EWEK-QA: Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems
2406.10393
0
0

Abstract
The emerging citation-based QA systems are gaining more attention especially in generative AI search applications. The importance of extracted knowledge provided to these systems is vital from both accuracy (completeness of information) and efficiency (extracting the information in a timely manner). In this regard, citation-based QA systems are suffering from two shortcomings. First, they usually rely only on web as a source of extracted knowledge and adding other external knowledge sources can hamper the efficiency of the system. Second, web-retrieved contents are usually obtained by some simple heuristics such as fixed length or breakpoints which might lead to splitting information into pieces. To mitigate these issues, we propose our enhanced web and efficient knowledge graph (KG) retrieval solution (EWEK-QA) to enrich the content of the extracted knowledge fed to the system. This has been done through designing an adaptive web retriever and incorporating KGs triples in an efficient manner. We demonstrate the effectiveness of EWEK-QA over the open-source state-of-the-art (SoTA) web-based and KG baseline models using a comprehensive set of quantitative and human evaluation experiments. Our model is able to: first, improve the web-retriever baseline in terms of extracting more relevant passages (>20%), the coverage of answer span (>25%) and self containment (>35%); second, obtain and integrate KG triples into its pipeline very efficiently (by avoiding any LLM calls) to outperform the web-only and KG-only SoTA baselines significantly in 7 quantitative QA tasks and our human evaluation.
Create account to get full access
Overview
- Presents EWEK-QA, a citation-based question answering system that combines efficient web and knowledge graph retrieval
- Aims to improve the accuracy and efficiency of question answering by leveraging both web-based and knowledge graph-based information
- Introduces several key innovations, including a refined citation retrieval module and a novel knowledge graph reasoning component
Plain English Explanation
EWEK-QA is a new system designed to help answer questions more accurately and efficiently. It does this by combining two main sources of information: the wider web and specialized knowledge graphs.
The broader web can provide a wealth of relevant information, but it can be challenging to find the most relevant and reliable content. Knowledge graphs, on the other hand, contain highly structured data that can offer deep insights, but they may not cover every topic in depth.
EWEK-QA tries to get the best of both worlds. It has a refined module for quickly finding relevant citations from the web. It also has a novel component that can reason about the information in knowledge graphs to provide more complete answers. By using these two complementary sources of information, EWEK-QA aims to deliver more accurate and comprehensive answers to users' questions.
Technical Explanation
EWEK-QA builds on previous work in citation-based question answering and knowledge-enhanced question answering. It introduces several key innovations:
-
Refined Citation Retrieval Module: EWEK-QA's citation retrieval component is more efficient and accurate than previous approaches, allowing it to quickly find the most relevant web-based information to answer a given question.
-
Novel Knowledge Graph Reasoning: The system also includes a new module that can reason about the structured data in knowledge graphs, such as KET-QA, to provide more complete and informative answers.
-
Hybrid Approach: By combining the strengths of web-based and knowledge graph-based retrieval, EWEK-QA aims to deliver better overall performance compared to systems that rely on a single source of information, like Improving Health Question Answering with Reliable Time-Aware Knowledge.
The researchers evaluate EWEK-QA on several benchmark datasets and demonstrate significant improvements in both answer accuracy and retrieval efficiency compared to state-of-the-art baselines, including ChatKBQA.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated system that makes meaningful advances in the field of citation-based question answering. However, the authors acknowledge several limitations and areas for future work:
- The current knowledge graph reasoning component is relatively simple and could be expanded to handle more complex queries and reasoning tasks.
- The system's performance may be sensitive to the coverage and quality of the underlying knowledge graphs, which could limit its applicability in certain domains.
- The authors suggest exploring more sophisticated techniques for combining web-based and knowledge graph-based signals to further improve answer quality and efficiency.
Additionally, while the paper provides a comprehensive technical evaluation, it would be helpful to see more user-centric assessments, such as studies on the system's usability and user satisfaction, to better understand its real-world impact.
Conclusion
EWEK-QA represents a significant step forward in the development of citation-based question answering systems. By seamlessly integrating web-based and knowledge graph-based retrieval, the system can provide more accurate and informative answers to users' questions. The innovations introduced in this work, such as the refined citation retrieval module and the novel knowledge graph reasoning component, have the potential to inspire further advancements in this important research area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

EffiQA: Efficient Question-Answering with Strategic Multi-Model Collaboration on Knowledge Graphs
Zixuan Dong, Baoyun Peng, Yufei Wang, Jia Fu, Xiaodong Wang, Yongxue Shan, Xin Zhou
0
0
While large language models (LLMs) have shown remarkable capabilities in natural language processing, they struggle with complex, multi-step reasoning tasks involving knowledge graphs (KGs). Existing approaches that integrate LLMs and KGs either underutilize the reasoning abilities of LLMs or suffer from prohibitive computational costs due to tight coupling. To address these limitations, we propose a novel collaborative framework named EffiQA that can strike a balance between performance and efficiency via an iterative paradigm. EffiQA consists of three stages: global planning, efficient KG exploration, and self-reflection. Specifically, EffiQA leverages the commonsense capability of LLMs to explore potential reasoning pathways through global planning. Then, it offloads semantic pruning to a small plug-in model for efficient KG exploration. Finally, the exploration results are fed to LLMs for self-reflection to further improve the global planning and efficient KG exploration. Empirical evidence on multiple KBQA benchmarks shows EffiQA's effectiveness, achieving an optimal balance between reasoning accuracy and computational costs. We hope the proposed new framework will pave the way for efficient, knowledge-intensive querying by redefining the integration of LLMs and KGs, fostering future research on knowledge-based question answering.
6/4/2024
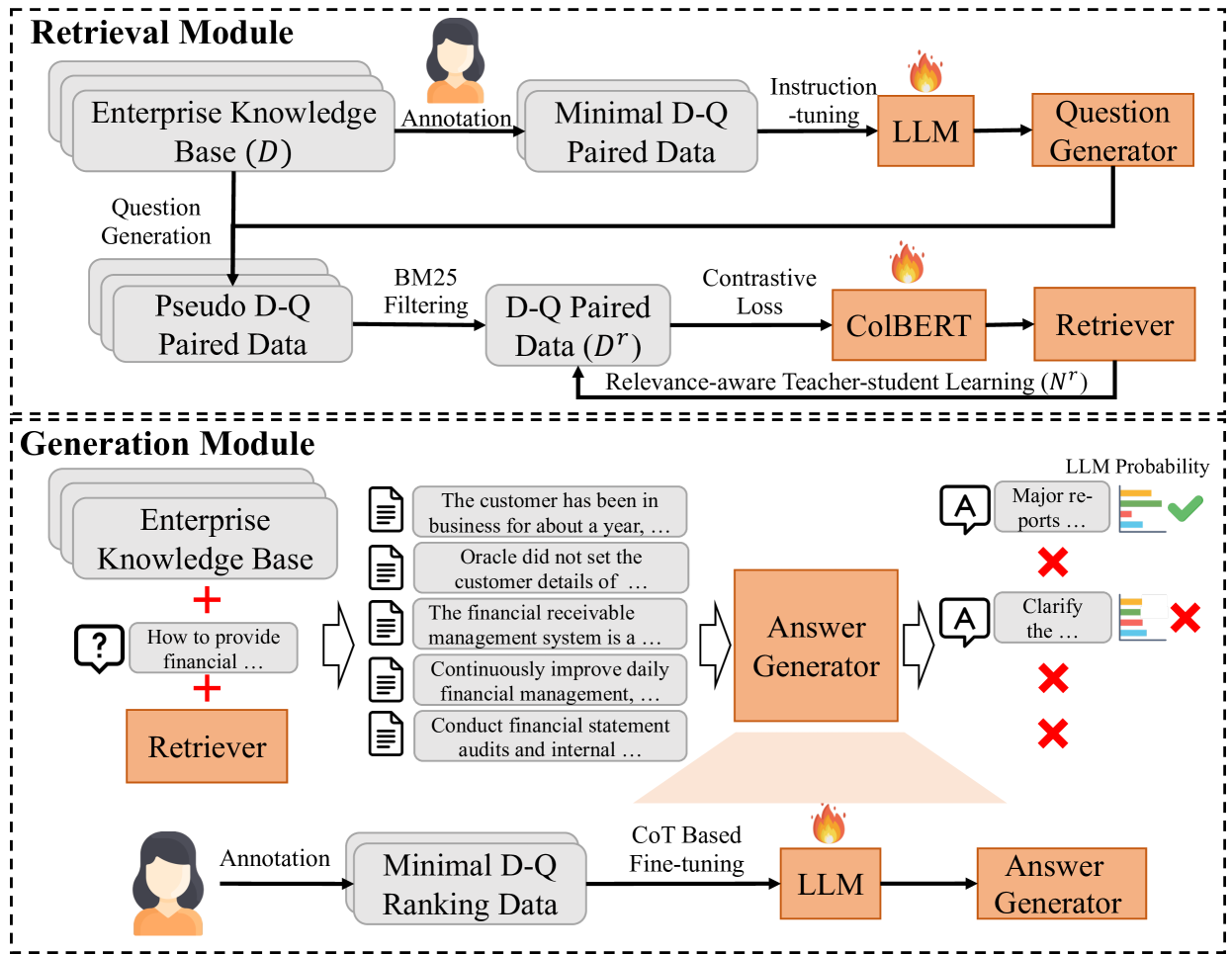
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024

Improving Health Question Answering with Reliable and Time-Aware Evidence Retrieval
Juraj Vladika, Florian Matthes
0
0
In today's digital world, seeking answers to health questions on the Internet is a common practice. However, existing question answering (QA) systems often rely on using pre-selected and annotated evidence documents, thus making them inadequate for addressing novel questions. Our study focuses on the open-domain QA setting, where the key challenge is to first uncover relevant evidence in large knowledge bases. By utilizing the common retrieve-then-read QA pipeline and PubMed as a trustworthy collection of medical research documents, we answer health questions from three diverse datasets. We modify different retrieval settings to observe their influence on the QA pipeline's performance, including the number of retrieved documents, sentence selection process, the publication year of articles, and their number of citations. Our results reveal that cutting down on the amount of retrieved documents and favoring more recent and highly cited documents can improve the final macro F1 score up to 10%. We discuss the results, highlight interesting examples, and outline challenges for future research, like managing evidence disagreement and crafting user-friendly explanations.
4/15/2024

KET-QA: A Dataset for Knowledge Enhanced Table Question Answering
Mengkang Hu, Haoyu Dong, Ping Luo, Shi Han, Dongmei Zhang
0
0
Due to the concise and structured nature of tables, the knowledge contained therein may be incomplete or missing, posing a significant challenge for table question answering (TableQA) and data analysis systems. Most existing datasets either fail to address the issue of external knowledge in TableQA or only utilize unstructured text as supplementary information for tables. In this paper, we propose to use a knowledge base (KB) as the external knowledge source for TableQA and construct a dataset KET-QA with fine-grained gold evidence annotation. Each table in the dataset corresponds to a sub-graph of the entire KB, and every question requires the integration of information from both the table and the sub-graph to be answered. To extract pertinent information from the vast knowledge sub-graph and apply it to TableQA, we design a retriever-reasoner structured pipeline model. Experimental results demonstrate that our model consistently achieves remarkable relative performance improvements ranging from 1.9 to 6.5 times and absolute improvements of 11.66% to 44.64% on EM scores across three distinct settings (fine-tuning, zero-shot, and few-shot), in comparison with solely relying on table information in the traditional TableQA manner. However, even the best model achieves a 60.23% EM score, which still lags behind the human-level performance, highlighting the challenging nature of KET-QA for the question-answering community. We also provide a human evaluation of error cases to analyze further the aspects in which the model can be improved. Project page: https://ketqa.github.io/.
5/15/2024