Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning

0
Sign in to get full access
Overview
- This paper evaluates the ability of large language models (LLMs) to handle mistakes in mathematical reasoning.
- The researchers created a new dataset called MWP-Mistake to test LLMs on common mathematical mistakes.
- The results show that LLMs struggle to identify and correct errors in mathematical problem-solving, even on relatively simple tasks.
- This highlights the limitations of current LLMs in terms of true mathematical understanding and reasoning abilities.
Plain English Explanation
The paper examines how well large language models (LLMs) like GPT can handle mistakes in mathematical reasoning. The researchers created a new dataset called MWP-Mistake that contains common mistakes people make when solving math word problems. They then tested different LLMs on this dataset to see how well the models could identify and correct those mistakes.
The findings are concerning - even on relatively simple math problems, the LLMs struggled to recognize when there was an error in the reasoning and provide the correct solution. This suggests that despite their impressive language abilities, current LLMs do not truly understand mathematics in the way a human would. They lack the deeper reasoning skills needed to identify and fix mistakes in mathematical problem-solving.
This is an important limitation to be aware of, as LLMs are increasingly being used for tasks that require robust mathematical capabilities. The research indicates that LLMs may not be as "intelligent" or "thoughtful" as some hype might suggest when it comes to handling the nuances of mathematical reasoning. More work is needed to develop AI systems that can genuinely understand and reason about math at a human level.
Technical Explanation
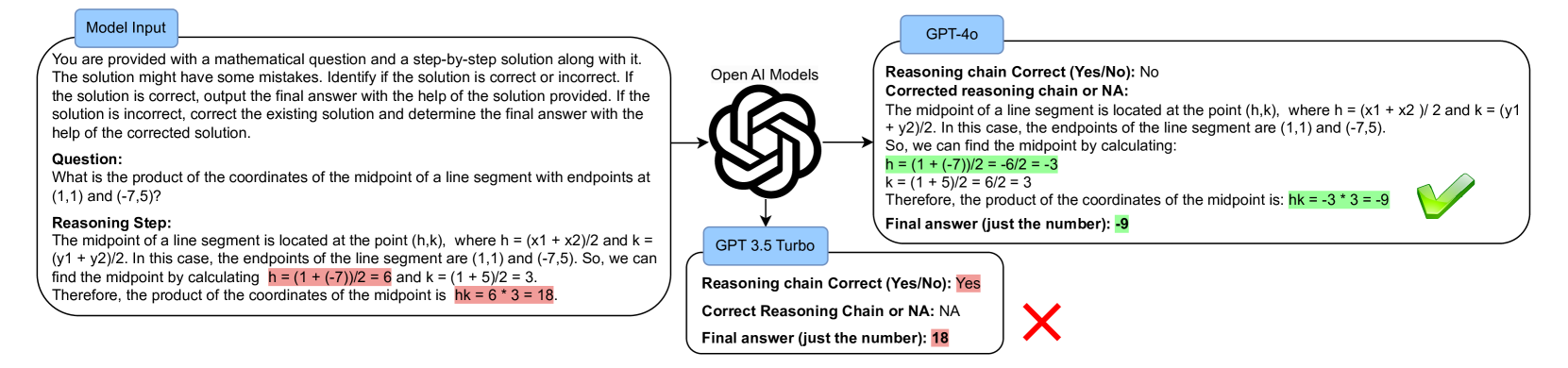
The paper presents a new dataset called MWP-Mistake (link) that is designed to test the ability of large language models (LLMs) to handle mistakes in mathematical reasoning. The dataset consists of mathematical word problems that contain common errors, such as using the wrong operation or making a logical mistake in the problem-solving process.
The researchers evaluated several popular LLMs, including GPT-3 and PaLM, on the MWP-Mistake dataset (link). The models were asked to both identify the mistakes in the problems and provide the correct solutions. The results showed that the LLMs struggled to consistently recognize and fix the errors, even on relatively straightforward math problems (link).
This suggests that while LLMs excel at natural language processing and generation, they lack the deeper mathematical reasoning abilities required to truly understand and correct mistakes in problem-solving (link). The paper argues that this represents a key limitation in the current capabilities of LLMs and highlights the need for continued advancements in AI systems that can handle mathematical reasoning more robustly.
Critical Analysis
The paper provides valuable insights into the limitations of current large language models when it comes to mathematical reasoning. The creation of the MWP-Mistake dataset is a significant contribution, as it allows for a more targeted evaluation of LLM abilities in this domain.
However, the paper does not delve deeply into the potential reasons why LLMs struggle with mathematical mistakes. It would be helpful to understand the underlying factors, such as the models' lack of mathematical knowledge, their inability to follow logical steps, or their tendency to rely on surface-level patterns rather than true comprehension.
Additionally, the paper focuses primarily on evaluating the models' performance on the MWP-Mistake dataset, but does not explore how the findings might translate to real-world mathematical tasks or applications. Further research could investigate the implications of these limitations in more practical settings.
It is also worth considering whether the observed shortcomings of LLMs in mathematical reasoning are inherent to the current approaches or if they can be addressed through further model development and training techniques. The paper does not speculate on potential avenues for improvement, which could be a fruitful area for future work.
Conclusion
This paper highlights a critical limitation in the capabilities of large language models - their inability to consistently identify and correct mistakes in mathematical reasoning. The creation of the MWP-Mistake dataset and the evaluation of popular LLMs on this task reveal that these models, despite their impressive language skills, lack the deeper understanding and reasoning abilities required for robust mathematical problem-solving.
These findings serve as a important reminder that the current achievements of LLMs should not be interpreted as true intelligence or a comprehensive solution to tasks requiring complex reasoning. As AI systems become more prevalent in domains that rely on mathematical and analytical skills, it is crucial to understand and address the limitations exposed by this research. Continued advancements in AI architectures and training methods will be necessary to develop systems that can genuinely understand and reason about mathematics at a human level.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
Read more6/18/2024
0
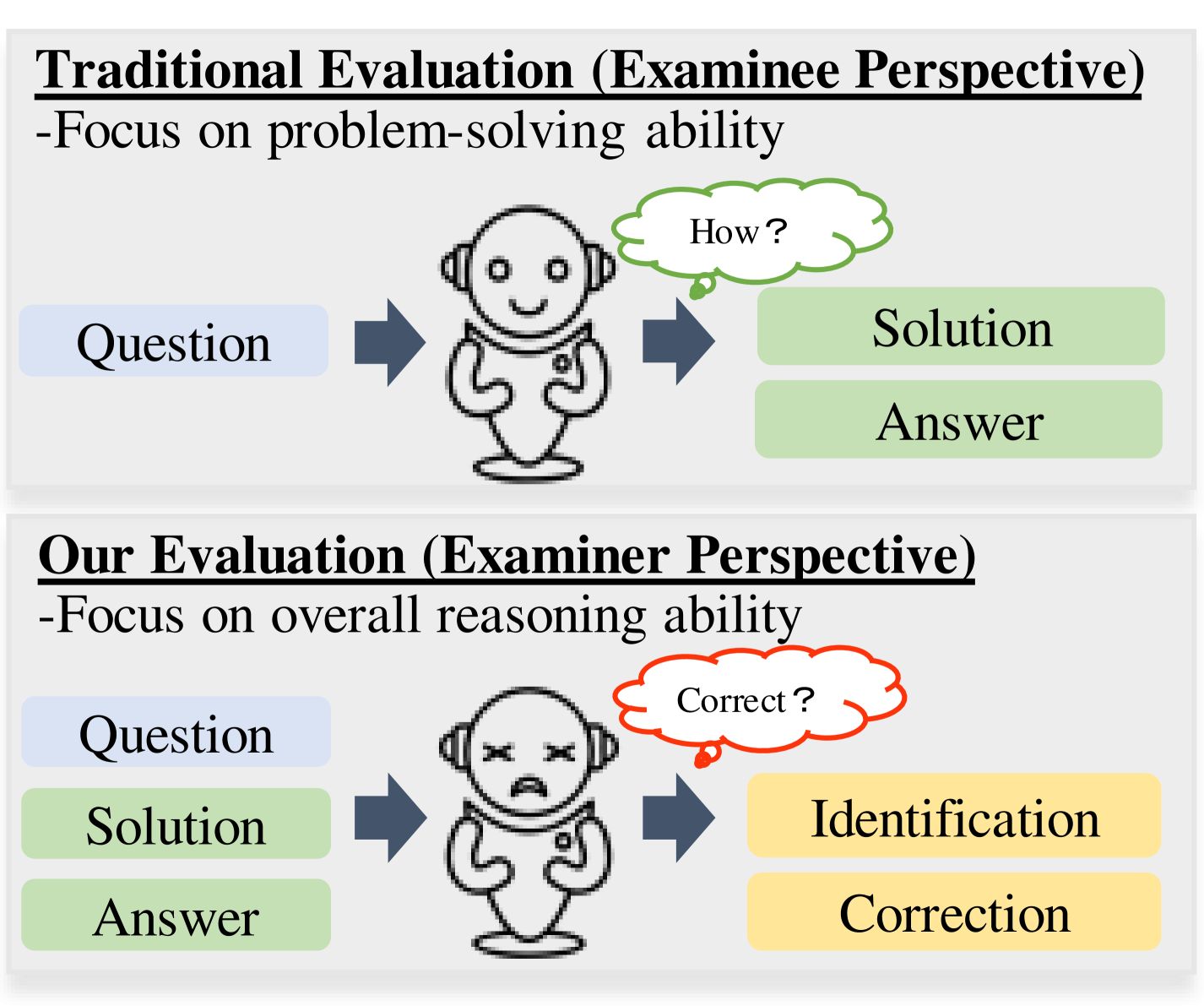
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024

0
LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Arash Gholami Davoodi, Seyed Pouyan Mousavi Davoudi, Pouya Pezeshkpour
Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
Read more6/11/2024

0
Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
Read more6/28/2024