Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
2310.12558
0
0
💬
Abstract
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) are increasingly used to access information online, but their truthfulness and accuracy are important considerations.
- Researchers compared LLMs and search engines in helping users fact-check claims.
- They found that users reading LLM explanations were more efficient but tended to over-rely on them, even when the explanations were wrong.
- Providing contrastive explanations from LLMs (both why a claim is true and false) helped mitigate over-reliance, but did not significantly outperform search engines.
- Combining search engine results and LLM explanations offered no additional benefits compared to search engines alone.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. As more people use LLMs to find information online, it's important to understand how reliable and accurate they are. This study looked at whether LLMs or traditional search engines are better at helping people fact-check claims.
The researchers had 80 people try to verify claims using either LLM explanations or search engine results. They found that people using the LLM explanations were able to do it more quickly, but they often believed the LLM even when the explanation was wrong. This over-reliance on the LLM could be dangerous, especially in important situations where inaccurate information could lead to serious consequences.
To address this, the researchers tried having the LLM provide both sides of the story - explaining why the claim was true and why it was false. This "contrastive" approach helped reduce people's over-trust in the LLM, but it still didn't outperform regular search engines. And combining the search results with the LLM explanations didn't provide any extra benefits compared to just using the search engine alone.
Overall, the study suggests that while LLMs can be efficient at providing information, we shouldn't blindly trust their explanations, especially for important facts. We still need to carefully evaluate the information from multiple sources, just as we would with a regular web search.
Technical Explanation
The researchers conducted experiments with 80 crowdworkers to compare the effectiveness of large language models (LLMs) and traditional search engines (information retrieval systems) in helping users fact-check claims. They prompted the LLMs to validate a given claim and provide corresponding explanations.
The results showed that users reading the LLM explanations were significantly more efficient at fact-checking than those using search engines, while achieving similar accuracy. However, the users tended to over-rely on the LLM explanations, even when they were incorrect.
To address this over-reliance, the researchers asked the LLMs to provide "contrastive" explanations - explaining both why the claim was true and why it was false. Presenting both sides of the explanation to users helped mitigate their over-trust in the LLM. However, this contrastive approach still could not significantly outperform search engines.
Furthermore, the study found that providing both search engine results and LLM explanations did not offer any complementary benefits compared to using search engines alone.
Critical Analysis
The study highlights an important challenge with using LLMs for high-stakes information access: over-reliance on their explanations, even when they are inaccurate. This could lead to critical consequences in real-world settings where factual information is crucial.
While the contrastive explanations helped reduce this over-reliance, they did not ultimately outperform traditional search engines. This suggests that natural language explanations from LLMs may not be a reliable replacement for directly reading the source material retrieved through web searches.
The study acknowledges that further research is needed to address the limitations of LLMs in fact-checking tasks. Potential areas for improvement could include enhancing LLM capabilities to better assess the credibility of information, or developing more sophisticated techniques to combine LLM outputs with search engine results.
Additionally, the study's focus on crowdworkers may limit the generalizability of the findings. Evaluating the performance of LLMs and search engines with a more diverse set of users, including those with varying levels of digital literacy, could provide additional insights.
Conclusion
This study highlights the importance of critically evaluating the information provided by large language models, even when they appear to offer efficient and natural language-based explanations. While LLMs can be useful tools for accessing online information, users should not blindly trust their outputs, especially in high-stakes situations where factual accuracy is crucial.
The findings suggest that traditional search engines may still be a more reliable approach for fact-checking, as users are less likely to over-rely on the information they retrieve. As LLM technology continues to advance, further research will be needed to ensure these powerful AI systems can be leveraged safely and responsibly for information access and verification.
Related Papers

Multimodal Large Language Models to Support Real-World Fact-Checking
Jiahui Geng, Yova Kementchedjhieva, Preslav Nakov, Iryna Gurevych
0
0
Multimodal large language models (MLLMs) carry the potential to support humans in processing vast amounts of information. While MLLMs are already being used as a fact-checking tool, their abilities and limitations in this regard are understudied. Here is aim to bridge this gap. In particular, we propose a framework for systematically assessing the capacity of current multimodal models to facilitate real-world fact-checking. Our methodology is evidence-free, leveraging only these models' intrinsic knowledge and reasoning capabilities. By designing prompts that extract models' predictions, explanations, and confidence levels, we delve into research questions concerning model accuracy, robustness, and reasons for failure. We empirically find that (1) GPT-4V exhibits superior performance in identifying malicious and misleading multimodal claims, with the ability to explain the unreasonable aspects and underlying motives, and (2) existing open-source models exhibit strong biases and are highly sensitive to the prompt. Our study offers insights into combating false multimodal information and building secure, trustworthy multimodal models. To the best of our knowledge, we are the first to evaluate MLLMs for real-world fact-checking.
4/29/2024
Correcting misinformation on social media with a large language model
Xinyi Zhou, Ashish Sharma, Amy X. Zhang, Tim Althoff
0
0
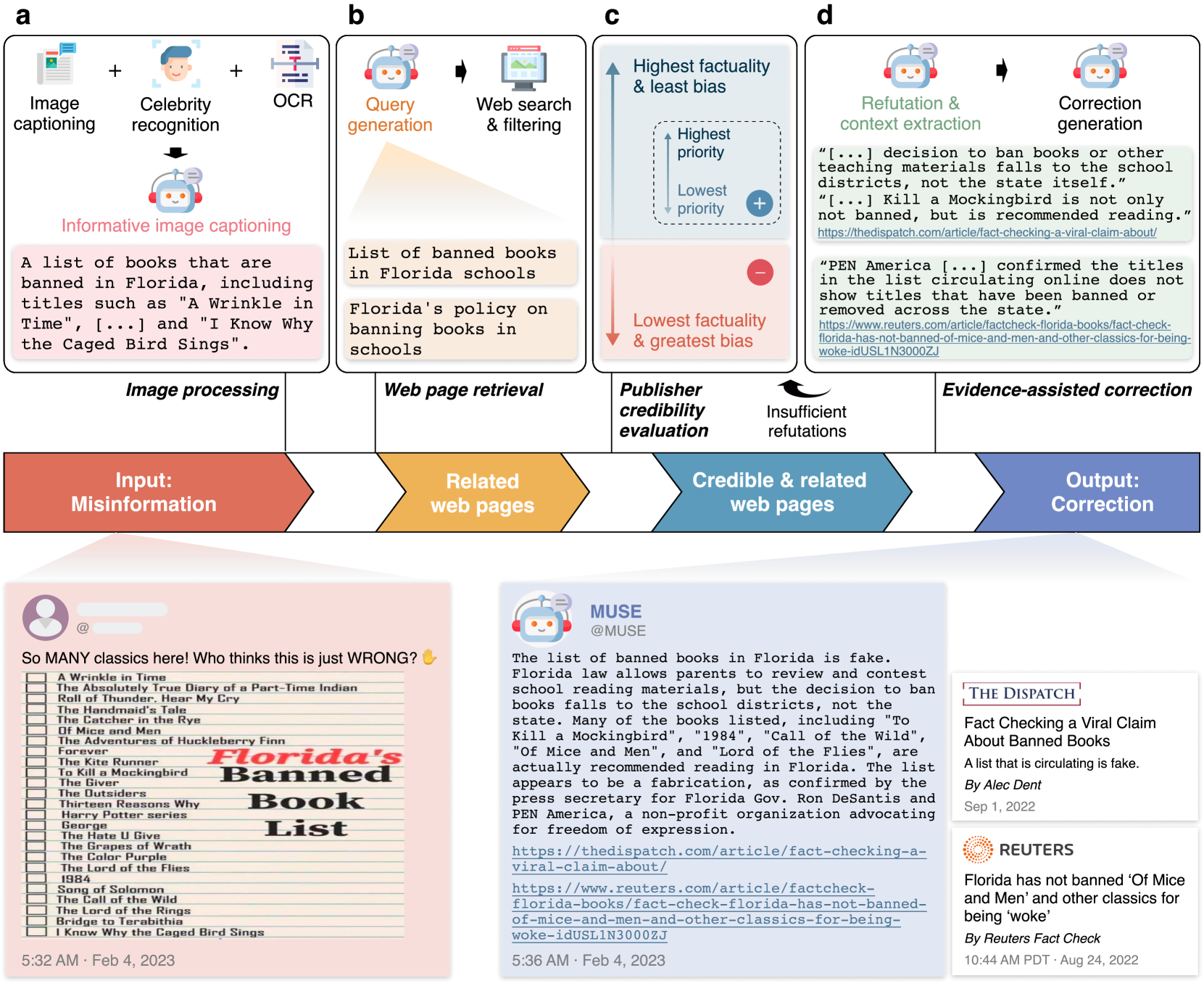
Real-world misinformation can be partially correct and even factual but misleading. It undermines public trust in science and democracy, particularly on social media, where it can spread rapidly. High-quality and timely correction of misinformation that identifies and explains its (in)accuracies has been shown to effectively reduce false beliefs. Despite the wide acceptance of manual correction, it is difficult to be timely and scalable, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction-however, they struggle due to a lack of recent information, a tendency to produce false content, and limitations in addressing multimodal information. We propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving evidence as refutations or contexts, MUSE identifies and explains (in)accuracies in a piece of content-not presupposed to be misinformation-with references. It also describes images and conducts multimodal searches to verify and correct multimodal content. Fact-checking experts evaluate responses to social media content that are not presupposed to be (non-)misinformation but broadly include incorrect, partially correct, and correct posts, that may or may not be misleading. We propose and evaluate 13 dimensions of misinformation correction quality, ranging from the accuracy of identifications and factuality of explanations to the relevance and credibility of references. The results demonstrate MUSE's ability to promptly write high-quality responses to potential misinformation on social media-overall, MUSE outperforms GPT-4 by 37% and even high-quality responses from laypeople by 29%. This work reveals LLMs' potential to help combat real-world misinformation effectively and efficiently.
5/2/2024
💬
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
0
0
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
4/10/2024
Can LLM-Generated Misinformation Be Detected?
Canyu Chen, Kai Shu
0
0
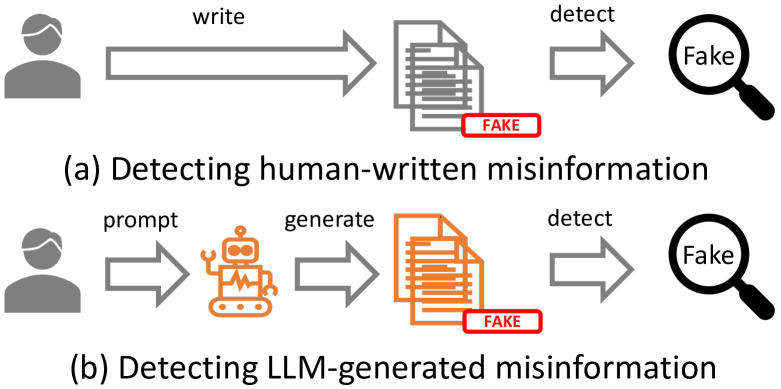
The advent of Large Language Models (LLMs) has made a transformative impact. However, the potential that LLMs such as ChatGPT can be exploited to generate misinformation has posed a serious concern to online safety and public trust. A fundamental research question is: will LLM-generated misinformation cause more harm than human-written misinformation? We propose to tackle this question from the perspective of detection difficulty. We first build a taxonomy of LLM-generated misinformation. Then we categorize and validate the potential real-world methods for generating misinformation with LLMs. Then, through extensive empirical investigation, we discover that LLM-generated misinformation can be harder to detect for humans and detectors compared to human-written misinformation with the same semantics, which suggests it can have more deceptive styles and potentially cause more harm. We also discuss the implications of our discovery on combating misinformation in the age of LLMs and the countermeasures.
4/16/2024