Large Language Models Make Sample-Efficient Recommender Systems
2406.02368
0
0
Abstract
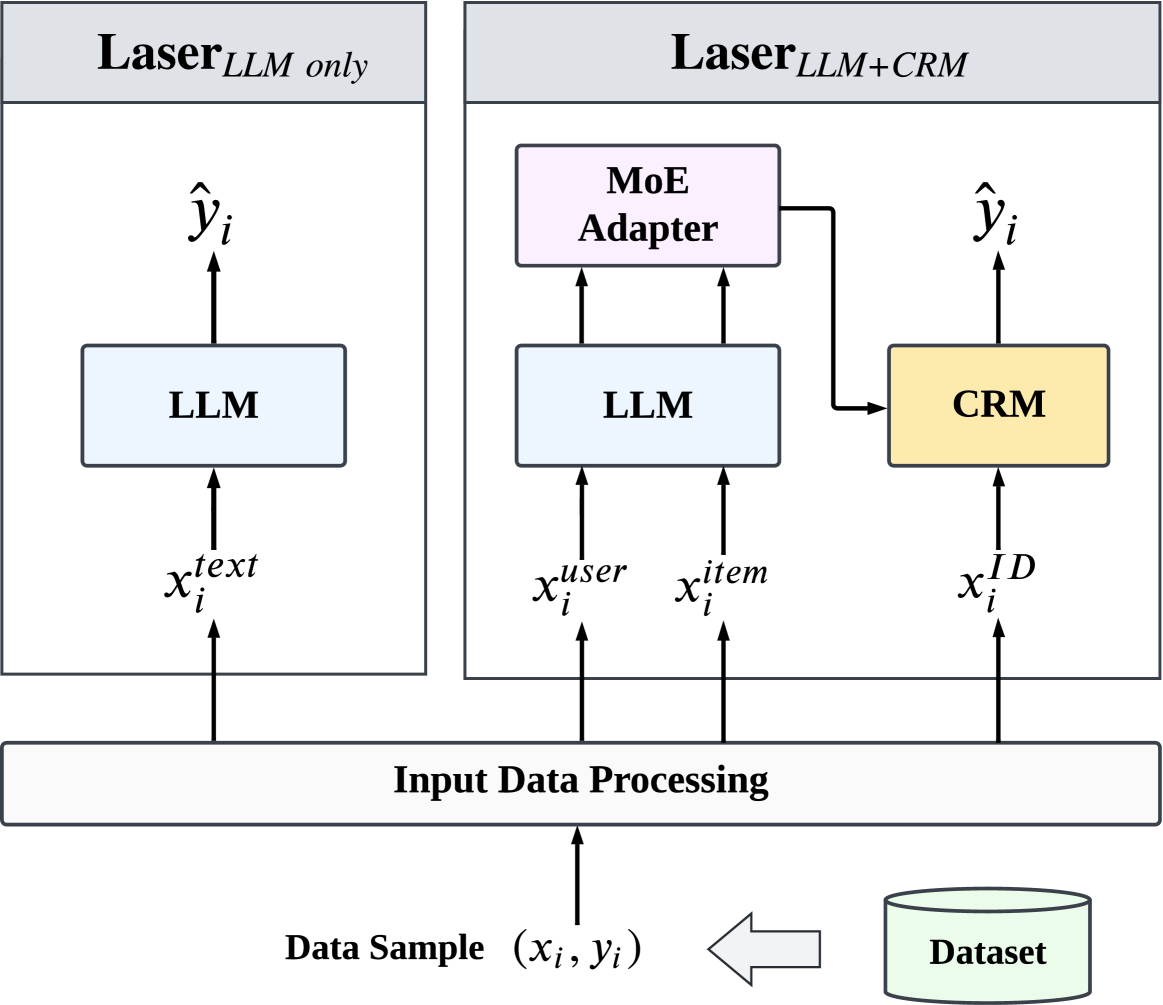
Large language models (LLMs) have achieved remarkable progress in the field of natural language processing (NLP), demonstrating remarkable abilities in producing text that resembles human language for various tasks. This opens up new opportunities for employing them in recommender systems (RSs). In this paper, we specifically examine the sample efficiency of LLM-enhanced recommender systems, which pertains to the model's capacity to attain superior performance with a limited quantity of training data. Conventional recommendation models (CRMs) often need a large amount of training data because of the sparsity of features and interactions. Hence, we propose and verify our core viewpoint: Large Language Models Make Sample-Efficient Recommender Systems. We propose a simple yet effective framework (i.e., Laser) to validate the viewpoint from two aspects: (1) LLMs themselves are sample-efficient recommenders; and (2) LLMs, as feature generators and encoders, make CRMs more sample-efficient. Extensive experiments on two public datasets show that Laser requires only a small fraction of training samples to match or even surpass CRMs that are trained on the entire training set, demonstrating superior sample efficiency.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can be used to build highly efficient recommender systems.
- The researchers demonstrate that LLMs can learn effective recommendation policies from just a few examples, making them much more sample-efficient than traditional recommender systems.
- The paper presents several experiments and case studies showing the effectiveness of LLM-based recommender systems in various domains, including movie recommendations, collaborative filtering, and conversational recommendations.
Plain English Explanation
Recommender systems are algorithms that suggest products, content, or information to users based on their preferences and behavior. Traditional recommender systems often require large amounts of data to learn effective recommendation policies. This can be a challenge, especially for new products or services with limited user data.
The researchers in this paper show that large language models (LLMs) can be used to build highly efficient recommender systems that require much less data to learn effective recommendations. LLMs are powerful machine learning models that can understand and generate human-like text. The researchers demonstrate that by fine-tuning LLMs on just a few examples of user preferences and item information, they can learn to make accurate recommendations.
For example, in one experiment, the researchers used an LLM to make movie recommendations. The LLM was trained on a small dataset of movie reviews and ratings, and it was able to learn to recommend movies that users would likely enjoy based on their preferences. This is much more efficient than traditional movie recommendation systems, which often require large datasets of user ratings and behaviors to learn effective recommendation policies.
The researchers also show that LLM-based recommender systems can be used for other types of recommendations, such as collaborative filtering and conversational recommendations. In each case, the LLM-based systems demonstrated impressive performance while requiring much less data than traditional approaches.
Overall, this research suggests that LLMs can revolutionize the field of recommender systems by enabling highly efficient and effective recommendations with much less data.
Technical Explanation
The paper presents several experiments and case studies demonstrating the effectiveness of using large language models (LLMs) for building sample-efficient recommender systems.
In the first experiment, the researchers fine-tuned the GPT-2 LLM on a small dataset of movie reviews and ratings. They then used the fine-tuned model to generate movie recommendations for users based on their preferences. The results showed that the LLM-based recommender system significantly outperformed traditional collaborative filtering approaches in terms of recommendation accuracy, while requiring much less training data.
The researchers also explored the use of LLMs for collaborative filtering, where the model learns to make recommendations based on the preferences of similar users. They found that by encoding user and item information into the LLM's language model, they could achieve high-quality recommendations with just a few examples of user-item interactions.
Additionally, the paper presents a case study on using LLMs for conversational movie recommendations. In this scenario, the LLM is fine-tuned to engage in natural language conversations with users to understand their preferences and make personalized movie recommendations.
The key insight behind the success of these LLM-based recommender systems is that the language model's ability to learn and generalize from a small number of examples can be leveraged to make highly efficient recommendations. By encoding user and item information into the LLM's language model, the researchers were able to capture the underlying patterns and relationships that drive effective recommendations, without requiring large datasets.
Critical Analysis
The paper provides a compelling demonstration of how large language models can be leveraged to build sample-efficient recommender systems. The researchers' experiments and case studies show impressive results, suggesting that LLMs could indeed revolutionize the field of recommender systems.
However, the paper does not address several potential limitations and areas for further research. For instance, the paper does not explore the scalability of these LLM-based approaches as the size of the user and item spaces grows. It's unclear how well the LLM-based systems would perform in real-world scenarios with millions or billions of users and items.
Additionally, the paper does not delve into the interpretability and explainability of the LLM-based recommendations. While the systems may be highly accurate, it's important to understand the reasoning behind the recommendations, especially in sensitive domains like healthcare or financial services.
Furthermore, the paper does not address potential biases and fairness issues that may arise from using LLMs for recommendations. LLMs can sometimes reflect societal biases present in their training data, which could lead to unfair or discriminatory recommendations.
Despite these limitations, the research presented in this paper represents an important step forward in the field of recommender systems. The authors have demonstrated the potential of large language models to enable highly efficient and effective recommendations, and their work provides a strong foundation for future research and development in this area.
Conclusion
This paper presents a compelling case for using large language models (LLMs) to build highly efficient and effective recommender systems. The researchers have demonstrated that by fine-tuning LLMs on just a few examples of user preferences and item information, they can learn to make accurate recommendations across a range of domains, including movies, collaborative filtering, and conversational recommendations.
The key advantage of the LLM-based approach is its sample efficiency, which allows recommender systems to be built with much less data than traditional approaches. This could be particularly valuable for new products or services with limited user data, as well as in domains where data privacy is a concern.
While the paper does not address all potential limitations and areas for further research, it represents an important step forward in the field of recommender systems. As LLMs continue to evolve and become more accessible, the techniques presented in this paper could pave the way for a new generation of highly efficient and personalized recommender systems that can better serve the needs of users and businesses alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
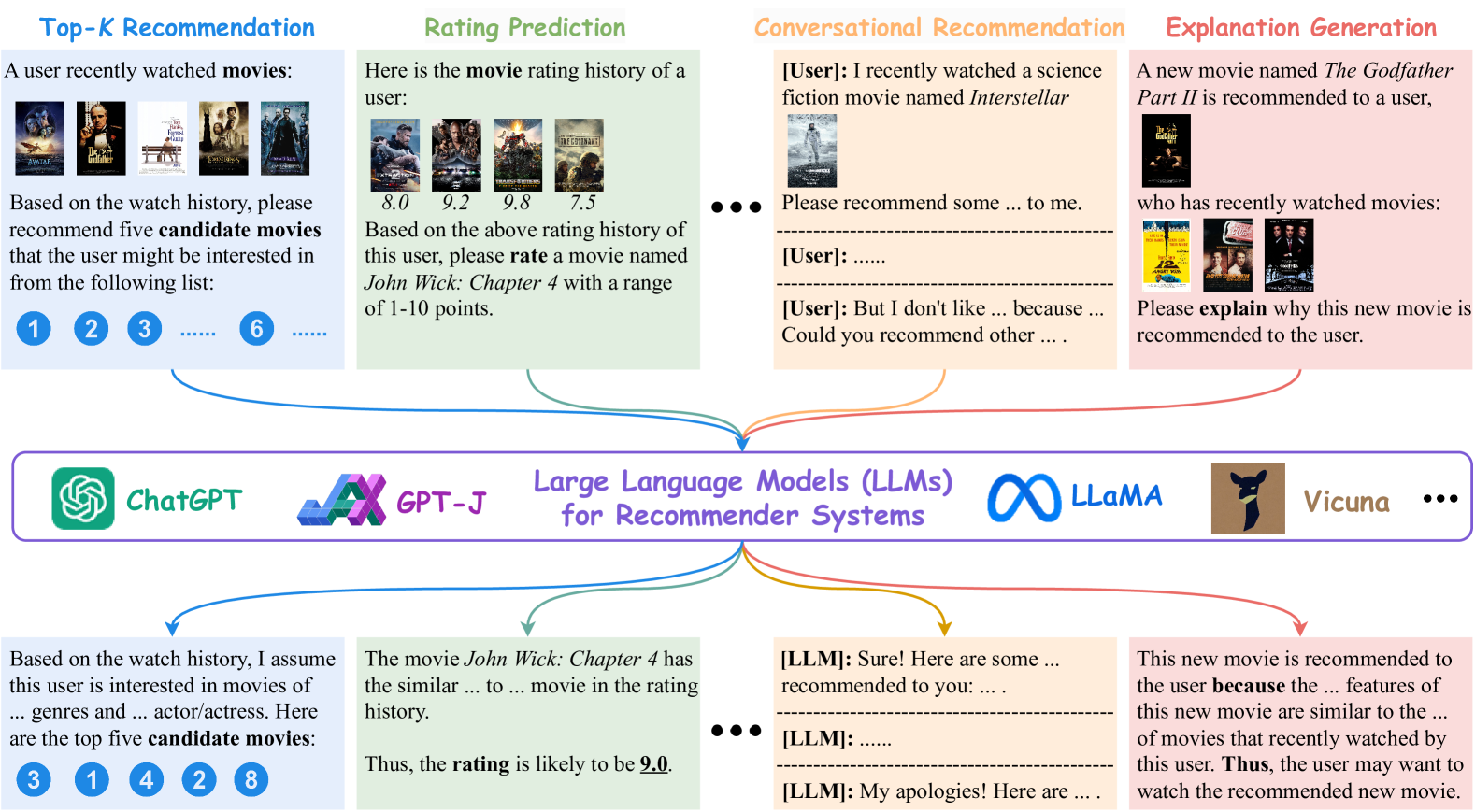
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
💬
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Wenlin Zhang, Chuhan Wu, Xiangyang Li, Yuhao Wang, Kuicai Dong, Yichao Wang, Xinyi Dai, Xiangyu Zhao, Huifeng Guo, Ruiming Tang
0
0
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
4/9/2024
Large Language Models as Conversational Movie Recommenders: A User Study
Ruixuan Sun, Xinyi Li, Avinash Akella, Joseph A. Konstan
0
0
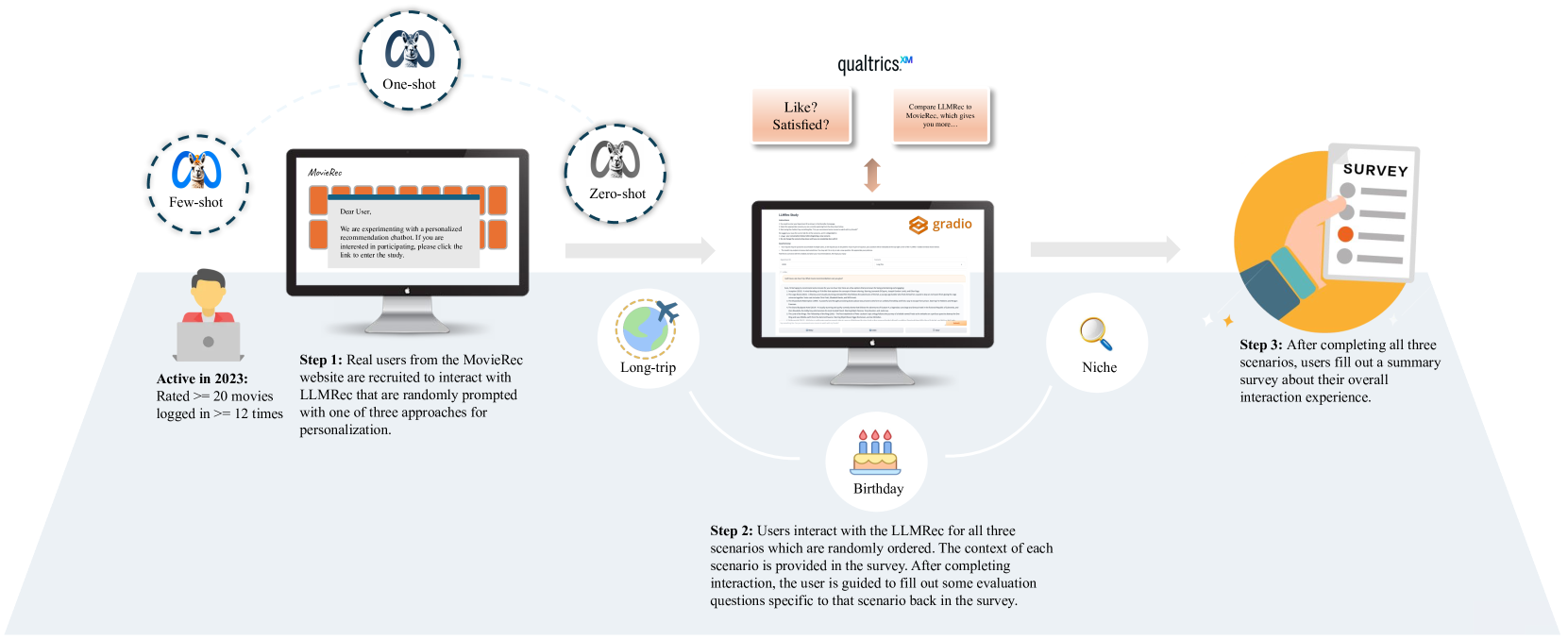
This paper explores the effectiveness of using large language models (LLMs) for personalized movie recommendations from users' perspectives in an online field experiment. Our study involves a combination of between-subject prompt and historic consumption assessments, along with within-subject recommendation scenario evaluations. By examining conversation and survey response data from 160 active users, we find that LLMs offer strong recommendation explainability but lack overall personalization, diversity, and user trust. Our results also indicate that different personalized prompting techniques do not significantly affect user-perceived recommendation quality, but the number of movies a user has watched plays a more significant role. Furthermore, LLMs show a greater ability to recommend lesser-known or niche movies. Through qualitative analysis, we identify key conversational patterns linked to positive and negative user interaction experiences and conclude that providing personal context and examples is crucial for obtaining high-quality recommendations from LLMs.
5/1/2024