Expediting Building Footprint Extraction from High-resolution Remote Sensing Images via progressive lenient supervision
2307.12220
0
0
⛏️
Abstract
The efficacy of building footprint segmentation from remotely sensed images has been hindered by model transfer effectiveness. Many existing building segmentation methods were developed upon the encoder-decoder architecture of U-Net, in which the encoder is finetuned from the newly developed backbone networks that are pre-trained on ImageNet. However, the heavy computational burden of the existing decoder designs hampers the successful transfer of these modern encoder networks to remote sensing tasks. Even the widely-adopted deep supervision strategy fails to mitigate these challenges due to its invalid loss in hybrid regions where foreground and background pixels are intermixed. In this paper, we conduct a comprehensive evaluation of existing decoder network designs for building footprint segmentation and propose an efficient framework denoted as BFSeg to enhance learning efficiency and effectiveness. Specifically, a densely-connected coarse-to-fine feature fusion decoder network that facilitates easy and fast feature fusion across scales is proposed. Moreover, considering the invalidity of hybrid regions in the down-sampled ground truth during the deep supervision process, we present a lenient deep supervision and distillation strategy that enables the network to learn proper knowledge from deep supervision. Building upon these advancements, we have developed a new family of building segmentation networks, which consistently surpass prior works with outstanding performance and efficiency across a wide range of newly developed encoder networks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Building footprint segmentation from remote sensing images has been hindered by the inability to effectively transfer models to new tasks.
- Many existing building segmentation methods use the U-Net encoder-decoder architecture, but the heavy computational burden of the decoders limits the successful transfer of modern encoder networks.
- Even the popular deep supervision strategy fails to address the challenges due to issues with "hybrid regions" where foreground and background pixels are mixed.
- This paper comprehensively evaluates existing decoder designs and proposes an efficient framework called BFSeg to improve learning efficiency and effectiveness.
Plain English Explanation
Building footprint segmentation is the process of identifying the outlines of buildings in aerial or satellite images. This is an important task for applications like urban planning and disaster response. However, the existing methods for doing this have struggled to work well when applied to new datasets or scenarios.
Many of the leading building segmentation techniques use a popular neural network architecture called U-Net. U-Net has an encoder part that extracts visual features, and a decoder part that assembles those features back into a segmented image. The problem is that the decoders in these U-Net models are computationally intensive, which makes it hard to effectively transfer the powerful encoder networks that have been trained on large datasets like ImageNet.
Another issue is with "deep supervision" - a technique where the network is trained to produce good segmentations at multiple scales. This helps the network learn better, but it becomes problematic in areas of the image where building and non-building pixels are mixed together ("hybrid regions"). The deep supervision process doesn't work well in these cases.
To address these challenges, the researchers in this paper propose a new framework called BFSeg. BFSeg uses a more efficient decoder design that makes it easier to transfer high-performing encoder networks. It also has a "lenient" deep supervision process that can handle the hybrid regions better. By incorporating these advances, the BFSeg models are able to outperform previous building segmentation approaches in both accuracy and efficiency.
Technical Explanation
The researchers first conduct a comprehensive evaluation of existing decoder network designs for the task of building footprint segmentation from remote sensing imagery. They find that the heavy computational burden of these decoders hampers the successful transfer of modern encoder networks that have been pre-trained on large datasets like ImageNet.
To address this, the researchers propose an efficient framework called BFSeg. At the core of BFSeg is a densely-connected, coarse-to-fine feature fusion decoder network. This design facilitates easy and fast feature fusion across different scales, enabling more effective transfer of powerful encoder networks.
Additionally, the researchers observe that the commonly used deep supervision strategy fails to work well in "hybrid regions" of the image, where foreground building pixels and background non-building pixels are intermixed. To handle this issue, BFSeg employs a "lenient" deep supervision and distillation approach that allows the network to learn proper knowledge even in these challenging hybrid areas.
By combining the efficient decoder design and the lenient deep supervision, the BFSeg framework is able to consistently outperform prior work on building footprint segmentation tasks across a wide range of encoder network backbones, including recent high-performing models like SegForestNet, MarsSeg, and Building-Road Collaborative Extraction.
Critical Analysis
The paper provides a thoughtful analysis of the limitations of existing building segmentation methods and proposes a novel framework to address them. The researchers' observations about the challenges posed by the computational complexity of decoder networks and the issues with deep supervision in hybrid regions are well-founded and important considerations for the field.
However, the paper does not delve into potential drawbacks or limitations of the BFSeg approach itself. For example, it would be useful to understand how BFSeg's performance and efficiency compare to other recent lightweight or mobile-optimized segmentation architectures, such as those based on MobileNet or other efficient network designs.
Additionally, the researchers could have provided more details on the specific performance tradeoffs between their lenient deep supervision strategy and other potential solutions to the hybrid region problem. Further exploration of these areas could strengthen the critical analysis and help readers form a more well-rounded understanding of the BFSeg framework.
Conclusion
This paper presents an efficient building footprint segmentation framework called BFSeg that addresses key limitations of existing methods. By employing a densely-connected, coarse-to-fine decoder design and a lenient deep supervision strategy, BFSeg is able to effectively transfer powerful encoder networks and handle the challenges of hybrid regions, leading to strong performance and efficiency gains over prior work.
These advancements in building segmentation have important implications for a variety of real-world applications, from urban planning and disaster response to map-making and infrastructure monitoring. As remote sensing technology continues to advance, techniques like BFSeg will play a crucial role in unlocking the full potential of these datasets for impactful societal applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Terrain-Informed Self-Supervised Learning: Enhancing Building Footprint Extraction from LiDAR Data with Limited Annotations
Anuja Vats, David Volgyes, Martijn Vermeer, Marius Pedersen, Kiran Raja, Daniele S. M. Fantin, Jacob Alexander Hay
0
0
Estimating building footprint maps from geospatial data is of paramount importance in urban planning, development, disaster management, and various other applications. Deep learning methodologies have gained prominence in building segmentation maps, offering the promise of precise footprint extraction without extensive post-processing. However, these methods face challenges in generalization and label efficiency, particularly in remote sensing, where obtaining accurate labels can be both expensive and time-consuming. To address these challenges, we propose terrain-aware self-supervised learning, tailored to remote sensing, using digital elevation models from LiDAR data. We propose to learn a model to differentiate between bare Earth and superimposed structures enabling the network to implicitly learn domain-relevant features without the need for extensive pixel-level annotations. We test the effectiveness of our approach by evaluating building segmentation performance on test datasets with varying label fractions. Remarkably, with only 1% of the labels (equivalent to 25 labeled examples), our method improves over ImageNet pre-training, showing the advantage of leveraging unlabeled data for feature extraction in the domain of remote sensing. The performance improvement is more pronounced in few-shot scenarios and gradually closes the gap with ImageNet pre-training as the label fraction increases. We test on a dataset characterized by substantial distribution shifts and labeling errors to demonstrate the generalizability of our approach. When compared to other baselines, including ImageNet pretraining and more complex architectures, our approach consistently performs better, demonstrating the efficiency and effectiveness of self-supervised terrain-aware feature learning.
4/19/2024
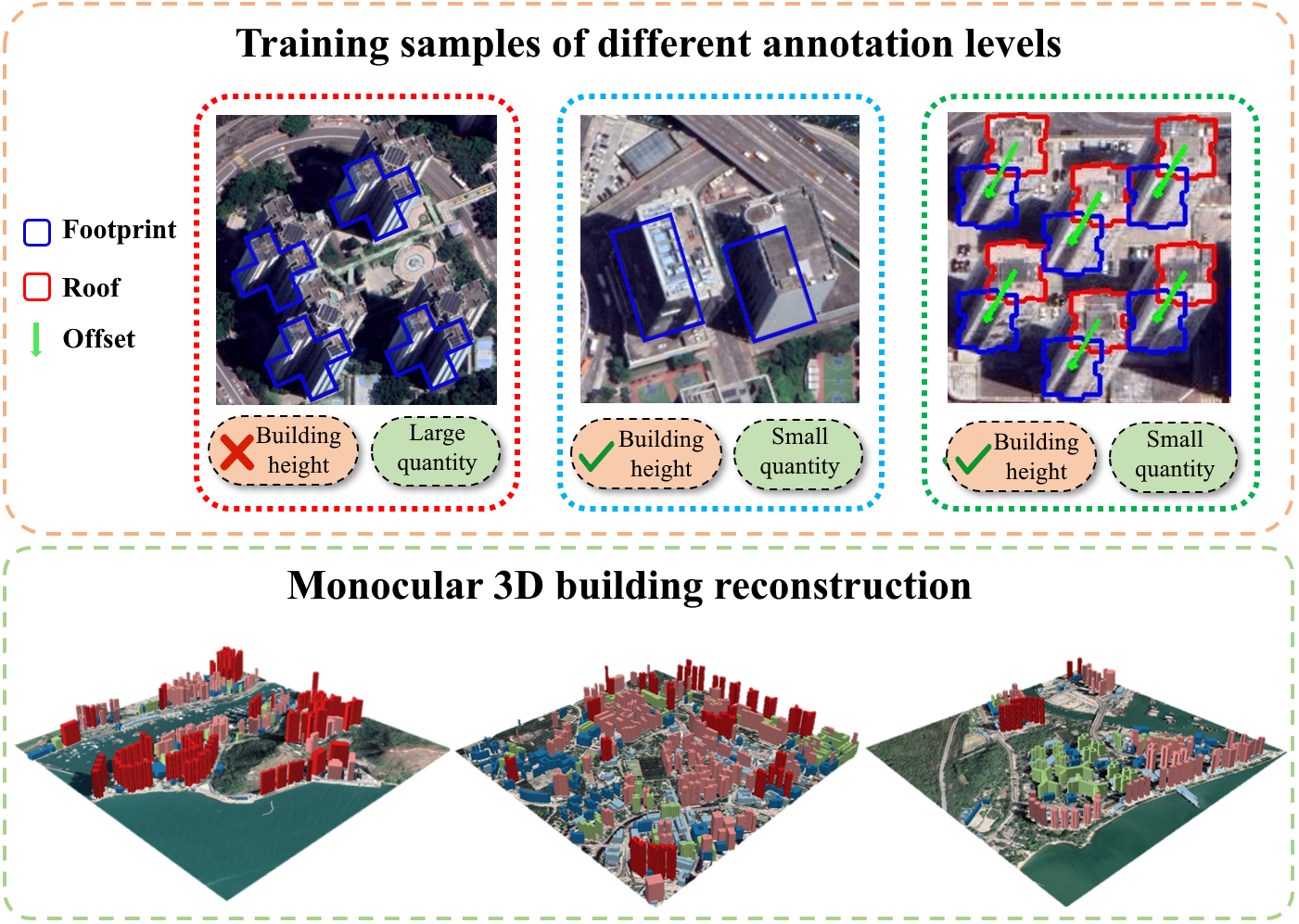
3D Building Reconstruction from Monocular Remote Sensing Images with Multi-level Supervisions
Weijia Li, Haote Yang, Zhenghao Hu, Juepeng Zheng, Gui-Song Xia, Conghui He
0
0
3D building reconstruction from monocular remote sensing images is an important and challenging research problem that has received increasing attention in recent years, owing to its low cost of data acquisition and availability for large-scale applications. However, existing methods rely on expensive 3D-annotated samples for fully-supervised training, restricting their application to large-scale cross-city scenarios. In this work, we propose MLS-BRN, a multi-level supervised building reconstruction network that can flexibly utilize training samples with different annotation levels to achieve better reconstruction results in an end-to-end manner. To alleviate the demand on full 3D supervision, we design two new modules, Pseudo Building Bbox Calculator and Roof-Offset guided Footprint Extractor, as well as new tasks and training strategies for different types of samples. Experimental results on several public and new datasets demonstrate that our proposed MLS-BRN achieves competitive performance using much fewer 3D-annotated samples, and significantly improves the footprint extraction and 3D reconstruction performance compared with current state-of-the-art. The code and datasets of this work will be released at https://github.com/opendatalab/MLS-BRN.git.
4/9/2024
Automated National Urban Map Extraction
Hasan Nasrallah, Abed Ellatif Samhat, Cristiano Nattero, Ali J. Ghandour
0
0
Developing countries usually lack the proper governance means to generate and regularly update a national rooftop map. Using traditional photogrammetry and surveying methods to produce a building map at the federal level is costly and time consuming. Using earth observation and deep learning methods, we can bridge this gap and propose an automated pipeline to fetch such national urban maps. This paper aims to exploit the power of fully convolutional neural networks for multi-class buildings' instance segmentation to leverage high object-wise accuracy results. Buildings' instance segmentation from sub-meter high-resolution satellite images can be achieved with relatively high pixel-wise metric scores. We detail all engineering steps to replicate this work and ensure highly accurate results in dense and slum areas witnessed in regions that lack proper urban planning in the Global South. We applied a case study of the proposed pipeline to Lebanon and successfully produced the first comprehensive national building footprint map with approximately 1 Million units with an 84% accuracy. The proposed architecture relies on advanced augmentation techniques to overcome dataset scarcity, which is often the case in developing countries.
5/6/2024
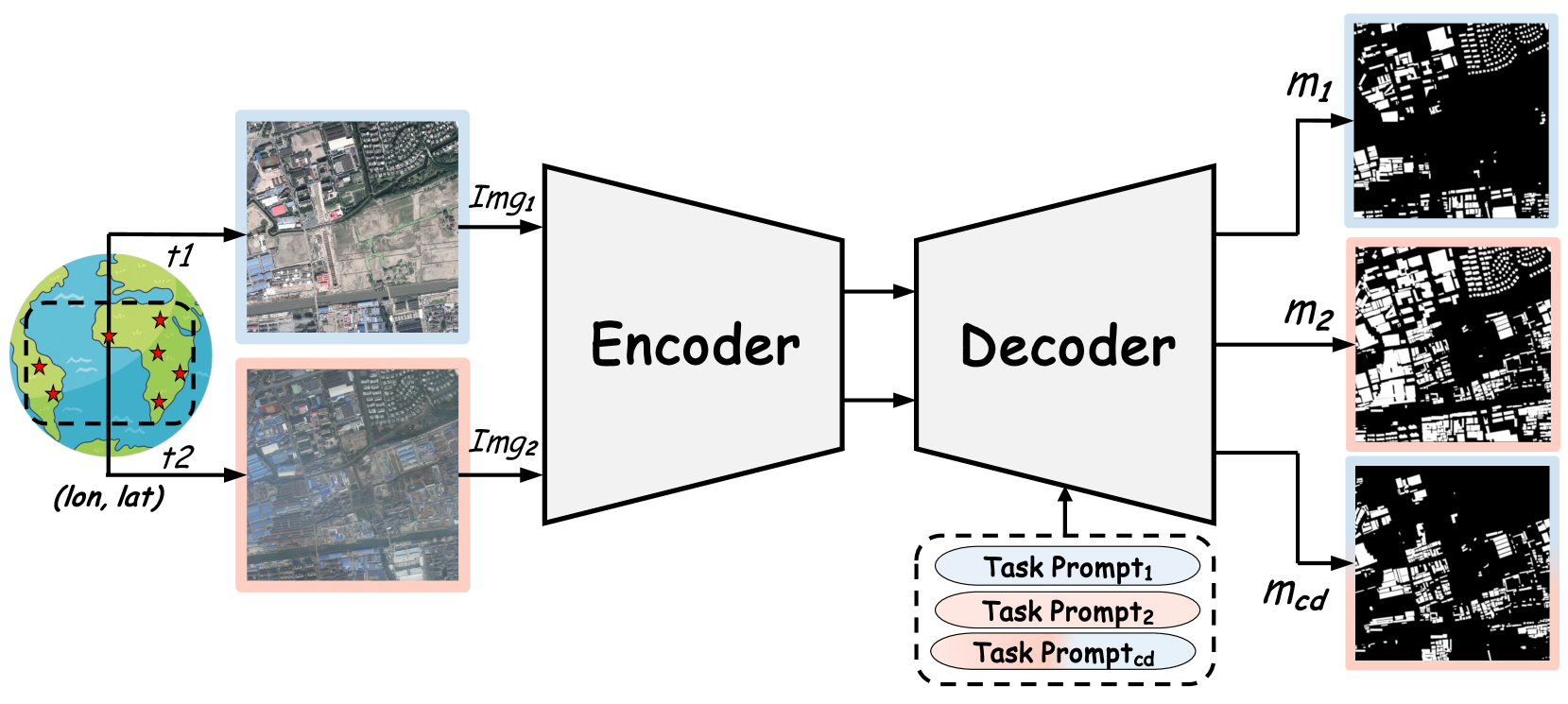
RSBuilding: Towards General Remote Sensing Image Building Extraction and Change Detection with Foundation Model
Mingze Wang, Lili Su, Cilin Yan, Sheng Xu, Pengcheng Yuan, Xiaolong Jiang, Baochang Zhang
0
0
The intelligent interpretation of buildings plays a significant role in urban planning and management, macroeconomic analysis, population dynamics, etc. Remote sensing image building interpretation primarily encompasses building extraction and change detection. However, current methodologies often treat these two tasks as separate entities, thereby failing to leverage shared knowledge. Moreover, the complexity and diversity of remote sensing image scenes pose additional challenges, as most algorithms are designed to model individual small datasets, thus lacking cross-scene generalization. In this paper, we propose a comprehensive remote sensing image building understanding model, termed RSBuilding, developed from the perspective of the foundation model. RSBuilding is designed to enhance cross-scene generalization and task universality. Specifically, we extract image features based on the prior knowledge of the foundation model and devise a multi-level feature sampler to augment scale information. To unify task representation and integrate image spatiotemporal clues, we introduce a cross-attention decoder with task prompts. Addressing the current shortage of datasets that incorporate annotations for both tasks, we have developed a federated training strategy to facilitate smooth model convergence even when supervision for some tasks is missing, thereby bolstering the complementarity of different tasks. Our model was trained on a dataset comprising up to 245,000 images and validated on multiple building extraction and change detection datasets. The experimental results substantiate that RSBuilding can concurrently handle two structurally distinct tasks and exhibits robust zero-shot generalization capabilities.
4/16/2024