EVCap: Retrieval-Augmented Image Captioning with External Visual-Name Memory for Open-World Comprehension
2311.15879
0
0

Abstract
Large language models (LLMs)-based image captioning has the capability of describing objects not explicitly observed in training data; yet novel objects occur frequently, necessitating the requirement of sustaining up-to-date object knowledge for open-world comprehension. Instead of relying on large amounts of data and/or scaling up network parameters, we introduce a highly effective retrieval-augmented image captioning method that prompts LLMs with object names retrieved from External Visual--name memory (EVCap). We build ever-changing object knowledge memory using objects' visuals and names, enabling us to (i) update the memory at a minimal cost and (ii) effortlessly augment LLMs with retrieved object names by utilizing a lightweight and fast-to-train model. Our model, which was trained only on the COCO dataset, can adapt to out-of-domain without requiring additional fine-tuning or re-training. Our experiments conducted on benchmarks and synthetic commonsense-violating data show that EVCap, with only 3.97M trainable parameters, exhibits superior performance compared to other methods based on frozen pre-trained LLMs. Its performance is also competitive to specialist SOTAs that require extensive training.
Create account to get full access
Overview
- This paper presents a new image captioning model called EVCap that leverages an external visual-name memory to improve open-world comprehension.
- EVCap can generate captions for images that contain objects and scenes not seen during training, overcoming the limitations of traditional image captioning models.
- The model incorporates a retrieval-augmented approach, integrating information from an external memory of visual-name associations to enhance its understanding and description of the input image.
Plain English Explanation
The paper introduces a new image captioning model called EVCap that aims to improve the ability to describe images, even when they contain unfamiliar objects or scenes. Traditional image captioning models are trained on a fixed set of objects and scenes, so they struggle to generate accurate captions for images that include novel elements.
EVCap overcomes this limitation by incorporating an external memory of visual-name associations. When presented with an image, EVCap first retrieves relevant information from this external memory to supplement its understanding of the image content. It then uses this enriched understanding to generate a more comprehensive and accurate caption, even for images containing objects or scenes that the model was not explicitly trained on.
This retrieval-augmented approach allows EVCap to go beyond the confines of its training data and demonstrate better "open-world comprehension" - the ability to understand and describe images in a more flexible and adaptable way.
Technical Explanation
The core of EVCap is a encoder-decoder architecture that generates image captions. The encoder takes an input image and produces a visual representation, while the decoder uses this representation to iteratively generate the output caption word-by-word.
To enhance the model's open-world comprehension, the authors introduce an external visual-name memory component. This memory stores associations between visual elements (e.g., object appearances, scenes) and their corresponding names or descriptions. When processing a new image, EVCap retrieves relevant information from this external memory and integrates it into the caption generation process.
The retrieval mechanism is implemented as an attention-based module that allows the model to selectively focus on the most relevant visual-name associations for the current image. This helps EVCap to recognize and describe novel objects and scenes that may not be present in its original training data.
The authors evaluate EVCap on benchmark image captioning datasets, including those designed to test open-world capabilities, and demonstrate significant improvements over existing state-of-the-art models. This suggests that the retrieval-augmented approach of EVCap is an effective way to enhance image captioning performance, particularly in challenging real-world scenarios.
Critical Analysis
The authors acknowledge that EVCap's reliance on an external visual-name memory introduces additional complexity and computational overhead compared to standalone image captioning models. The need to maintain and update this external memory could also present scalability challenges as the knowledge base grows.
Furthermore, the paper does not extensively explore the limits of EVCap's open-world comprehension capabilities. While the model shows promising results on existing benchmark datasets, it remains to be seen how it would perform on truly open-ended, highly diverse image sets that push the boundaries of current computer vision and language understanding capabilities.
Future work could investigate ways to seamlessly integrate the external memory into the core model architecture, reducing the overhead and making the system more end-to-end. Additionally, further research is needed to understand the model's generalization abilities and identify any potential biases or blindspots in its knowledge acquisition and caption generation processes.
Conclusion
The EVCap model presented in this paper represents an important step forward in image captioning by leveraging an external visual-name memory to improve open-world comprehension. This retrieval-augmented approach allows the model to generate more accurate and comprehensive captions for a wider range of images, going beyond the limitations of traditional captioning systems.
While the model has some technical and scalability challenges to overcome, the authors have demonstrated the potential of this approach to enhance image understanding and description capabilities. As the field of computer vision and natural language processing continues to advance, models like EVCap could play a crucial role in developing more flexible and adaptable systems that can better comprehend and communicate about the diverse visual world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Towards Retrieval-Augmented Architectures for Image Captioning
Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Alessandro Nicolosi, Rita Cucchiara
0
0
The objective of image captioning models is to bridge the gap between the visual and linguistic modalities by generating natural language descriptions that accurately reflect the content of input images. In recent years, researchers have leveraged deep learning-based models and made advances in the extraction of visual features and the design of multimodal connections to tackle this task. This work presents a novel approach towards developing image captioning models that utilize an external kNN memory to improve the generation process. Specifically, we propose two model variants that incorporate a knowledge retriever component that is based on visual similarities, a differentiable encoder to represent input images, and a kNN-augmented language model to predict tokens based on contextual cues and text retrieved from the external memory. We experimentally validate our approach on COCO and nocaps datasets and demonstrate that incorporating an explicit external memory can significantly enhance the quality of captions, especially with a larger retrieval corpus. This work provides valuable insights into retrieval-augmented captioning models and opens up new avenues for improving image captioning at a larger scale.
5/24/2024

Hyperbolic Learning with Synthetic Captions for Open-World Detection
Fanjie Kong, Yanbei Chen, Jiarui Cai, Davide Modolo
0
0
Open-world detection poses significant challenges, as it requires the detection of any object using either object class labels or free-form texts. Existing related works often use large-scale manual annotated caption datasets for training, which are extremely expensive to collect. Instead, we propose to transfer knowledge from vision-language models (VLMs) to enrich the open-vocabulary descriptions automatically. Specifically, we bootstrap dense synthetic captions using pre-trained VLMs to provide rich descriptions on different regions in images, and incorporate these captions to train a novel detector that generalizes to novel concepts. To mitigate the noise caused by hallucination in synthetic captions, we also propose a novel hyperbolic vision-language learning approach to impose a hierarchy between visual and caption embeddings. We call our detector ``HyperLearner''. We conduct extensive experiments on a wide variety of open-world detection benchmarks (COCO, LVIS, Object Detection in the Wild, RefCOCO) and our results show that our model consistently outperforms existing state-of-the-art methods, such as GLIP, GLIPv2 and Grounding DINO, when using the same backbone.
4/9/2024

Benchmarking and Improving Detail Image Caption
Hongyuan Dong, Jiawen Li, Bohong Wu, Jiacong Wang, Yuan Zhang, Haoyuan Guo
0
0
Image captioning has long been regarded as a fundamental task in visual understanding. Recently, however, few large vision-language model (LVLM) research discusses model's image captioning performance because of the outdated short-caption benchmarks and unreliable evaluation metrics. In this work, we propose to benchmark detail image caption task by curating high-quality evaluation datasets annotated by human experts, GPT-4V and Gemini-1.5-Pro. We also design a more reliable caption evaluation metric called CAPTURE (CAPtion evaluation by exTracting and coUpling coRE information). CAPTURE extracts visual elements, e.g., objects, attributes and relations from captions, and then matches these elements through three stages, achieving the highest consistency with expert judgements over other rule-based or model-based caption metrics. The proposed benchmark and metric provide reliable evaluation for LVLM's detailed image captioning ability. Guided by this evaluation, we further explore to unleash LVLM's detail caption capabilities by synthesizing high-quality data through a five-stage data construction pipeline. Our pipeline only uses a given LVLM itself and other open-source tools, without any human or GPT-4V annotation in the loop. Experiments show that the proposed data construction strategy significantly improves model-generated detail caption data quality for LVLMs with leading performance, and the data quality can be further improved in a self-looping paradigm. All code and dataset will be publicly available at https://github.com/foundation-multimodal-models/CAPTURE.
6/3/2024
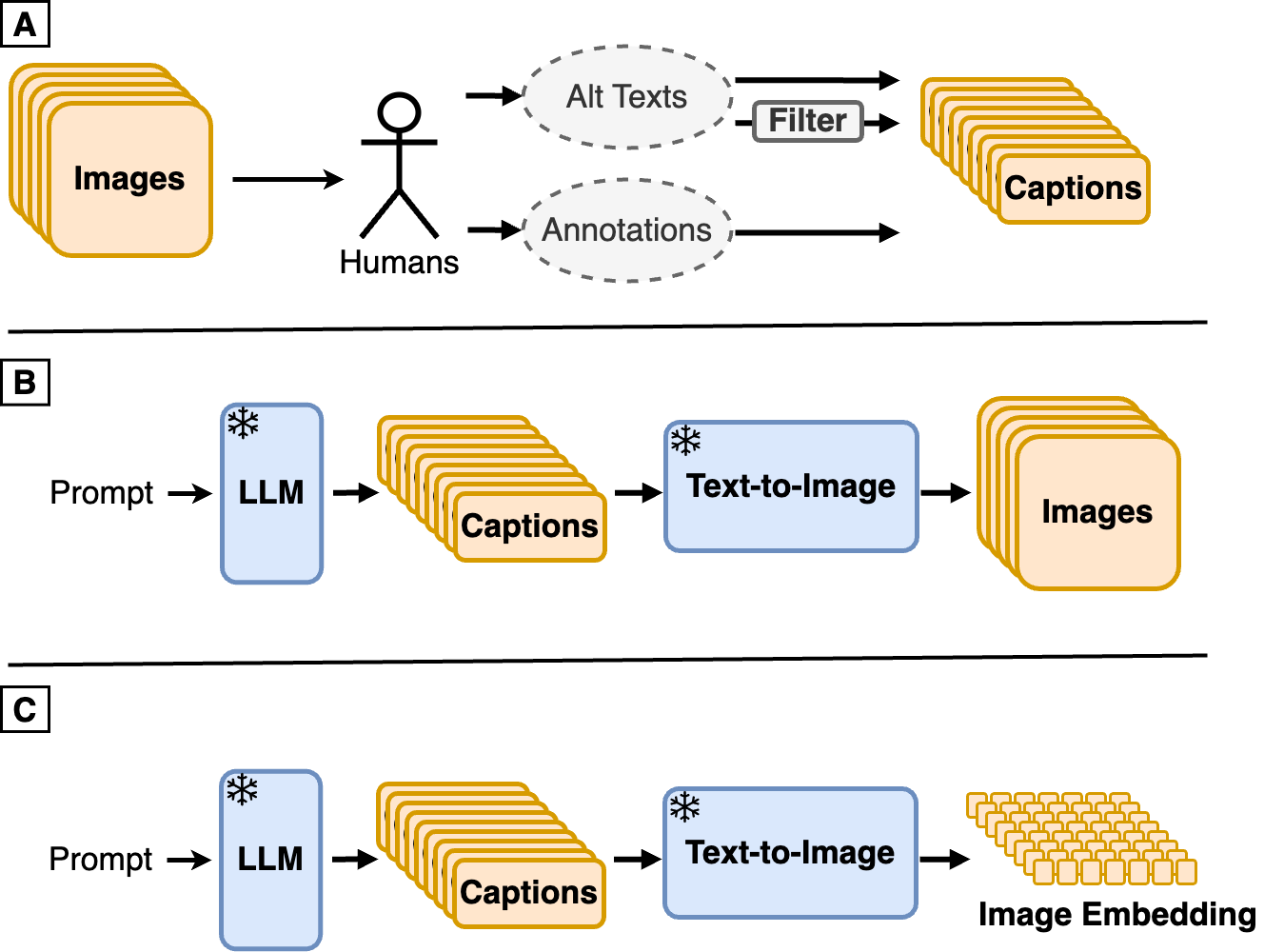
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024