Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
2405.20690
0
0
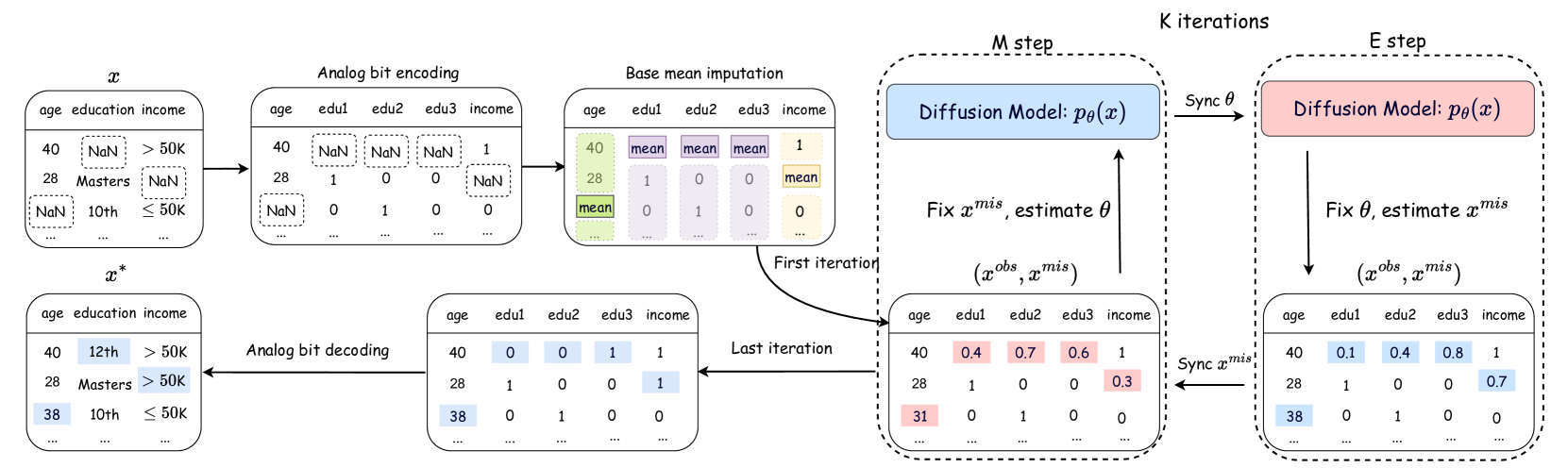
Abstract
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Learning Diffusion Priors from Observations by Expectation Maximization
Franc{c}ois Rozet, G'er^ome Andry, Franc{c}ois Lanusse, Gilles Louppe
0
0
Diffusion models recently proved to be remarkable priors for Bayesian inverse problems. However, training these models typically requires access to large amounts of clean data, which could prove difficult in some settings. In this work, we present a novel method based on the expectation-maximization algorithm for training diffusion models from incomplete and noisy observations only. Unlike previous works, our method leads to proper diffusion models, which is crucial for downstream tasks. As part of our method, we propose and motivate a new posterior sampling scheme for unconditional diffusion models. We present empirical evidence supporting the effectiveness of our method.
5/24/2024

EM Distillation for One-step Diffusion Models
Sirui Xie, Zhisheng Xiao, Diederik P Kingma, Tingbo Hou, Ying Nian Wu, Kevin Patrick Murphy, Tim Salimans, Ben Poole, Ruiqi Gao
0
0
While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.
5/28/2024
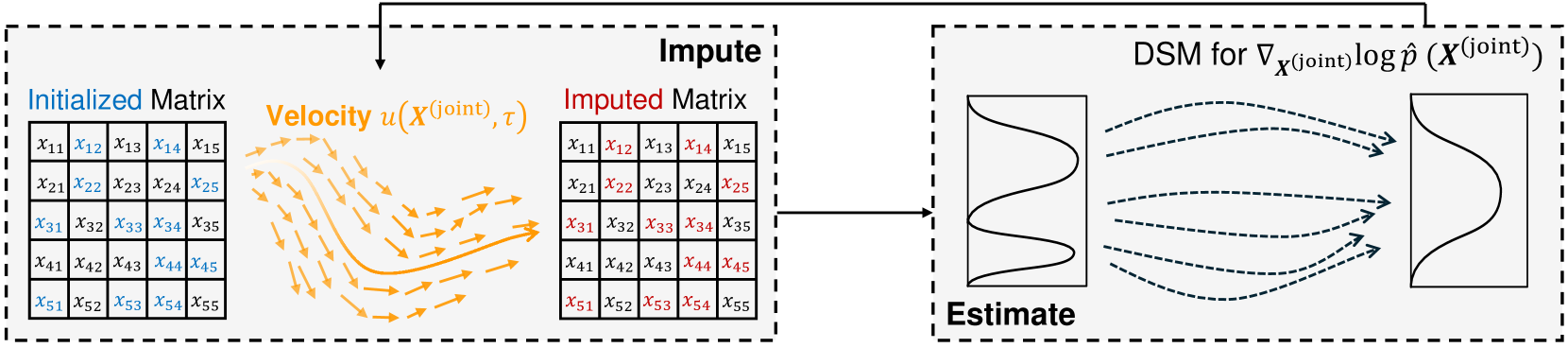
Rethinking the Diffusion Models for Numerical Tabular Data Imputation from the Perspective of Wasserstein Gradient Flow
Zhichao Chen, Haoxuan Li, Fangyikang Wang, Odin Zhang, Hu Xu, Xiaoyu Jiang, Zhihuan Song, Eric H. Wang
0
0
Diffusion models (DMs) have gained attention in Missing Data Imputation (MDI), but there remain two long-neglected issues to be addressed: (1). Inaccurate Imputation, which arises from inherently sample-diversification-pursuing generative process of DMs. (2). Difficult Training, which stems from intricate design required for the mask matrix in model training stage. To address these concerns within the realm of numerical tabular datasets, we introduce a novel principled approach termed Kernelized Negative Entropy-regularized Wasserstein gradient flow Imputation (KnewImp). Specifically, based on Wasserstein gradient flow (WGF) framework, we first prove that issue (1) stems from the cost functionals implicitly maximized in DM-based MDI are equivalent to the MDI's objective plus diversification-promoting non-negative terms. Based on this, we then design a novel cost functional with diversification-discouraging negative entropy and derive our KnewImp approach within WGF framework and reproducing kernel Hilbert space. After that, we prove that the imputation procedure of KnewImp can be derived from another cost functional related to the joint distribution, eliminating the need for the mask matrix and hence naturally addressing issue (2). Extensive experiments demonstrate that our proposed KnewImp approach significantly outperforms existing state-of-the-art methods.
6/26/2024
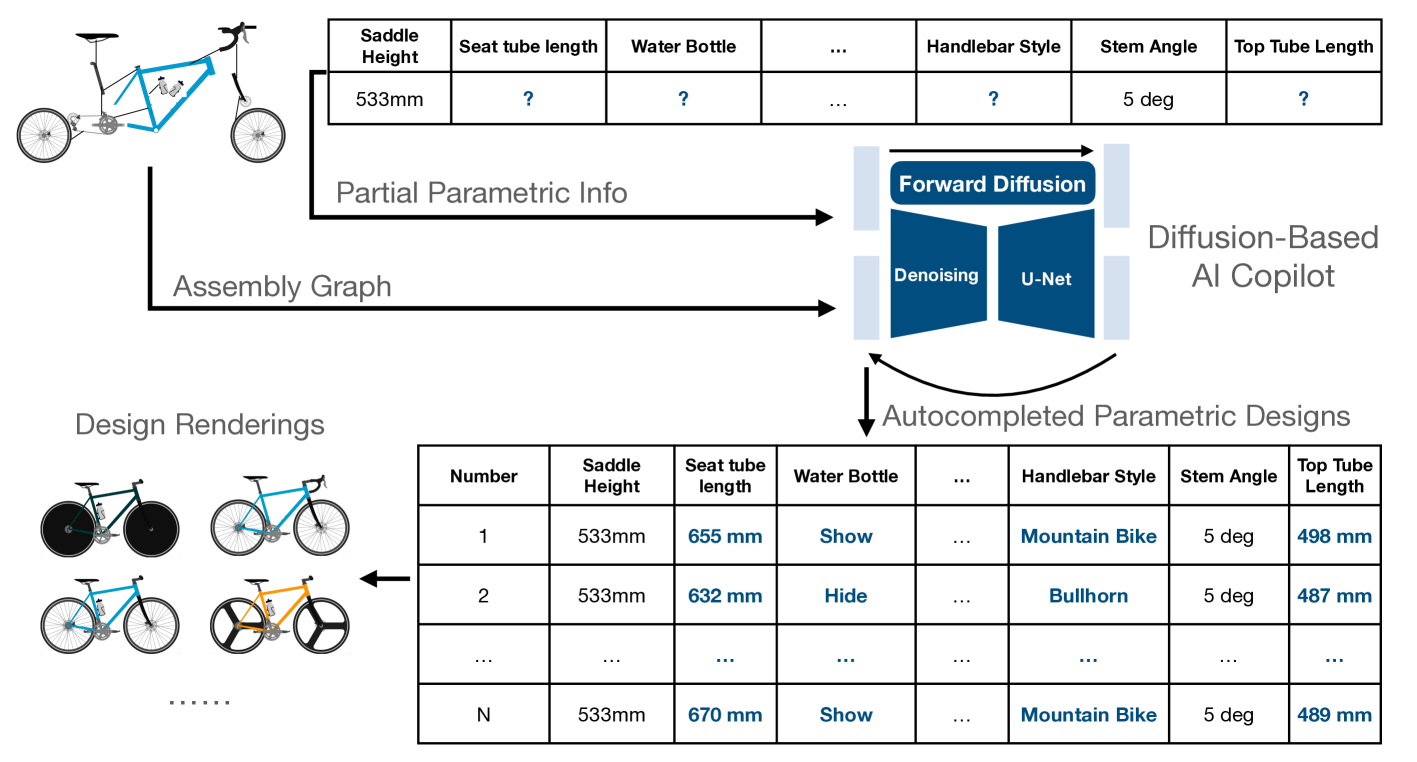
Bridging Design Gaps: A Parametric Data Completion Approach With Graph Guided Diffusion Models
Rui Zhou, Chenyang Yuan, Frank Permenter, Yanxia Zhang, Nikos Arechiga, Matt Klenk, Faez Ahmed
0
0
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
6/19/2024