From CNNs to Transformers in Multimodal Human Action Recognition: A Survey
2405.15813
0
0
🤔
Abstract
Due to its widespread applications, human action recognition is one of the most widely studied research problems in Computer Vision. Recent studies have shown that addressing it using multimodal data leads to superior performance as compared to relying on a single data modality. During the adoption of deep learning for visual modelling in the last decade, action recognition approaches have mainly relied on Convolutional Neural Networks (CNNs). However, the recent rise of Transformers in visual modelling is now also causing a paradigm shift for the action recognition task. This survey captures this transition while focusing on Multimodal Human Action Recognition (MHAR). Unique to the induction of multimodal computational models is the process of fusing the features of the individual data modalities. Hence, we specifically focus on the fusion design aspects of the MHAR approaches. We analyze the classic and emerging techniques in this regard, while also highlighting the popular trends in the adaption of CNN and Transformer building blocks for the overall problem. In particular, we emphasize on recent design choices that have led to more efficient MHAR models. Unlike existing reviews, which discuss Human Action Recognition from a broad perspective, this survey is specifically aimed at pushing the boundaries of MHAR research by identifying promising architectural and fusion design choices to train practicable models. We also provide an outlook of the multimodal datasets from their scale and evaluation viewpoint. Finally, building on the reviewed literature, we discuss the challenges and future avenues for MHAR.
Create account to get full access
Overview
- Human action recognition is a widely studied problem in computer vision with many practical applications.
- Recent studies have shown that using multimodal data (i.e., data from multiple sources or modalities) can lead to better performance compared to using a single data modality.
- During the rise of deep learning for visual modeling, action recognition has mainly relied on Convolutional Neural Networks (CNNs). However, the increasing popularity of Transformers in visual modeling is now causing a paradigm shift for action recognition.
- This survey focuses on Multimodal Human Action Recognition (MHAR) and the process of fusing features from individual data modalities, as well as the emerging techniques and design choices that have led to more efficient MHAR models.
Plain English Explanation
Human action recognition is the task of identifying and classifying the actions or behaviors of people in digital data, such as images or videos. This is an important problem in the field of computer vision with many practical applications, such as surveillance, human-computer interaction, and robotics.
Recent research has shown that using data from multiple sources or "modalities" (e.g., video, audio, sensor data) can lead to better performance in action recognition compared to using a single data modality. This is because each modality can provide complementary information that helps the computer system better understand the actions being performed.
In the past decade, as deep learning techniques like Convolutional Neural Networks (CNNs) have become more prominent in visual modeling, action recognition approaches have mainly relied on these CNN-based models. However, a new type of deep learning model called Transformers is now also being applied to action recognition, causing a shift in the way these problems are approached.
This survey paper focuses specifically on Multimodal Human Action Recognition (MHAR), which involves using data from multiple modalities to recognize human actions. The paper examines the techniques used to fusion the features extracted from the individual data modalities, as well as the latest architectural and design choices that have led to more efficient MHAR models.
Technical Explanation
The paper provides a comprehensive survey of the state-of-the-art in Multimodal Human Action Recognition (MHAR). It starts by highlighting the widespread applications of human action recognition in computer vision and the advantages of using multimodal data compared to single-modality approaches.
The survey then delves into the evolution of action recognition techniques, noting the predominance of Convolutional Neural Networks (CNNs) during the rise of deep learning for visual modeling. However, it also emphasizes the recent paradigm shift towards the use of Transformer models, which are now being applied to the action recognition task.
A key focus of the paper is the process of fusing the features extracted from individual data modalities, as this is a crucial aspect of successful MHAR systems. The authors analyze both classic and emerging feature fusion techniques, highlighting the design choices that have led to more efficient and effective MHAR models.
The survey also covers the popular trends in adapting CNN and Transformer architectural building blocks for action recognition, drawing insights from the latest research in this area. Datasets and their implications for MHAR are also discussed from a scale and evaluation perspective.
Critical Analysis
The survey provides a comprehensive and up-to-date overview of the Multimodal Human Action Recognition (MHAR) field, highlighting the recent shift towards Transformer-based models and the importance of effective feature fusion techniques. The authors have done a commendable job in synthesizing the key developments and insights from the latest research.
One potential limitation of the survey is that it does not delve deeply into the specific architectural innovations and fusion methods employed by the reviewed MHAR models. While the high-level trends and design choices are discussed, a more detailed technical analysis of the most promising approaches could have provided additional insights for researchers working in this area.
Additionally, the survey could have engaged in more critical evaluation of the current state of MHAR research, identifying potential biases or limitations in the available datasets, as well as areas where further advancements are needed to address real-world deployment challenges. Such analyses could have helped guide future research directions more effectively.
Nevertheless, the survey serves as a valuable resource for researchers and practitioners interested in understanding the latest developments and best practices in the rapidly evolving field of Multimodal Human Action Recognition.
Conclusion
This comprehensive survey paper provides a timely overview of the state-of-the-art in Multimodal Human Action Recognition (MHAR), highlighting the recent shift from Convolutional Neural Networks to Transformer-based models and the critical role of effective feature fusion techniques. By synthesizing the key insights and design choices from the latest MHAR research, the authors have laid the groundwork for further advancements in this important computer vision domain, which has numerous practical applications in areas such as surveillance, human-computer interaction, and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
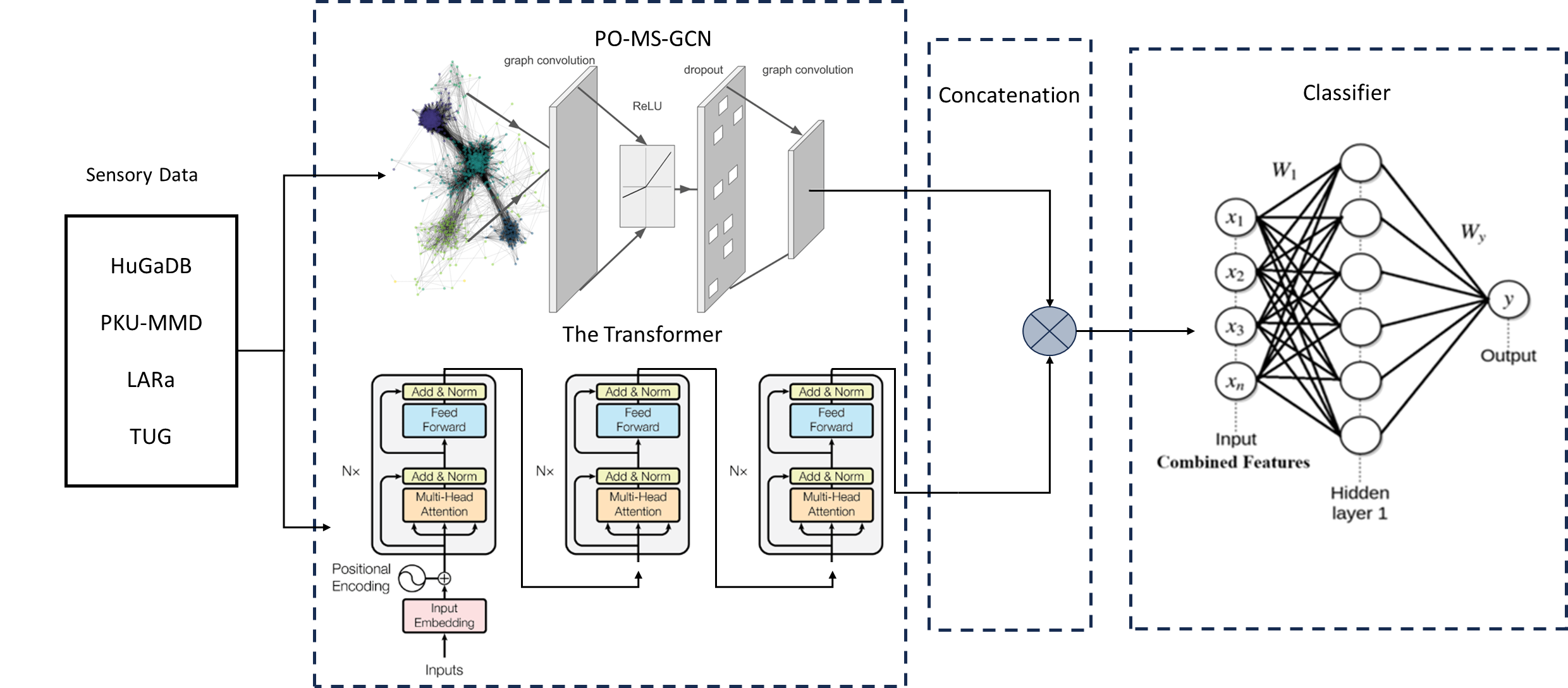
Feature Fusion for Human Activity Recognition using Parameter-Optimized Multi-Stage Graph Convolutional Network and Transformer Models
Mohammad Belal (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Taimur Hassan (Abu Dhabi University, Abu Dhabi, United Arab Emirates), Abdelfatah Ahmed (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Ahmad Aljarah (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Nael Alsheikh (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Irfan Hussain (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates)
0
0
Human activity recognition (HAR) is a crucial area of research that involves understanding human movements using computer and machine vision technology. Deep learning has emerged as a powerful tool for this task, with models such as Convolutional Neural Networks (CNNs) and Transformers being employed to capture various aspects of human motion. One of the key contributions of this work is the demonstration of the effectiveness of feature fusion in improving HAR accuracy by capturing spatial and temporal features, which has important implications for the development of more accurate and robust activity recognition systems. The study uses sensory data from HuGaDB, PKU-MMD, LARa, and TUG datasets. Two model, the PO-MS-GCN and a Transformer were trained and evaluated, with PO-MS-GCN outperforming state-of-the-art models. HuGaDB and TUG achieved high accuracies and f1-scores, while LARa and PKU-MMD had lower scores. Feature fusion improved results across datasets.
6/26/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024

ActNetFormer: Transformer-ResNet Hybrid Method for Semi-Supervised Action Recognition in Videos
Sharana Dharshikgan Suresh Dass, Hrishav Bakul Barua, Ganesh Krishnasamy, Raveendran Paramesran, Raphael C. -W. Phan
0
0
Human action or activity recognition in videos is a fundamental task in computer vision with applications in surveillance and monitoring, self-driving cars, sports analytics, human-robot interaction and many more. Traditional supervised methods require large annotated datasets for training, which are expensive and time-consuming to acquire. This work proposes a novel approach using Cross-Architecture Pseudo-Labeling with contrastive learning for semi-supervised action recognition. Our framework leverages both labeled and unlabelled data to robustly learn action representations in videos, combining pseudo-labeling with contrastive learning for effective learning from both types of samples. We introduce a novel cross-architecture approach where 3D Convolutional Neural Networks (3D CNNs) and video transformers (VIT) are utilised to capture different aspects of action representations; hence we call it ActNetFormer. The 3D CNNs excel at capturing spatial features and local dependencies in the temporal domain, while VIT excels at capturing long-range dependencies across frames. By integrating these complementary architectures within the ActNetFormer framework, our approach can effectively capture both local and global contextual information of an action. This comprehensive representation learning enables the model to achieve better performance in semi-supervised action recognition tasks by leveraging the strengths of each of these architectures. Experimental results on standard action recognition datasets demonstrate that our approach performs better than the existing methods, achieving state-of-the-art performance with only a fraction of labeled data. The official website of this work is available at: https://github.com/rana2149/ActNetFormer.
4/10/2024
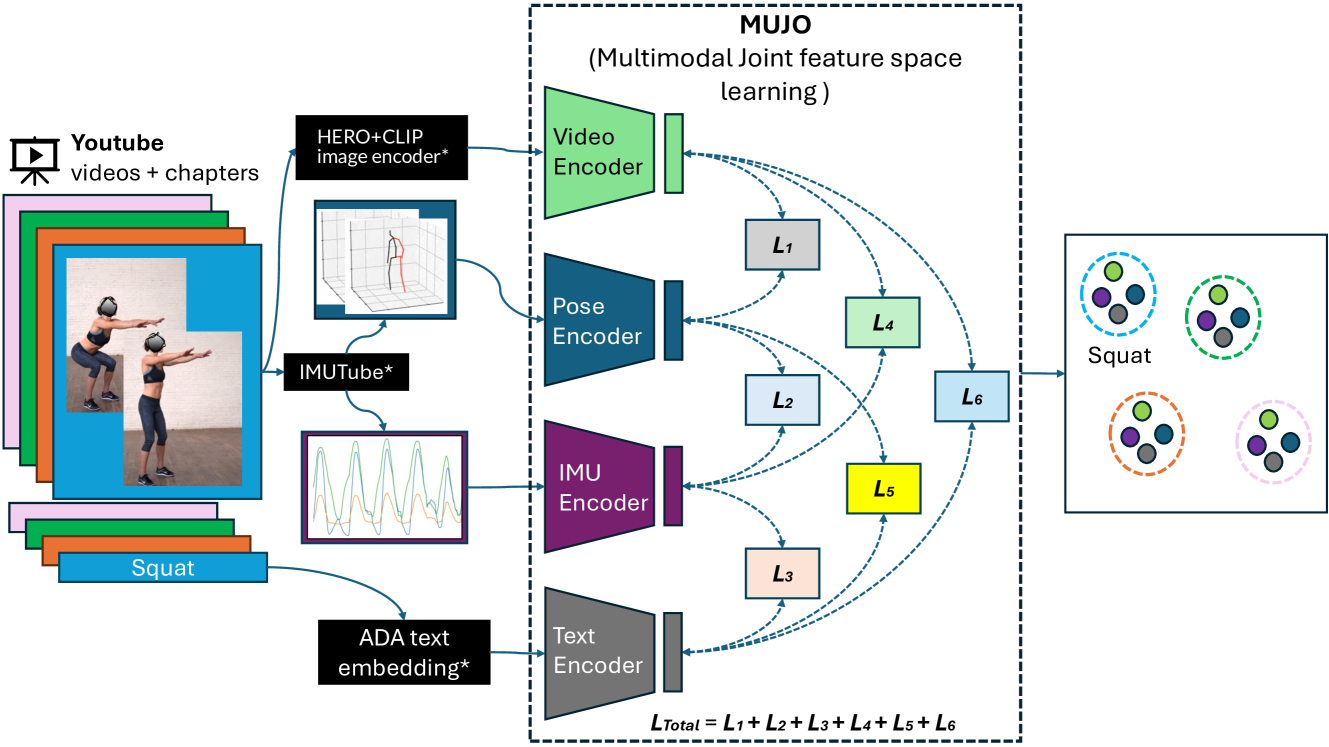
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Stefan Gerd Fritsch, Cennet Oguz, Vitor Fortes Rey, Lala Ray, Maximilian Kiefer-Emmanouilidis, Paul Lukowicz
0
0
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
6/7/2024