Evaluation of state-of-the-art ASR Models in Child-Adult Interactions

0
Sign in to get full access
Overview
- This paper evaluates the performance of state-of-the-art automatic speech recognition (ASR) models on child-adult interactions.
- The researchers tested multiple ASR models, including large language models, on transcripts of real-world conversations between children and adults.
- The goal was to understand the current capabilities and limitations of ASR in handling child speech, which can be more challenging due to factors like higher pitch and less developed articulation.
Plain English Explanation
The researchers in this paper wanted to see how well the latest and greatest automatic speech recognition (ASR) models could handle conversations between children and adults. ASR is the technology that allows computers to transcribe spoken language into text.
Child speech can be more difficult for ASR systems to understand compared to adult speech. This is because children's voices tend to have higher pitch and their speech may not be as clearly articulated. The researchers tested several state-of-the-art ASR models, including large language models, on real-world transcripts of children talking with adults.
The goal was to evaluate the current capabilities and limitations of these ASR systems when it comes to child-inclusive interactions. This kind of evaluation is important as ASR technology becomes more widely used in applications like educational software and voice assistants that need to work well for both children and adults.
Technical Explanation
The researchers tested a variety of state-of-the-art ASR models, including large language models like Whisper and HuBERT, on a dataset of real-world conversations between children and adults. The dataset contained transcripts of interactions from educational and clinical settings, with the child and adult speaker annotations.
The researchers evaluated the ASR models' performance using metrics like word error rate (WER) and speaker diarization error rate (DER). They analyzed the results both at the overall level and broken down by speaker age (child vs. adult). Additionally, they investigated the impact of factors like background noise and speaker overlap on the models' performance.
The results showed that while the latest ASR models performed reasonably well on adult speech, they struggled significantly with child speech. The WER for child speakers was over 2.5 times higher than for adult speakers. The researchers also found that the ASR models had difficulty correctly identifying when the child or adult was speaking, leading to high diarization errors.
Further analysis revealed that the ASR models' limitations were more pronounced in scenarios with background noise or overlapping speech, which are common in real-world child-adult interactions. The researchers discuss potential reasons for these performance gaps, such as the models' training data not adequately representing child speech characteristics.
Critical Analysis
The paper provides a valuable and timely evaluation of state-of-the-art ASR models in the context of child-adult interactions, an area that has received relatively little attention compared to adult speech recognition. The researchers' use of real-world data, rather than synthesized or curated datasets, adds to the relevance and real-world applicability of their findings.
However, the paper could have benefited from a more in-depth discussion of the potential reasons for the observed performance gaps. While the authors suggest that the models' training data may not have adequately captured child speech characteristics, a deeper analysis of the specific acoustic, linguistic, or other factors contributing to the challenges would have strengthened the paper.
Additionally, the researchers could have explored potential strategies or architectural changes to improve the ASR models' handling of child speech, beyond just identifying the limitations. Providing some suggestions or directions for future research in this area would have made the paper more actionable and impactful for the broader speech recognition community.
Conclusion
This paper highlights the significant challenges that current state-of-the-art ASR models face when dealing with child speech in real-world, child-adult interactions. The researchers' evaluation reveals substantial performance gaps between child and adult speakers, particularly in the presence of background noise or overlapping speech.
These findings underscore the need for further research and development to bridge the performance gap between child and adult speech recognition. As ASR technology becomes more widely deployed in applications involving children, such as educational software and voice assistants, improving the models' ability to accurately handle child speech will be crucial for ensuring equitable and inclusive user experiences.
The insights from this paper can help guide future research directions and inform the design of more robust and child-friendly ASR systems, ultimately contributing to the advancement of speech recognition technology and its broader societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluation of state-of-the-art ASR Models in Child-Adult Interactions
Aditya Ashvin, Rimita Lahiri, Aditya Kommineni, Somer Bishop, Catherine Lord, Sudarsana Reddy Kadiri, Shrikanth Narayanan
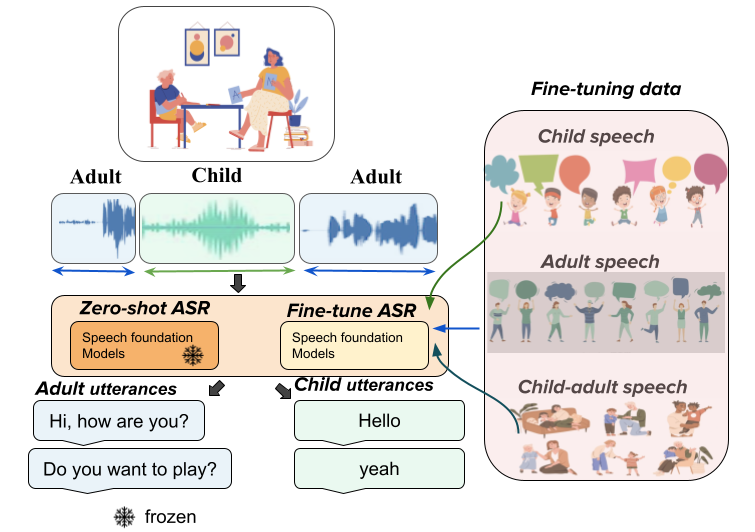
The ability to reliably transcribe child-adult conversations in a clinical setting is valuable for diagnosis and understanding of numerous developmental disorders such as Autism Spectrum Disorder. Recent advances in deep learning architectures and availability of large scale transcribed data has led to development of speech foundation models that have shown dramatic improvements in ASR performance. However, the ability of these models to translate well to conversational child-adult interactions is under studied. In this work, we provide a comprehensive evaluation of ASR performance on a dataset containing child-adult interactions from autism diagnostic sessions, using Whisper, Wav2Vec2, HuBERT, and WavLM. We find that speech foundation models show a noticeable performance drop (15-20% absolute WER) for child speech compared to adult speech in the conversational setting. Then, we employ LoRA on the best performing zero shot model (whisper-large) to probe the effectiveness of fine-tuning in a low resource setting, resulting in ~8% absolute WER improvement for child speech and ~13% absolute WER improvement for adult speech.
Read more9/25/2024
🚀
0
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Ahmed Adel Attia, Jing Liu, Wei Ai, Dorottya Demszky, Carol Espy-Wilson
Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. They were able to demonstrate some improvement on a limited testset. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We reduce the Word Error Rate (WER) on the MyST testset 13.93% to 9.11% with Whisper-Small and from 13.23% to 8.61% with Whisper-Medium and show that this improvement can be generalized to unseen datasets. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.
Read more5/16/2024
🗣️
0
Automatic Speech Recognition of Non-Native Child Speech for Language Learning Applications
Simone Wills, Yu Bai, Cristian Tejedor-Garcia, Catia Cucchiarini, Helmer Strik
Voicebots have provided a new avenue for supporting the development of language skills, particularly within the context of second language learning. Voicebots, though, have largely been geared towards native adult speakers. We sought to assess the performance of two state-of-the-art ASR systems, Wav2Vec2.0 and Whisper AI, with a view to developing a voicebot that can support children acquiring a foreign language. We evaluated their performance on read and extemporaneous speech of native and non-native Dutch children. We also investigated the utility of using ASR technology to provide insight into the children's pronunciation and fluency. The results show that recent, pre-trained ASR transformer-based models achieve acceptable performance from which detailed feedback on phoneme pronunciation quality can be extracted, despite the challenging nature of child and non-native speech.
Read more7/24/2024

0
Data Efficient Child-Adult Speaker Diarization with Simulated Conversations
Anfeng Xu, Tiantian Feng, Helen Tager-Flusberg, Catherine Lord, Shrikanth Narayanan
Automating child speech analysis is crucial for applications such as neurocognitive assessments. Speaker diarization, which identifies ``who spoke when'', is an essential component of the automated analysis. However, publicly available child-adult speaker diarization solutions are scarce due to privacy concerns and a lack of annotated datasets, while manually annotating data for each scenario is both time-consuming and costly. To overcome these challenges, we propose a data-efficient solution by creating simulated child-adult conversations using AudioSet. We then train a Whisper Encoder-based model, achieving strong zero-shot performance on child-adult speaker diarization using real datasets. The model performance improves substantially when fine-tuned with only 30 minutes of real train data, with LoRA further improving the transfer learning performance. The source code and the child-adult speaker diarization model trained on simulated conversations are publicly available.
Read more9/16/2024