Retrieval-Augmented Open-Vocabulary Object Detection
2404.05687
0
0

Abstract
Open-vocabulary object detection (OVD) has been studied with Vision-Language Models (VLMs) to detect novel objects beyond the pre-trained categories. Previous approaches improve the generalization ability to expand the knowledge of the detector, using 'positive' pseudo-labels with additional 'class' names, e.g., sock, iPod, and alligator. To extend the previous methods in two aspects, we propose Retrieval-Augmented Losses and visual Features (RALF). Our method retrieves related 'negative' classes and augments loss functions. Also, visual features are augmented with 'verbalized concepts' of classes, e.g., worn on the feet, handheld music player, and sharp teeth. Specifically, RALF consists of two modules: Retrieval Augmented Losses (RAL) and Retrieval-Augmented visual Features (RAF). RAL constitutes two losses reflecting the semantic similarity with negative vocabularies. In addition, RAF augments visual features with the verbalized concepts from a large language model (LLM). Our experiments demonstrate the effectiveness of RALF on COCO and LVIS benchmark datasets. We achieve improvement up to 3.4 box AP$
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a "retrieval-augmented" approach to open-vocabulary object detection, which aims to address the challenge of recognizing objects that are not in the training dataset.
- The key idea is to leverage a large-scale image-text retrieval model to retrieve visually similar images and their associated text descriptions, and then use this information to aid the object detection process.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improved performance compared to purely learning-based approaches.
Plain English Explanation
In traditional object detection systems, the algorithms are trained on a fixed set of object categories. This means they can only recognize objects that they have been explicitly taught to identify. However, in the real world, there are countless objects that may not be included in the training data.
The researchers in this paper have developed a new approach to address this limitation. Their "retrieval-augmented" system uses a large database of images and text descriptions to supplement the object detection process. When the system encounters an object it doesn't recognize, it can search this database to find visually similar images and their corresponding text descriptions. This additional information can then be used to help the system identify the unknown object.
This is an important advance because it allows the object detection system to work with a much broader range of objects, not just the ones it was originally trained on. By tapping into a vast repository of visual and textual knowledge, the system can become more flexible and adaptable to the diverse objects found in the real world.
The researchers show that their retrieval-augmented approach outperforms purely learning-based object detection methods on several standard benchmark datasets. This suggests that leveraging large-scale retrieval models is a promising direction for building more open-vocabulary object detection systems.
Technical Explanation
The core of the researchers' approach is a two-stage object detection pipeline. First, a region proposal network generates bounding box proposals for potential objects in the image. Then, a classification and regression network is used to classify and localize the objects within those proposals.
To augment this traditional pipeline, the researchers introduce a "retrieval module" that operates in parallel. This module takes the image features and the bounding box proposals as input, and uses a large-scale image-text retrieval model to find visually similar images from a reference database. The text descriptions associated with these retrieved images are then used to provide additional semantic information to the classification network.
The authors experiment with different ways of integrating the retrieval module's output, such as concatenating the retrieved text embeddings with the object features or using the retrieved text to guide the objectness scoring. Their results show that the retrieval-augmented approach outperforms purely learning-based object detectors, particularly for objects that are not well represented in the training data.
Critical Analysis
One potential limitation of this work is the reliance on a large-scale reference database of images and text. The performance of the retrieval module is likely to be heavily dependent on the quality and coverage of this database. If the database is missing relevant visual and textual information, the retrieval-augmented system may still struggle with certain unknown objects.
Additionally, the authors do not provide a thorough analysis of the failure cases or edge cases of their approach. It would be helpful to understand the types of objects or scenarios where the retrieval-augmented system still struggles, and what the underlying causes might be.
That said, the core idea of leveraging large-scale retrieval models to enhance object detection is a promising direction. As language models and visual-language systems continue to advance, the potential for such hybrid approaches to open-vocabulary object detection will likely grow.
Conclusion
This paper presents a novel "retrieval-augmented" approach to open-vocabulary object detection, which leverages large-scale image-text retrieval models to supplement the object recognition process. By tapping into a vast database of visual and textual knowledge, the system can identify a much broader range of objects than traditional learning-based detectors.
The researchers demonstrate the effectiveness of their approach on several benchmark datasets, showing improved performance compared to purely learning-based methods. While the reliance on a reference database is a potential limitation, the core idea of combining retrieval and learning for open-vocabulary object detection is a promising direction for future research in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
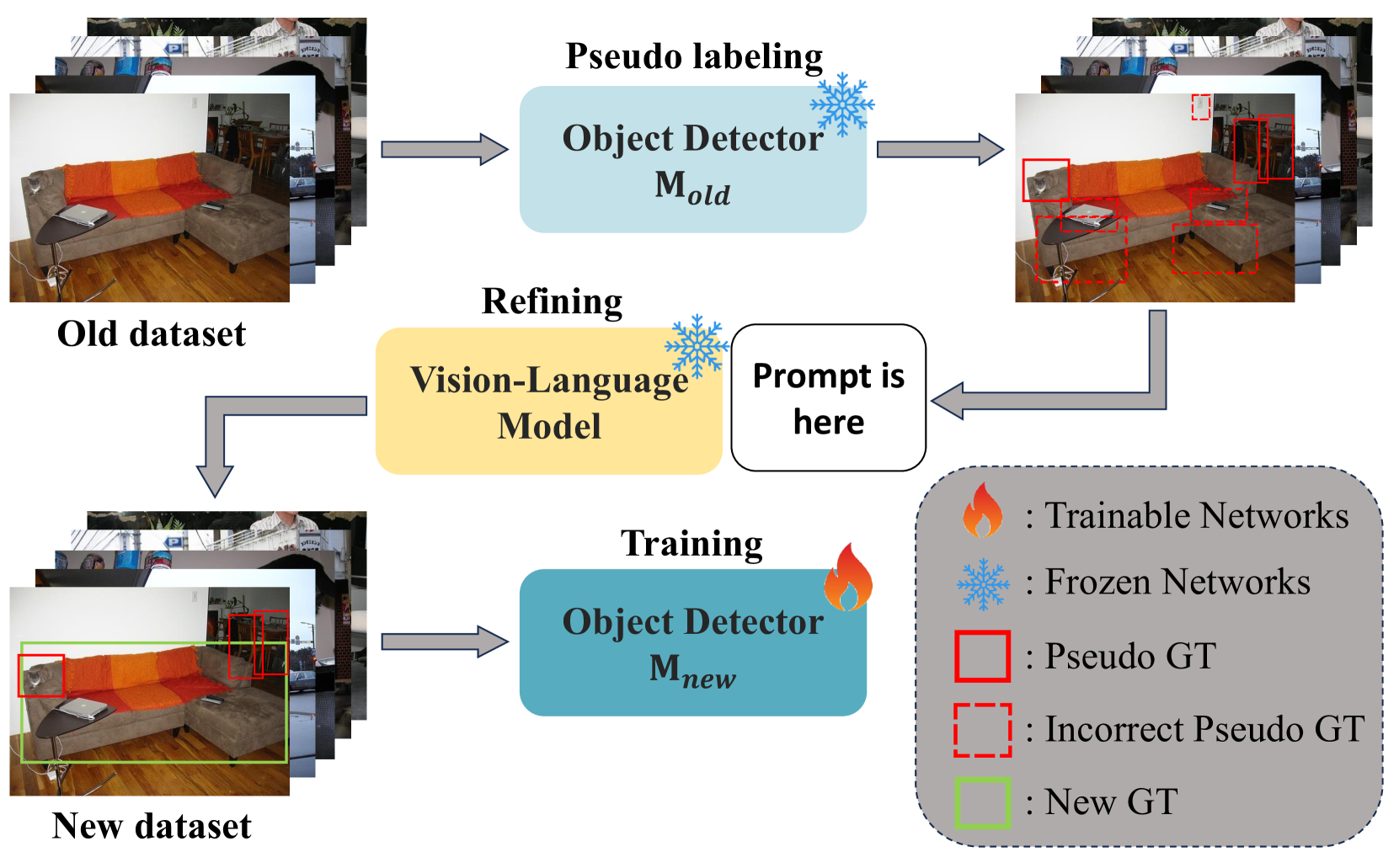
VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
Junsu Kim, Yunhoe Ku, Jihyeon Kim, Junuk Cha, Seungryul Baek
0
0
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
5/10/2024
🛸
Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation
Daichi Horita, Naoto Inoue, Kotaro Kikuchi, Kota Yamaguchi, Kiyoharu Aizawa
0
0
Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield high-quality layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.
4/17/2024
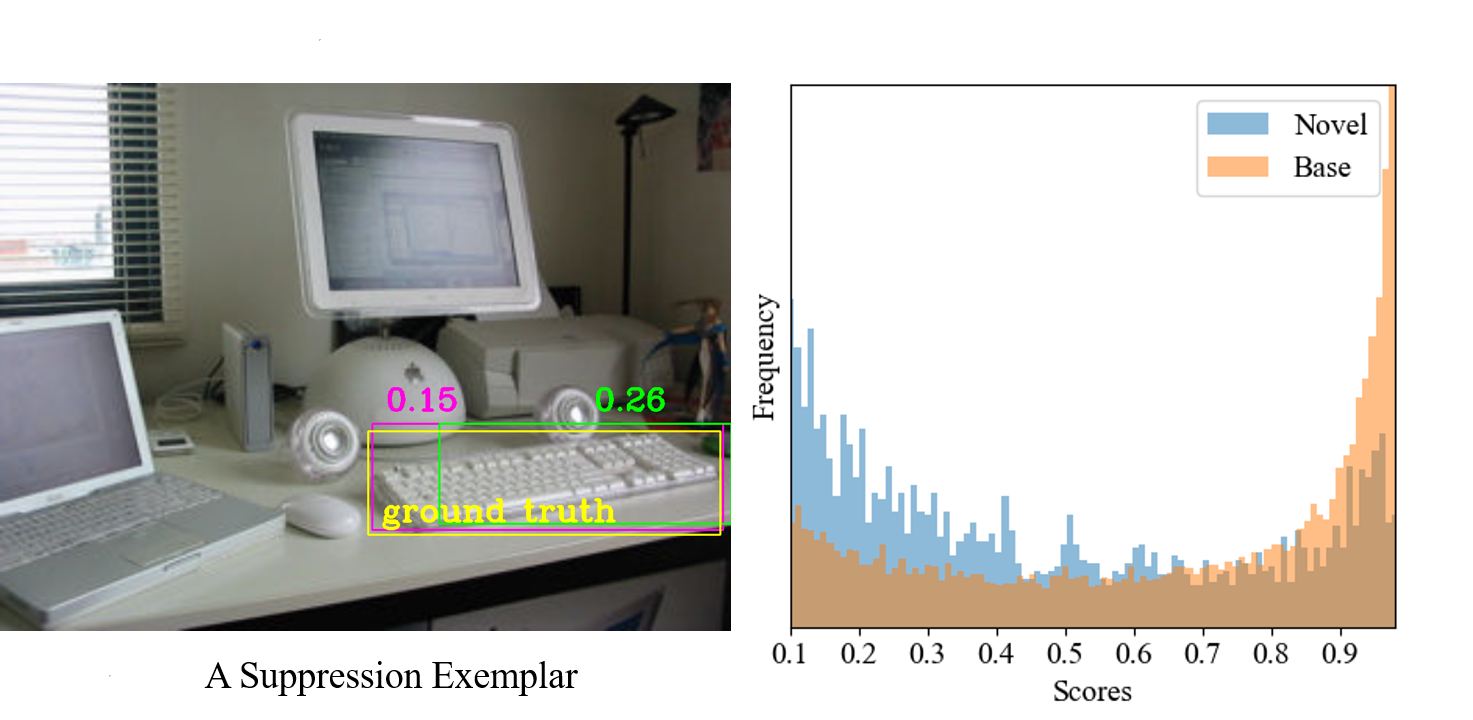
Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation
Yanhao Zheng, Kai Liu
0
0
Open-vocabulary object detection (OVOD) aims at localizing and recognizing visual objects from novel classes unseen at the training time. Whereas, empirical studies reveal that advanced detectors generally assign lower scores to those novel instances, which are inadvertently suppressed during inference by commonly adopted greedy strategies like Non-Maximum Suppression (NMS), leading to sub-optimal detection performance for novel classes. This paper systematically investigates this problem with the commonly-adopted two-stage OVOD paradigm. Specifically, in the region-proposal stage, proposals that contain novel instances showcase lower objectness scores, since they are treated as background proposals during the training phase. Meanwhile, in the object-classification stage, novel objects share lower region-text similarities (i.e., classification scores) due to the biased visual-language alignment by seen training samples. To alleviate this problem, this paper introduces two advanced measures to adjust confidence scores and conserve erroneously dismissed objects: (1) a class-agnostic localization quality estimate via overlap degree of region/object proposals, and (2) a text-guided visual similarity estimate with proxy prototypes for novel classes. Integrated with adjusting techniques specifically designed for the region-proposal and object-classification stages, this paper derives the aggregated confidence estimate for the open-vocabulary object detection paradigm (AggDet). Our AggDet is a generic and training-free post-processing scheme, which consistently bolsters open-vocabulary detectors across model scales and architecture designs. For instance, AggDet receives 3.3% and 1.5% gains on OV-COCO and OV-LVIS benchmarks respectively, without any training cost.
4/15/2024
🤔
Understanding Retrieval-Augmented Task Adaptation for Vision-Language Models
Yifei Ming, Yixuan Li
0
0
Pre-trained contrastive vision-language models have demonstrated remarkable performance across a wide range of tasks. However, they often struggle on fine-trained datasets with categories not adequately represented during pre-training, which makes adaptation necessary. Recent works have shown promising results by utilizing samples from web-scale databases for retrieval-augmented adaptation, especially in low-data regimes. Despite the empirical success, understanding how retrieval impacts the adaptation of vision-language models remains an open research question. In this work, we adopt a reflective perspective by presenting a systematic study to understand the roles of key components in retrieval-augmented adaptation. We unveil new insights on uni-modal and cross-modal retrieval and highlight the critical role of logit ensemble for effective adaptation. We further present theoretical underpinnings that directly support our empirical observations.
5/3/2024