EventChat: Implementation and user-centric evaluation of a large language model-driven conversational recommender system for exploring leisure events in an SME context

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have great potential for improving conversational recommender systems (CRS)
- Most research has focused on technical frameworks rather than end-user evaluations or strategic implications for businesses, especially small and medium enterprises (SMEs)
- This paper examines the design and performance of an LLM-driven CRS in an SME setting, including both objective metrics and user feedback
- The authors also introduce a revised ResQue model for evaluating LLM-driven CRS
Plain English Explanation
Conversational recommender systems (CRS) are a type of technology that can suggest products or services to users through natural language interactions, like a conversation. Large language models (LLMs) are a powerful new type of artificial intelligence that could greatly improve CRS, making them more natural and effective.
However, most research on LLM-driven CRS has focused on the technical details of how to build these systems, rather than understanding how well they actually work for real users or how businesses could benefit from them. This paper looks at deploying an LLM-driven CRS in a small or medium-sized business (SME) setting, and evaluates it both objectively (using metrics like accuracy) and based on user feedback.
The researchers also developed a simplified version of an existing model for evaluating LLM-driven CRS, which could help other researchers study these systems in a consistent way as the technology rapidly evolves.
The results show the LLM-driven CRS performed reasonably well, with 85.5% recommendation accuracy. However, there were some significant challenges, like high costs per interaction and long response times, that could make it difficult for SMEs to use this technology effectively. The paper discusses the trade-offs and strategic considerations for SMEs looking to deploy an LLM-driven CRS.
Technical Explanation
The paper describes the design and evaluation of an LLM-driven CRS deployed in an SME setting. The core architecture uses a retrieval-augmented generation (RAG) technique, where an LLM is used as a ranker to select relevant items from a product database.
In their experiments, the researchers tested this system using both objective metrics and subjective user evaluations. The objective metrics included recommendation accuracy (85.5%), latency (5.7 seconds), and cost per interaction ($0.04). User feedback was collected using a revised version of the ResQue evaluation model.
The results highlight several key challenges with deploying LLM-driven CRS in an SME context. The high latency and cost, primarily driven by the use of an advanced LLM as the ranker, emerged as major obstacles to achieving a user-friendly and cost-effective system.
The authors also found that relying solely on approaches like prompt-based learning with ChatGPT made it difficult to achieve satisfactory quality in a production environment. This underscores the need for continued research and development to address the technical limitations of current LLM-driven CRS.
Critical Analysis
The paper provides a valuable, real-world assessment of the challenges in deploying LLM-driven CRS, particularly for SMEs. The authors acknowledge several limitations and areas for further research, including:
- The need for more extensive user evaluations to fully understand the user experience
- Potential biases or inconsistencies in the revised ResQue model used for evaluation
- The potential for improvements in LLM efficiency and cost-effectiveness over time
One area the paper does not explore in depth is the impact of the specific LLM used as the ranker. It's possible that using a different LLM or a more specialized model could lead to better performance in terms of latency, cost, and quality.
Additionally, the paper does not consider the potential for hybrid approaches that combine LLMs with other recommendation techniques, which could help address some of the identified challenges.
Overall, the paper provides a thoughtful and nuanced analysis of the current state of LLM-driven CRS, highlighting the importance of considering real-world business and user constraints, not just technical capabilities.
Conclusion
This paper offers valuable insights into the practical implementation and evaluation of LLM-driven conversational recommender systems, particularly in the context of small and medium-sized enterprises.
While the LLM-driven CRS demonstrated promising performance in terms of recommendation accuracy, the significant challenges around latency, cost, and quality underscore the need for continued research and development to make this technology more user-friendly and economically viable for SMEs.
The revised ResQue evaluation model introduced by the authors could help facilitate more consistent and replicable studies in this rapidly evolving field. Ultimately, this paper highlights the importance of considering end-user needs and business constraints when designing and deploying cutting-edge AI technologies like LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
EventChat: Implementation and user-centric evaluation of a large language model-driven conversational recommender system for exploring leisure events in an SME context
Hannes Kunstmann, Joseph Ollier, Joel Persson, Florian von Wangenheim
Large language models (LLMs) present an enormous evolution in the strategic potential of conversational recommender systems (CRS). Yet to date, research has predominantly focused upon technical frameworks to implement LLM-driven CRS, rather than end-user evaluations or strategic implications for firms, particularly from the perspective of a small to medium enterprises (SME) that makeup the bedrock of the global economy. In the current paper, we detail the design of an LLM-driven CRS in an SME setting, and its subsequent performance in the field using both objective system metrics and subjective user evaluations. While doing so, we additionally outline a short-form revised ResQue model for evaluating LLM-driven CRS, enabling replicability in a rapidly evolving field. Our results reveal good system performance from a user experience perspective (85.5% recommendation accuracy) but underscore latency, cost, and quality issues challenging business viability. Notably, with a median cost of $0.04 per interaction and a latency of 5.7s, cost-effectiveness and response time emerge as crucial areas for achieving a more user-friendly and economically viable LLM-driven CRS for SME settings. One major driver of these costs is the use of an advanced LLM as a ranker within the retrieval-augmented generation (RAG) technique. Our results additionally indicate that relying solely on approaches such as Prompt-based learning with ChatGPT as the underlying LLM makes it challenging to achieve satisfying quality in a production environment. Strategic considerations for SMEs deploying an LLM-driven CRS are outlined, particularly considering trade-offs in the current technical landscape.
Read more7/10/2024
0
Large Language Model Driven Recommendation
Anton Korikov, Scott Sanner, Yashar Deldjoo, Zhankui He, Julian McAuley, Arnau Ramisa, Rene Vidal, Mahesh Sathiamoorthy, Atoosa Kasrizadeh, Silvia Milano, Francesco Ricci
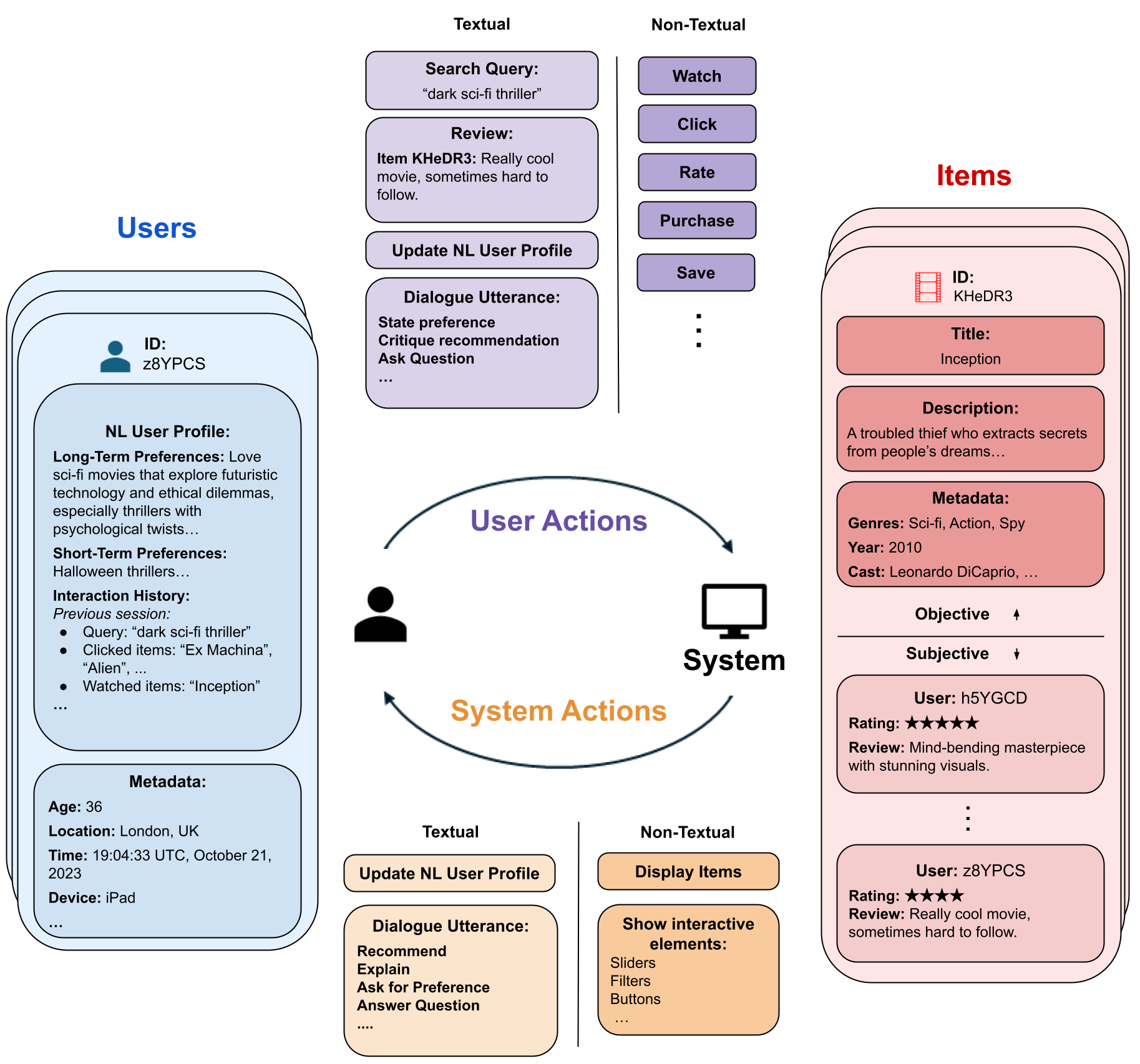
While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
Read more8/21/2024
🤔
0
Incorporating External Knowledge and Goal Guidance for LLM-based Conversational Recommender Systems
Chuang Li, Yang Deng, Hengchang Hu, Min-Yen Kan, Haizhou Li
This paper aims to efficiently enable large language models (LLMs) to use external knowledge and goal guidance in conversational recommender system (CRS) tasks. Advanced LLMs (e.g., ChatGPT) are limited in domain-specific CRS tasks for 1) generating grounded responses with recommendation-oriented knowledge, or 2) proactively leading the conversations through different dialogue goals. In this work, we first analyze those limitations through a comprehensive evaluation, showing the necessity of external knowledge and goal guidance which contribute significantly to the recommendation accuracy and language quality. In light of this finding, we propose a novel ChatCRS framework to decompose the complex CRS task into several sub-tasks through the implementation of 1) a knowledge retrieval agent using a tool-augmented approach to reason over external Knowledge Bases and 2) a goal-planning agent for dialogue goal prediction. Experimental results on two multi-goal CRS datasets reveal that ChatCRS sets new state-of-the-art benchmarks, improving language quality of informativeness by 17% and proactivity by 27%, and achieving a tenfold enhancement in recommendation accuracy.
Read more5/6/2024
0
Large Language Models as Conversational Movie Recommenders: A User Study
Ruixuan Sun, Xinyi Li, Avinash Akella, Joseph A. Konstan
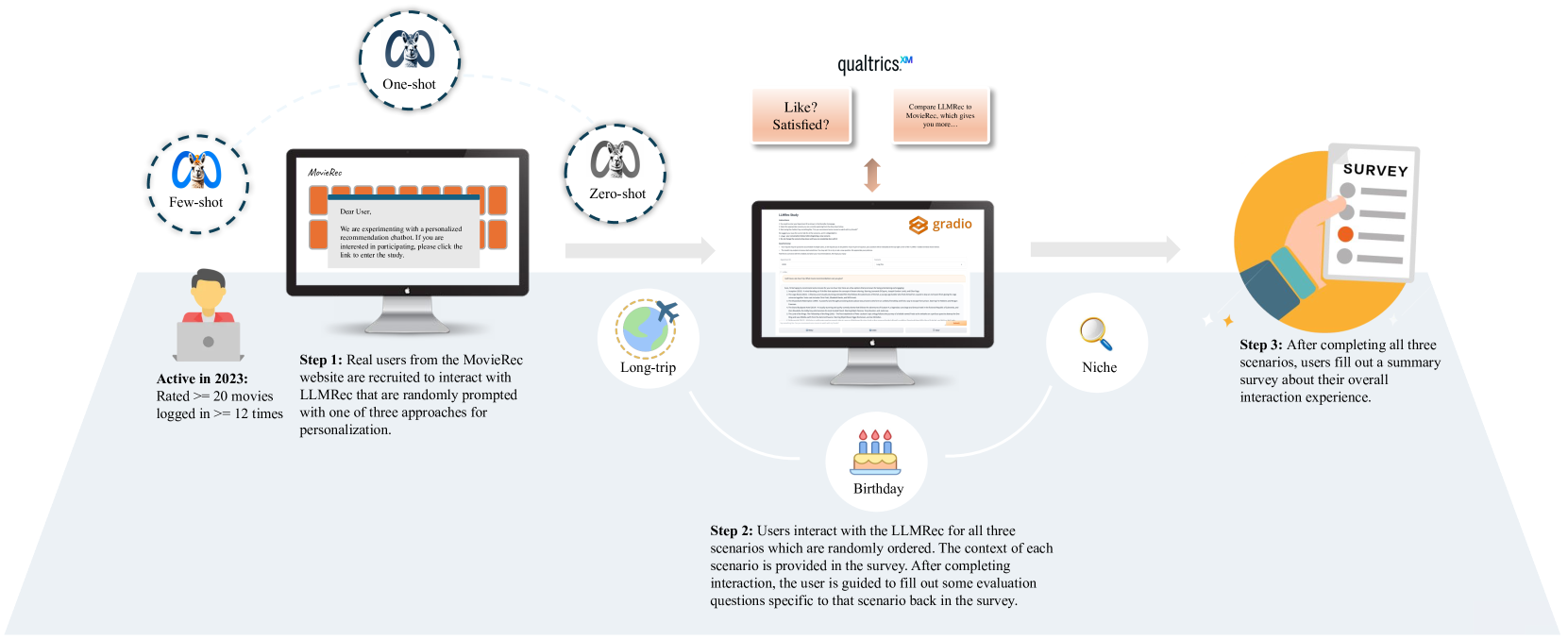
This paper explores the effectiveness of using large language models (LLMs) for personalized movie recommendations from users' perspectives in an online field experiment. Our study involves a combination of between-subject prompt and historic consumption assessments, along with within-subject recommendation scenario evaluations. By examining conversation and survey response data from 160 active users, we find that LLMs offer strong recommendation explainability but lack overall personalization, diversity, and user trust. Our results also indicate that different personalized prompting techniques do not significantly affect user-perceived recommendation quality, but the number of movies a user has watched plays a more significant role. Furthermore, LLMs show a greater ability to recommend lesser-known or niche movies. Through qualitative analysis, we identify key conversational patterns linked to positive and negative user interaction experiences and conclude that providing personal context and examples is crucial for obtaining high-quality recommendations from LLMs.
Read more5/1/2024