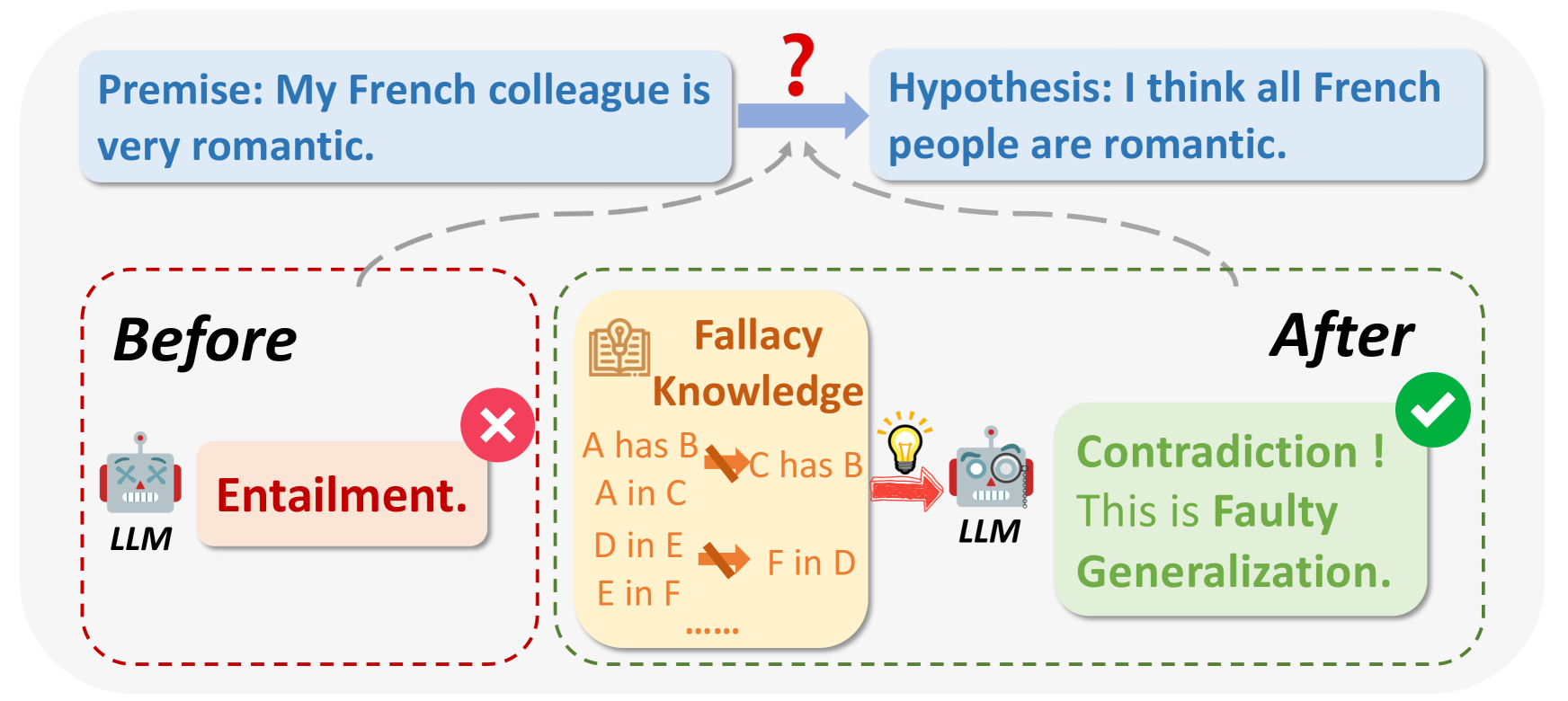
Reason from Fallacy: Enhancing Large Language Models' Logical Reasoning through Logical Fallacy Understanding
Yanda Li, Dixuan Wang, Jiaqing Liang, Guochao Jiang, Qianyu He, Yanghua Xiao, Deqing Yang
0
0
Large Language Models (LLMs) have demonstrated good performance in many reasoning tasks, but they still struggle with some complicated reasoning tasks including logical reasoning. One non-negligible reason for LLMs' suboptimal performance on logical reasoning is their overlooking of understanding logical fallacies correctly. To evaluate LLMs' capability of logical fallacy understanding (LFU), we propose five concrete tasks from three cognitive dimensions of WHAT, WHY, and HOW in this paper. Towards these LFU tasks, we have successfully constructed a new dataset LFUD based on GPT-4 accompanied by a little human effort. Our extensive experiments justify that our LFUD can be used not only to evaluate LLMs' LFU capability, but also to fine-tune LLMs to obtain significantly enhanced performance on logical reasoning.
4/9/2024
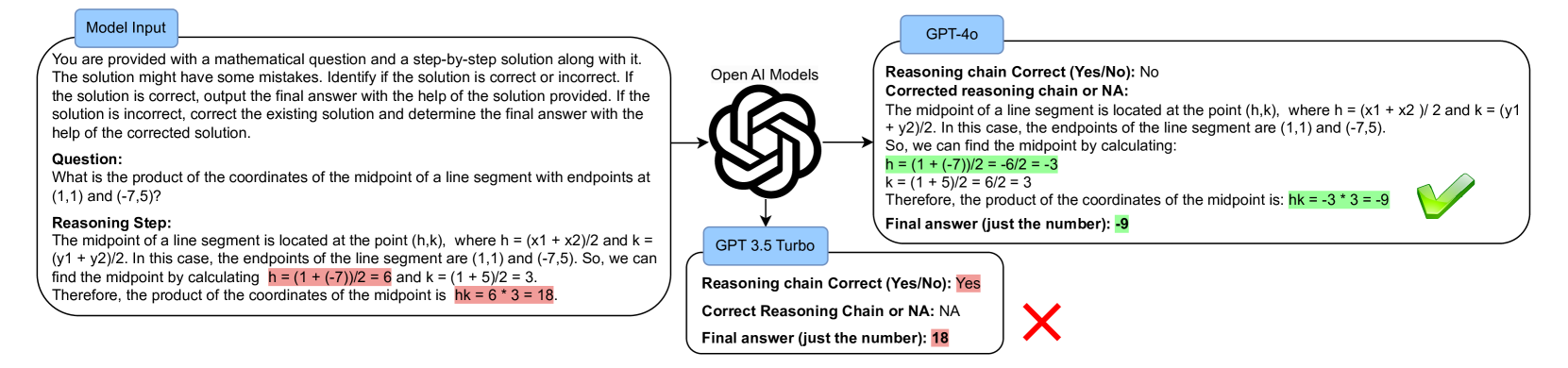
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
0
0
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
6/18/2024
👁️
I'm categorizing LLM as a productivity tool: Examining ethics of LLM use in HCI research practices
Shivani Kapania, Ruiyi Wang, Toby Jia-Jun Li, Tianshi Li, Hong Shen
0
0
Large language models are increasingly applied in real-world scenarios, including research and education. These models, however, come with well-known ethical issues, which may manifest in unexpected ways in human-computer interaction research due to the extensive engagement with human subjects. This paper reports on research practices related to LLM use, drawing on 16 semi-structured interviews and a survey conducted with 50 HCI researchers. We discuss the ways in which LLMs are already being utilized throughout the entire HCI research pipeline, from ideation to system development and paper writing. While researchers described nuanced understandings of ethical issues, they were rarely or only partially able to identify and address those ethical concerns in their own projects. This lack of action and reliance on workarounds was explained through the perceived lack of control and distributed responsibility in the LLM supply chain, the conditional nature of engaging with ethics, and competing priorities. Finally, we reflect on the implications of our findings and present opportunities to shape emerging norms of engaging with large language models in HCI research.
4/1/2024
🤯
New!Humans or LLMs as the Judge? A Study on Judgement Biases
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, Benyou Wang
0
0
Adopting human and large language models (LLM) as judges (a.k.a human- and LLM-as-a-judge) for evaluating the performance of LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLMs, questioning the reliability of the evaluation results. In this paper, we propose a novel framework that is free from referencing groundtruth annotations for investigating Misinformation Oversight Bias, Gender Bias, Authority Bias and Beauty Bias on LLM and human judges. We curate a dataset referring to the revised Bloom's Taxonomy and conduct thousands of evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the cutting-edge judges possess considerable biases. We further exploit these biases to conduct attacks on LLM judges. We hope that our work can notify the community of the bias and vulnerability of human- and LLM-as-a-judge, as well as the urgency of developing robust evaluation systems.
7/1/2024