The Evolution of Multimodal Model Architectures

0
Sign in to get full access
Overview
- This paper provides a comprehensive taxonomy of multimodal model architectures, categorizing them into different types based on the level of integration between the input modalities.
- The authors trace the evolution of multimodal models from early approaches that treated modalities separately to more recent models that tightly integrate them.
- The paper covers a wide range of applications and highlights key insights and research directions in the field of multimodal learning.
Plain English Explanation
Multimodal models are a type of artificial intelligence that can process and combine different types of information, such as text, images, or audio. This paper examines how these models have evolved over time, becoming increasingly sophisticated in the way they integrate and make use of multiple data sources.
The paper starts by reviewing the history of multimodal models, explaining how early approaches treated each modality (or data type) separately, before more recent models began to tightly integrate the different inputs. This allows the models to learn richer representations and make more informed decisions.
The authors then present a detailed taxonomy, or classification system, that breaks down the different ways multimodal models can be structured. This ranges from simple models that combine modalities at the end of the process to more advanced architectures that tightly integrate the modalities throughout the entire model.
By understanding this evolution and the various architectural approaches, the paper provides a roadmap for researchers and developers working on pushing the boundaries of multimodal AI. It highlights important insights and points to promising areas for future exploration in this rapidly advancing field.
Technical Explanation
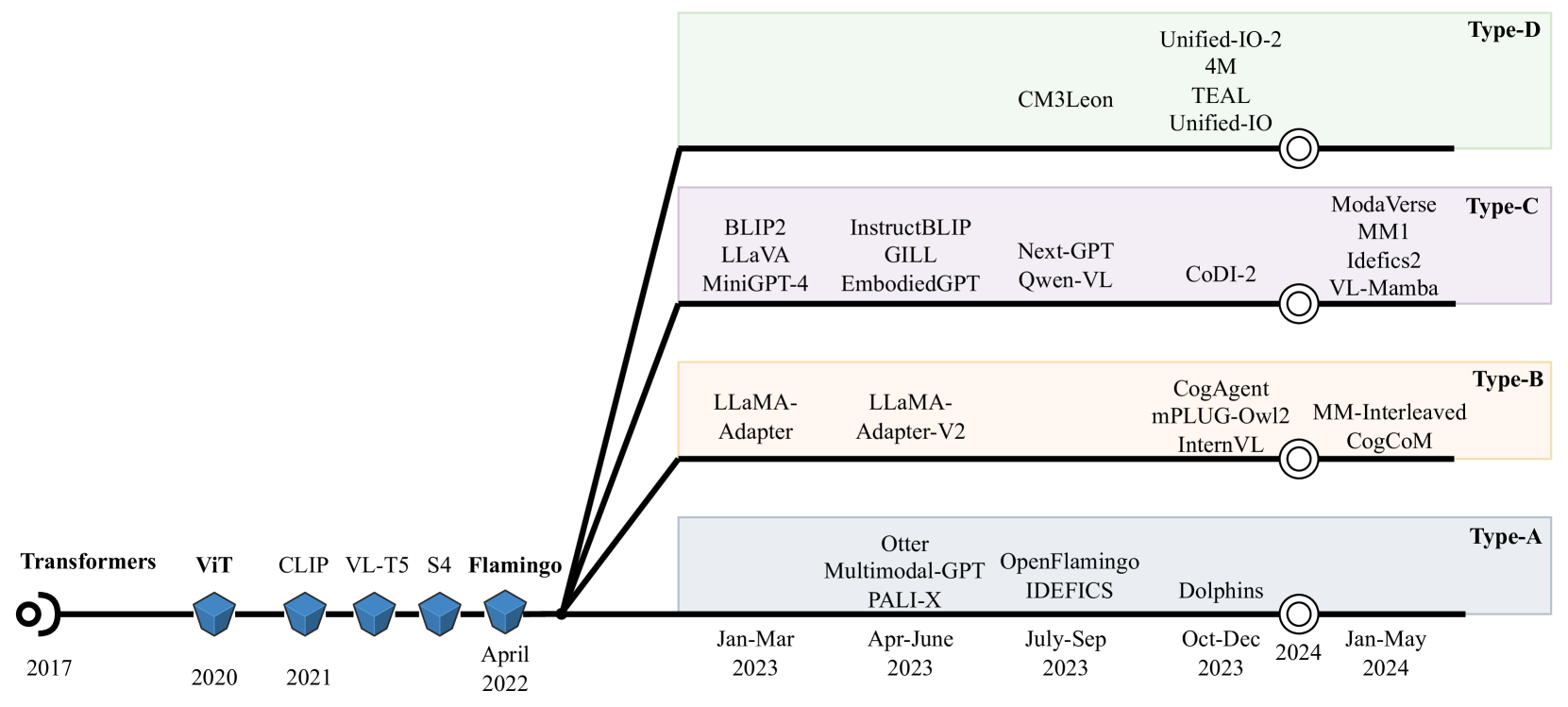
The paper presents a comprehensive taxonomy of multimodal model architectures, categorizing them based on the level of integration between the input modalities. The authors trace the evolution of these models from early approaches that treated modalities separately to more recent architectures that tightly integrate them.
The taxonomy begins with "early fusion" models, which combine modalities at the input level before feeding them into a shared processing pipeline. "Intermediate fusion" models integrate the modalities at various intermediate layers, allowing for more sophisticated interactions. "Late fusion" architectures maintain separate processing paths for each modality and only combine them towards the end of the model.
The authors then introduce "deep fusion" models, which use powerful neural network architectures like transformers to learn rich multimodal representations. These models can effectively capture cross-modal dependencies and dynamics to enhance performance on a wide range of multimodal tasks.
The paper also covers specialized architectures, such as modular and hierarchical models, that leverage the unique properties of different modalities to tackle complex problems. Throughout the taxonomy, the authors highlight key insights, current research trends, and promising directions for the field of multimodal machine learning.
Critical Analysis
The paper provides a thorough and well-structured overview of the evolution of multimodal model architectures. The taxonomy presented is comprehensive and should serve as a valuable reference for researchers and practitioners in the field.
One potential limitation of the paper is its focus on the architectural aspects of multimodal models, without delving deeper into the specific techniques and algorithms used within each category. Additionally, the paper does not extensively discuss the performance and real-world applicability of the different architectural approaches, which would be informative for readers.
Furthermore, the paper could have addressed some of the challenges and limitations associated with multimodal learning, such as the difficulties in handling missing or noisy data, cross-modal distribution shifts, and the interpretability of these complex models. Discussing these issues would help readers understand the practical considerations and potential areas for further research.
Despite these minor shortcomings, the paper is a valuable contribution to the field of multimodal machine learning. By providing a comprehensive taxonomy and tracing the evolution of these architectures, the authors have laid a solid foundation for researchers and developers to better understand the state of the art and identify promising directions for future work.
Conclusion
This paper offers a comprehensive taxonomy of multimodal model architectures, charting their evolution from early approaches that treated modalities separately to more recent models that tightly integrate them. By understanding this progression, researchers and developers can better navigate the rapidly advancing field of multimodal machine learning and identify promising areas for future exploration.
The paper highlights key insights, such as the importance of learning rich multimodal representations and effectively capturing cross-modal dependencies. These advancements have the potential to drive significant improvements in a wide range of applications, from multimodal human action recognition to machine translation.
By providing a comprehensive overview of the field, this paper serves as an invaluable resource for researchers and practitioners, guiding them in the pursuit of more powerful and versatile multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!