Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
2403.07750
0
0
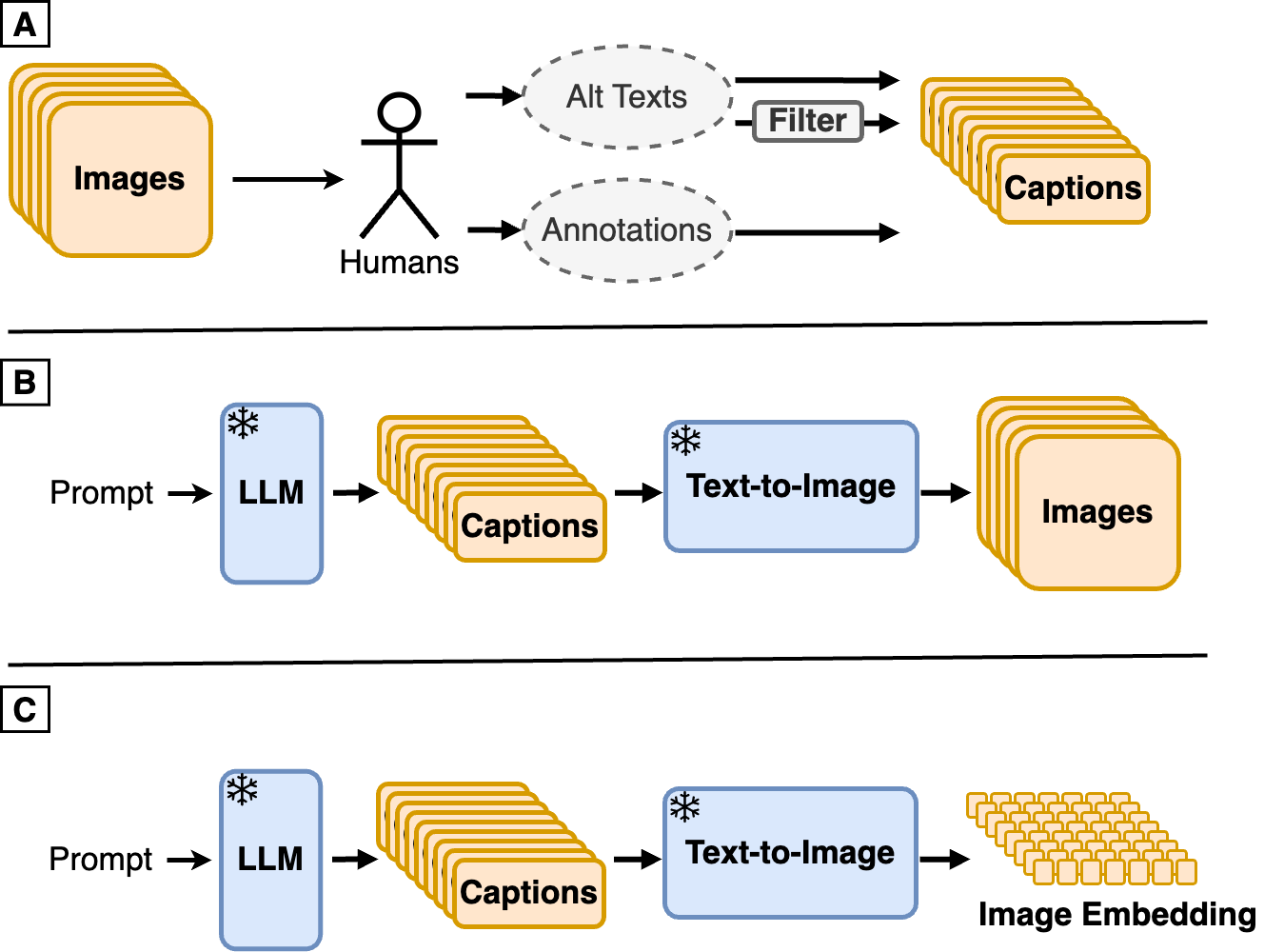
Abstract
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Create account to get full access
Overview
- This paper explores a technique called "Synth²" to boost the performance of visual-language models (VLMs) by incorporating synthetic image captions and image embeddings.
- Synthetic captions are generated using large language models, while synthetic image embeddings are created by diffusion models trained on image-caption pairs.
- The goal is to leverage these synthetic data sources to improve VLM performance on tasks like image captioning and visual question answering.
Plain English Explanation
The researchers behind this paper have developed a technique called "Synth²" to help improve the capabilities of visual-language models (VLMs) - AI systems that can understand and generate text related to visual information.
Improving text embeddings with large language models and distilling vision-language models from millions of videos have shown that large pre-trained language models can be valuable for enhancing VLM performance. Building on this, the Synth² approach adds two key ingredients:
-
Synthetic captions: The researchers use powerful language models to generate realistic-sounding captions for images, even for images the model hasn't seen before. These synthetic captions can then be used to further train the VLM.
-
Synthetic image embeddings: The team also trains diffusion models to convert images into compact numerical representations (embeddings). These synthetic image embeddings can be paired with the synthetic captions to create new training data for the VLM.
By combining these synthetic data sources, the Synth² method aims to boost the performance of visual-language models on tasks like image captioning and visual question answering. The key idea is that the synthetic data can expose the VLM to a broader range of image-text relationships, complementing the real training data.
Technical Explanation
The core of the Synth² approach consists of two components:
-
Synthetic Captions: The researchers use a large pre-trained language model, such as GPT-3, to generate synthetic captions for images. This is done by prompting the language model with the image and asking it to produce a natural language description of the content. These synthetic captions are then used as additional training data for the VLM.
-
Synthetic Image Embeddings: To further leverage the power of large language models, the team trains a diffusion model to convert images into numerical embeddings. This diffusion model is trained on real image-caption pairs, allowing it to learn a mapping between visual information and textual representations. The synthetic image embeddings produced by this model can then be paired with the synthetic captions to create new training examples for the VLM.
The researchers evaluate the Synth² approach on standard VLM benchmarks, including image captioning and visual question answering tasks. They demonstrate that incorporating the synthetic data sources can lead to significant performance improvements, outperforming baseline models that only use real training data.
The key insight behind Synth² is that large language models and diffusion models can be leveraged to generate high-quality synthetic data that complements the real training data available for VLMs. By exposing the VLM to a broader range of image-text relationships during training, the model can learn more robust and generalizable representations.
Critical Analysis
The Synth² approach presents an innovative way to harness the power of large vision-language models using synthetic data. However, the paper does not address several potential limitations and areas for further research:
-
Data Quality: While the authors demonstrate the effectiveness of Synth² on standard benchmarks, the quality and realism of the synthetic data generated by the language and diffusion models are not thoroughly evaluated. More comprehensive assessments of the synthetic data's fidelity and diversity could help understand the approach's limitations and potential biases.
-
Generalization: The paper focuses on improving performance on existing VLM benchmarks, but it does not explore how well the Synth²-enhanced VLMs generalize to real-world applications or unseen domains. Further research is needed to assess the models' robustness and transferability.
-
Computational Costs: Training the language and diffusion models required for Synth² can be computationally expensive. The authors do not provide a detailed analysis of the training time and resource requirements, which could be an important practical consideration for deploying these techniques in production environments.
-
Ethical Implications: As with any data augmentation technique, the potential for improving face generation quality with prompt-following synthetic data should be carefully considered. Potential biases or misrepresentations in the synthetic data could be amplified when used to train VLMs, leading to fairness and accountability issues.
Overall, the Synth² approach is a promising direction for enhancing visual-language models, but further research is needed to fully understand its limitations and potential real-world implications.
Conclusion
The Synth² technique presented in this paper offers a novel way to boost the performance of visual-language models by incorporating synthetic captions and image embeddings. By leveraging the capabilities of large pre-trained language models and diffusion models, the researchers demonstrate significant improvements on benchmark tasks like image captioning and visual question answering.
While the Synth² approach shows promise, there are still open questions and areas for further exploration, such as the quality and generalization of the synthetic data, the computational costs, and the potential ethical implications. Nonetheless, this work represents an exciting step forward in the ongoing efforts to harness the power of large vision-language models and push the boundaries of what's possible in the field of AI-powered visual understanding and language generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
4/4/2024
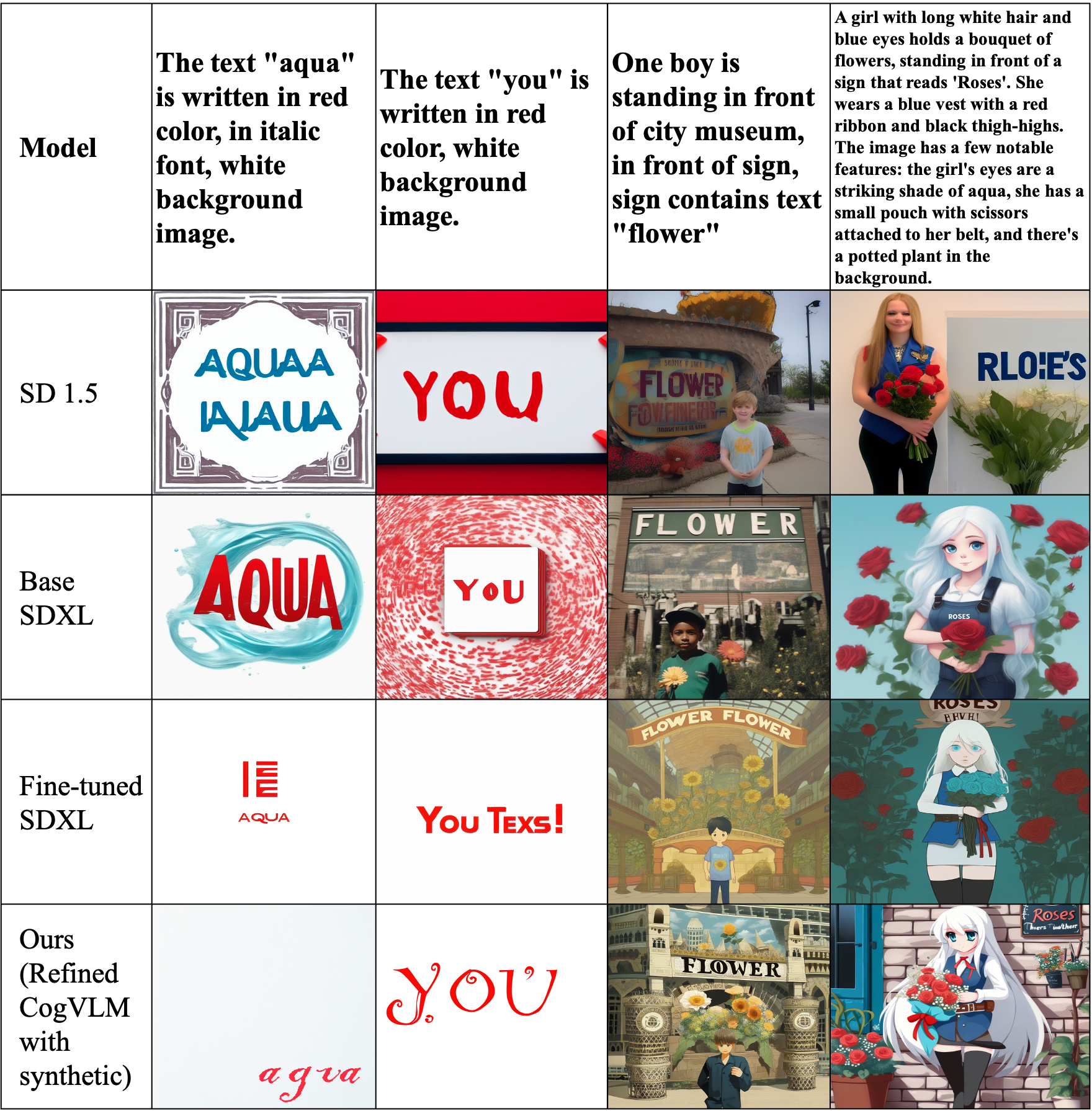
Improving Text Generation on Images with Synthetic Captions
Jun Young Koh, Sang Hyun Park, Joy Song
0
0
The recent emergence of latent diffusion models such as SDXL and SD 1.5 has shown significant capability in generating highly detailed and realistic images. Despite their remarkable ability to produce images, generating accurate text within images still remains a challenging task. In this paper, we examine the validity of fine-tuning approaches in generating legible text within the image. We propose a low-cost approach by leveraging SDXL without any time-consuming training on large-scale datasets. The proposed strategy employs a fine-tuning technique that examines the effects of data refinement levels and synthetic captions. Moreover, our results demonstrate how our small scale fine-tuning approach can improve the accuracy of text generation in different scenarios without the need of additional multimodal encoders. Our experiments show that with the addition of random letters to our raw dataset, our model's performance improves in producing well-formed visual text.
6/4/2024

Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
0
0
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
4/17/2024

Improving Text Embeddings with Large Language Models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei
0
0
In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across 93 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.
6/3/2024