An Expectation-Maximization Algorithm for Training Clean Diffusion Models from Corrupted Observations

0

Sign in to get full access
Overview
- This paper presents a novel Expectation-Maximization (EM) algorithm for training clean diffusion models from corrupted observations.
- Diffusion models are a powerful class of generative models that can produce high-quality samples, but they require large amounts of clean training data, which can be difficult to obtain.
- The proposed EM algorithm allows diffusion models to be trained on corrupted data, effectively "learning from mistakes" to produce high-quality samples.
Plain English Explanation
Diffusion models are a type of machine learning model that can generate realistic images, text, and other data. However, they typically require a large amount of "clean" training data - data that is high-quality and free of errors or corruptions. Obtaining this clean data can be challenging, especially for certain applications.
The researchers in this paper developed a new algorithm called Expectation-Maximization (EM) that allows diffusion models to be trained on "corrupted" data - data that has been intentionally degraded or distorted in some way. The EM algorithm works by repeatedly guessing what the original, clean data might have looked like, and then adjusting the diffusion model to better match those guesses.
This is a clever approach, as it allows the diffusion model to learn from its mistakes and produce high-quality samples, even when the training data is not perfect. By learning diffusion priors from the corrupted observations, the model can effectively "fill in the gaps" and generate realistic outputs.
The researchers demonstrate the effectiveness of their approach on several benchmarks, showing that the EM-trained diffusion models can outperform models trained on clean data in some cases. This could be particularly useful for applications where clean data is scarce or expensive to obtain, such as medical imaging or scientific simulations.
Technical Explanation
The core idea of the paper is to use an Expectation-Maximization (EM) algorithm to train diffusion models on corrupted data. Diffusion models are a type of generative model that work by gradually adding noise to an input and then learning to reverse this process to generate new samples.
Typically, diffusion models require large amounts of clean training data to learn this noise-removal process effectively. However, the EM algorithm proposed in this paper allows the model to learn from corrupted observations instead. The algorithm works by alternating between two steps:
- Expectation step: Estimate the clean, original data that might have produced the observed corrupted samples.
- Maximization step: Update the diffusion model parameters to better fit the estimated clean data.
By iterating between these two steps, the model gradually learns to generate consistent diffusion samples that match the underlying clean data, even though it only observes the corrupted version during training.
The researchers demonstrate the effectiveness of their approach on several benchmark datasets, including image denoising and text denoising tasks. They show that the EM-trained diffusion models can outperform models trained on clean data, particularly when the corruption process is well-understood.
Critical Analysis
The proposed EM algorithm for training diffusion models from corrupted data is a clever and potentially impactful contribution to the field. By allowing diffusion models to learn from imperfect data, the researchers have expanded the practical applications of these powerful generative models.
However, the paper does acknowledge some limitations of the approach. The performance of the EM-trained models is still dependent on the underlying noise or corruption process being well-characterized. If the corruption mechanism is not well-understood, the algorithm may struggle to accurately estimate the original clean data.
Additionally, the EM algorithm can be computationally intensive, as it requires repeatedly updating the diffusion model and estimating the clean data. This may limit the scalability of the approach, especially for very large or complex datasets.
Further research could explore ways to make the EM algorithm more efficient, or to extend the approach to other types of generative models beyond just diffusion. Investigating the theoretical properties of the EM-trained diffusion models, such as their sample quality or mode coverage, could also provide valuable insights.
Overall, this paper represents an important step forward in enabling high-quality generative modeling from imperfect data, which could have significant implications for a wide range of real-world applications.
Conclusion
This paper presents a novel Expectation-Maximization (EM) algorithm for training clean diffusion models from corrupted observations. By alternating between estimating the original clean data and updating the diffusion model parameters, the EM algorithm allows these powerful generative models to learn from imperfect training data.
The researchers demonstrate the effectiveness of their approach on several benchmark tasks, showing that the EM-trained diffusion models can outperform models trained on clean data in some cases. This could be particularly useful for applications where obtaining large amounts of clean training data is challenging, such as medical imaging or scientific simulations.
While the EM algorithm does have some limitations, such as its computational intensity and reliance on well-characterized corruption processes, this work represents an important step forward in expanding the practical applications of diffusion models. Further research in this area could lead to even more robust and versatile generative modeling techniques that can learn from the noisy and incomplete data commonly encountered in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Expectation-Maximization Algorithm for Training Clean Diffusion Models from Corrupted Observations
Weimin Bai, Yifei Wang, Wenzheng Chen, He Sun
Diffusion models excel in solving imaging inverse problems due to their ability to model complex image priors. However, their reliance on large, clean datasets for training limits their practical use where clean data is scarce. In this paper, we propose EMDiffusion, an expectation-maximization (EM) approach to train diffusion models from corrupted observations. Our method alternates between reconstructing clean images from corrupted data using a known diffusion model (E-step) and refining diffusion model weights based on these reconstructions (M-step). This iterative process leads the learned diffusion model to gradually converge to the true clean data distribution. We validate our method through extensive experiments on diverse computational imaging tasks, including random inpainting, denoising, and deblurring, achieving new state-of-the-art performance.
Read more7/2/2024
📈
0
Learning Diffusion Priors from Observations by Expectation Maximization
Franc{c}ois Rozet, G'er^ome Andry, Franc{c}ois Lanusse, Gilles Louppe
Diffusion models recently proved to be remarkable priors for Bayesian inverse problems. However, training these models typically requires access to large amounts of clean data, which could prove difficult in some settings. In this work, we present a novel method based on the expectation-maximization algorithm for training diffusion models from incomplete and noisy observations only. Unlike previous works, our method leads to proper diffusion models, which is crucial for downstream tasks. As part of our method, we propose and motivate an improved posterior sampling scheme for unconditional diffusion models. We present empirical evidence supporting the effectiveness of our method.
Read more8/19/2024

0
Integrating Amortized Inference with Diffusion Models for Learning Clean Distribution from Corrupted Images
Yifei Wang, Weimin Bai, Weijian Luo, Wenzheng Chen, He Sun
Diffusion models (DMs) have emerged as powerful generative models for solving inverse problems, offering a good approximation of prior distributions of real-world image data. Typically, diffusion models rely on large-scale clean signals to accurately learn the score functions of ground truth clean image distributions. However, such a requirement for large amounts of clean data is often impractical in real-world applications, especially in fields where data samples are expensive to obtain. To address this limitation, in this work, we introduce emph{FlowDiff}, a novel joint training paradigm that leverages a conditional normalizing flow model to facilitate the training of diffusion models on corrupted data sources. The conditional normalizing flow try to learn to recover clean images through a novel amortized inference mechanism, and can thus effectively facilitate the diffusion model's training with corrupted data. On the other side, diffusion models provide strong priors which in turn improve the quality of image recovery. The flow model and the diffusion model can therefore promote each other and demonstrate strong empirical performances. Our elaborate experiment shows that FlowDiff can effectively learn clean distributions across a wide range of corrupted data sources, such as noisy and blurry images. It consistently outperforms existing baselines with significant margins under identical conditions. Additionally, we also study the learned diffusion prior, observing its superior performance in downstream computational imaging tasks, including inpainting, denoising, and deblurring.
Read more7/17/2024
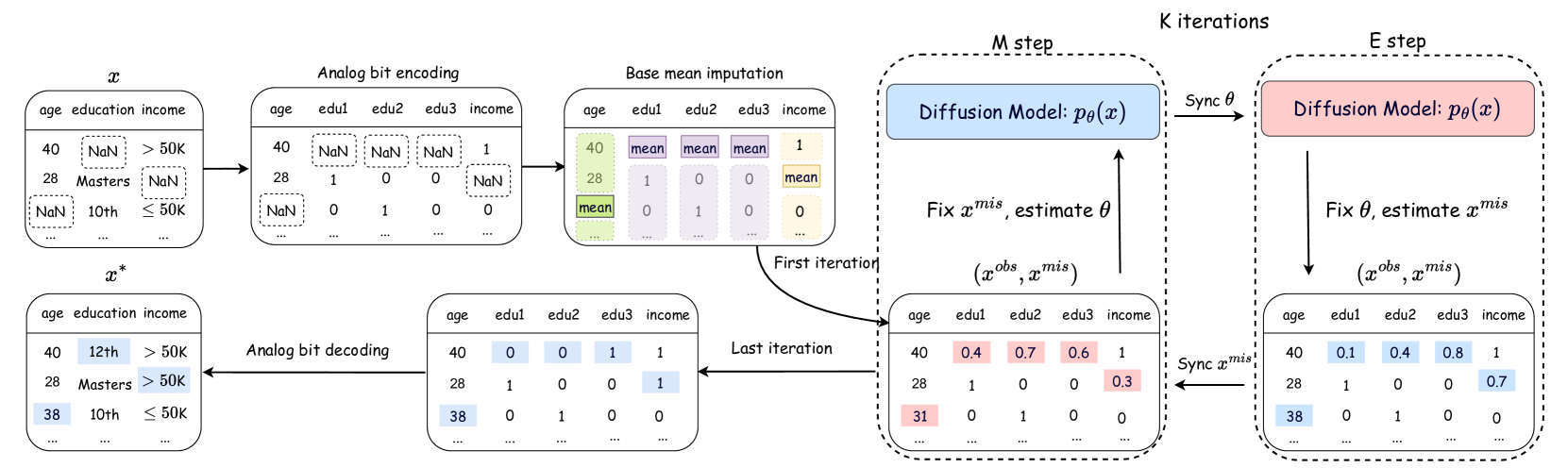
0
Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
Hengrui Zhang, Liancheng Fang, Philip S. Yu
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
Read more6/3/2024