Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
2404.12210
0
0
Abstract
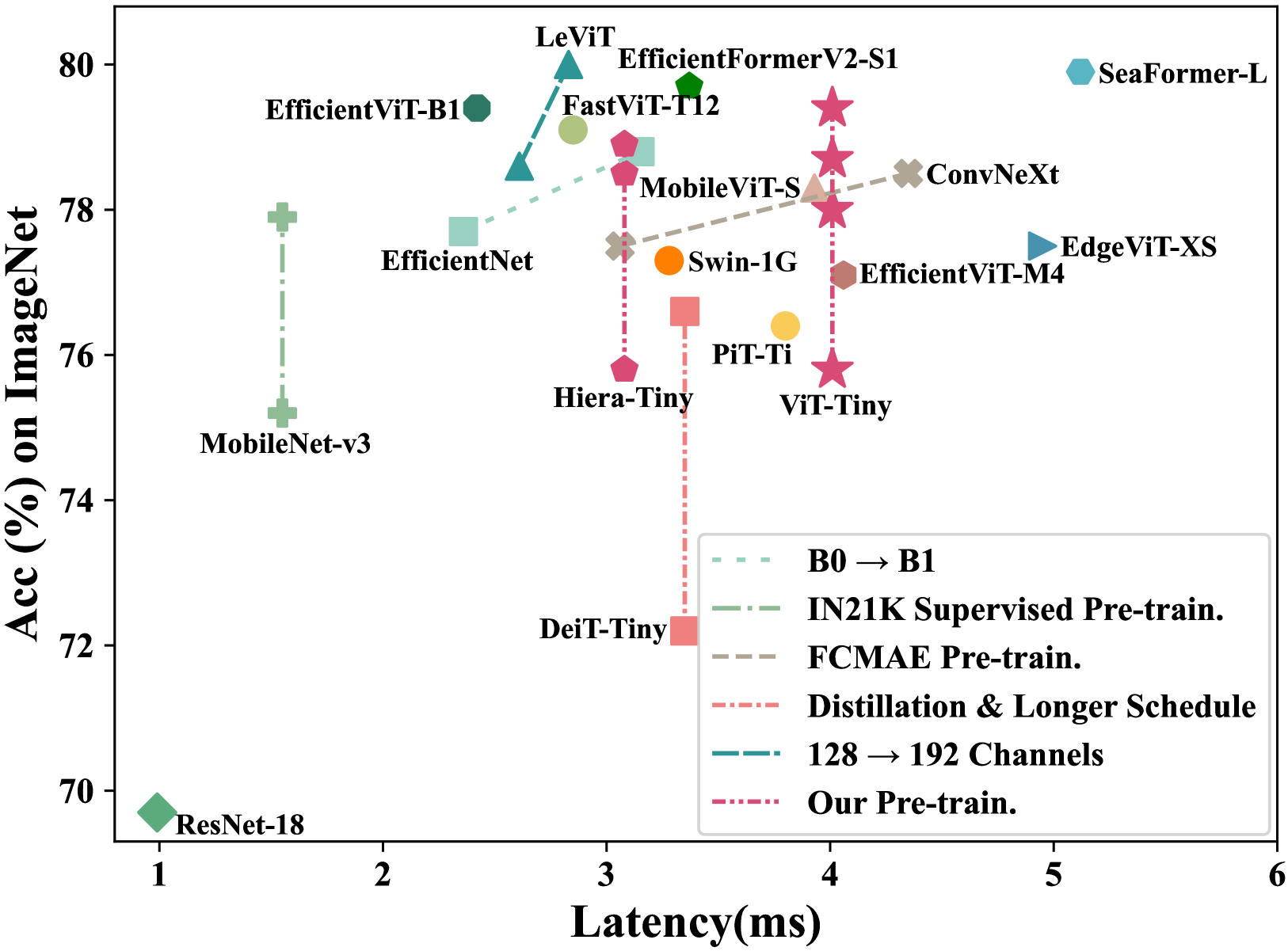
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
Create account to get full access
Overview
- Explores the development of strong and lightweight Vision Transformers (ViT) models through masked image modeling pre-training
- Investigates the impact of various design choices on model performance and efficiency
- Proposes a new lightweight ViT architecture that achieves competitive accuracy while being computationally efficient
Plain English Explanation
This research paper focuses on creating powerful yet efficient computer vision models known as Vision Transformers (ViTs). ViTs are a type of deep learning model that can analyze and understand the contents of images, similar to how humans process visual information.
The researchers explore different ways to train and design ViT models to make them both accurate and lightweight (i.e., computationally efficient). One key technique they investigate is "masked image modeling" - a pre-training process where the model tries to predict parts of an image that have been hidden or "masked" out. This helps the model learn robust visual representations that can be fine-tuned for various computer vision tasks.
The researchers propose a new ViT architecture that incorporates their insights from the masked image modeling experiments. This new model achieves competitive accuracy on standard vision benchmarks while being more computationally efficient than previous ViT designs. This is important because it allows the model to run quickly and use less memory, making it more practical for real-world applications like mobile devices or embedded systems.
Overall, this work contributes to the ongoing effort to develop powerful yet efficient computer vision models that can be widely deployed, benefiting a range of industries and applications.
Technical Explanation
The paper explores the use of masked image modeling pre-training to develop strong and lightweight Vision Transformer (ViT) architectures. Masked image modeling is a self-supervised learning technique where the model attempts to predict masked-out patches of an image, forcing it to learn robust visual representations.
The researchers experiment with different design choices for the ViT model and the masked image modeling pre-training, such as the patch size, number of layers, and attention mechanisms. They analyze the impact of these choices on the model's performance and efficiency, identifying key factors that contribute to accuracy and computational cost.
Building on these insights, the paper proposes a new lightweight ViT architecture called Slim-ViT. Slim-ViT incorporates design elements like shifted-window attention and a careful balance of depth and width to achieve competitive accuracy on ImageNet while being more computationally efficient than previous ViT models.
The paper also investigates the benefits of supervised fine-tuning, where the pre-trained model is further trained on labeled target datasets. This fine-tuning process is shown to improve the model's performance, demonstrating the value of the learned visual representations from the masked image modeling pre-training.
Critical Analysis
The paper provides a comprehensive analysis of the design choices and pre-training techniques that can be used to create strong and efficient ViT models. The authors' experimentation with masked image modeling and their proposed Slim-ViT architecture are promising approaches to developing lightweight computer vision models.
However, the paper does not extensively explore the limitations of the masked image modeling technique or the potential drawbacks of the Slim-ViT design. For example, the paper does not discuss how the model's performance might be affected in specialized or niche computer vision tasks, or how the model's efficiency might scale as the input image size or resolution increases.
Additionally, the paper does not compare the Slim-ViT architecture to other lightweight ViT designs or alternative computer vision model families, such as convolutional neural networks (CNNs) or hybrid ViT-CNN models. A more comparative analysis could help readers better understand the trade-offs and relative strengths of the proposed approach.
Nevertheless, the paper makes valuable contributions to the ongoing research on efficient computer vision models, and the insights and techniques presented could inspire further advancements in this important field.
Conclusion
This research paper explores the development of strong and lightweight Vision Transformer (ViT) models through the use of masked image modeling pre-training. The authors' experimentation with various design choices and their proposed Slim-ViT architecture demonstrate promising approaches to creating efficient computer vision models that can achieve competitive accuracy while being more computationally lightweight.
The findings from this work contribute to the broader effort to develop powerful yet practical deep learning models for a wide range of real-world applications, from mobile devices to embedded systems. By focusing on both model performance and efficiency, the researchers have taken an important step towards making advanced computer vision capabilities more accessible and deployable across diverse use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
0
0
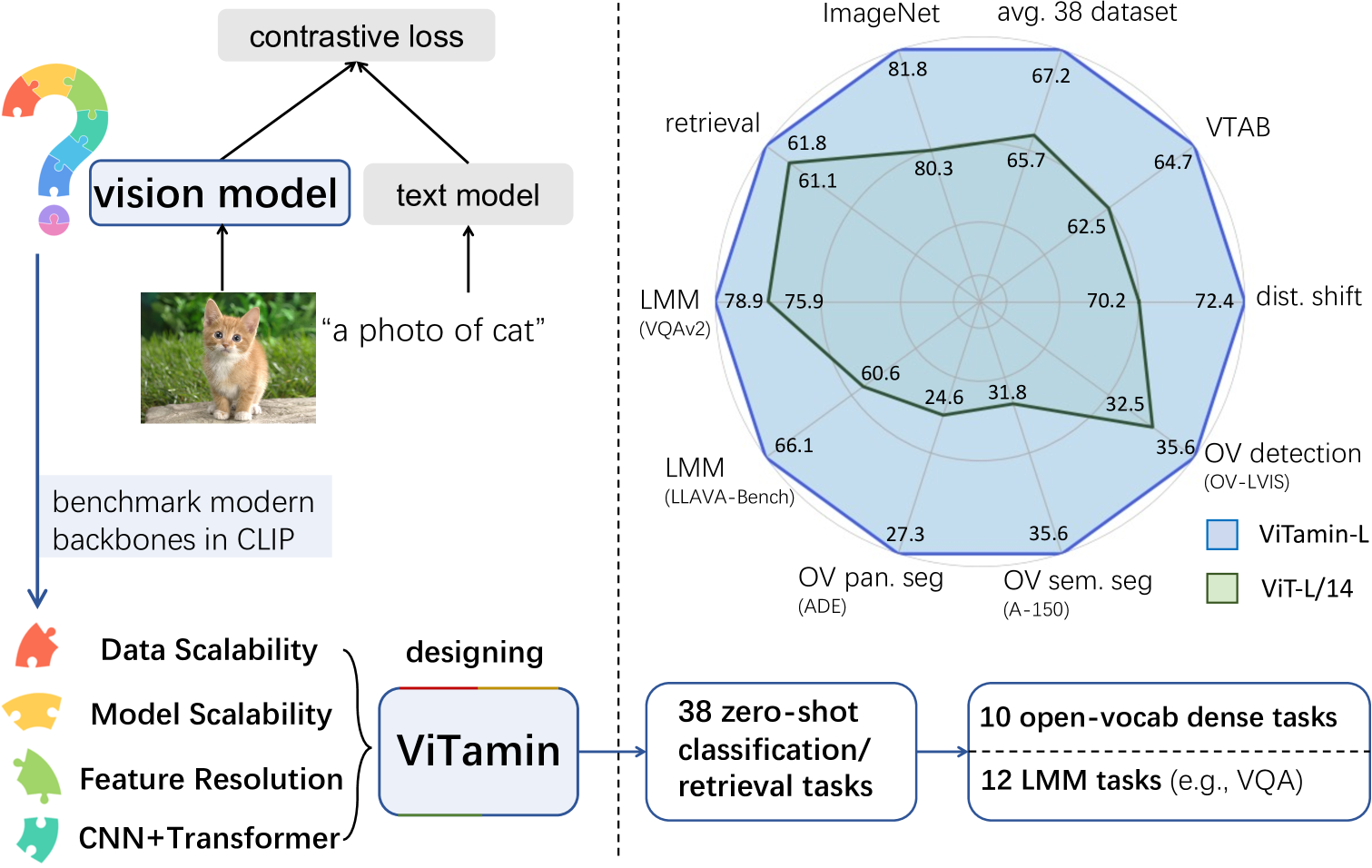
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
4/5/2024
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
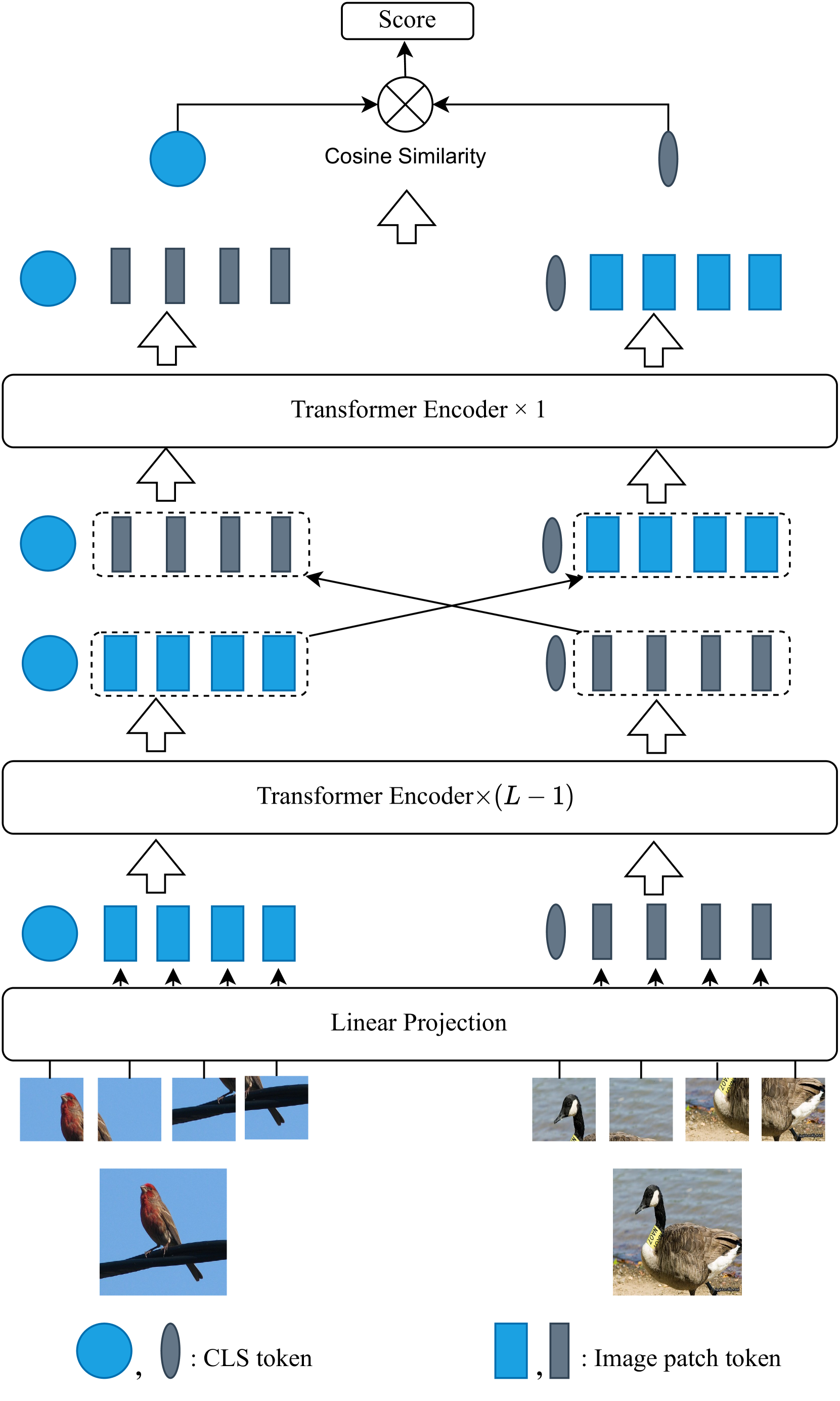
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024

Emerging Property of Masked Token for Effective Pre-training
Hyesong Choi, Hunsang Lee, Seyoung Joung, Hyejin Park, Jiyeong Kim, Dongbo Min
0
0
Driven by the success of Masked Language Modeling (MLM), the realm of self-supervised learning for computer vision has been invigorated by the central role of Masked Image Modeling (MIM) in driving recent breakthroughs. Notwithstanding the achievements of MIM across various downstream tasks, its overall efficiency is occasionally hampered by the lengthy duration of the pre-training phase. This paper presents a perspective that the optimization of masked tokens as a means of addressing the prevailing issue. Initially, we delve into an exploration of the inherent properties that a masked token ought to possess. Within the properties, we principally dedicated to articulating and emphasizing the `data singularity' attribute inherent in masked tokens. Through a comprehensive analysis of the heterogeneity between masked tokens and visible tokens within pre-trained models, we propose a novel approach termed masked token optimization (MTO), specifically designed to improve model efficiency through weight recalibration and the enhancement of the key property of masked tokens. The proposed method serves as an adaptable solution that seamlessly integrates into any MIM approach that leverages masked tokens. As a result, MTO achieves a considerable improvement in pre-training efficiency, resulting in an approximately 50% reduction in pre-training epochs required to attain converged performance of the recent approaches.
4/15/2024
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
0
0
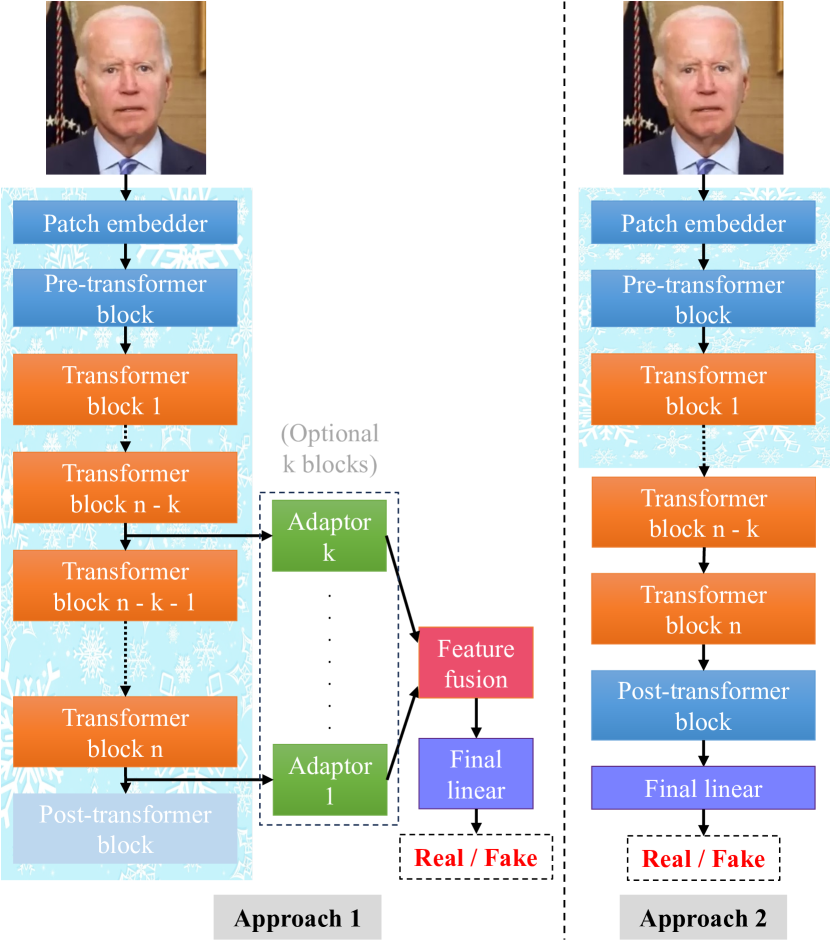
This paper investigates the effectiveness of self-supervised pre-trained transformers compared to supervised pre-trained transformers and conventional neural networks (ConvNets) for detecting various types of deepfakes. We focus on their potential for improved generalization, particularly when training data is limited. Despite the notable success of large vision-language models utilizing transformer architectures in various tasks, including zero-shot and few-shot learning, the deepfake detection community has still shown some reluctance to adopt pre-trained vision transformers (ViTs), especially large ones, as feature extractors. One concern is their perceived excessive capacity, which often demands extensive data, and the resulting suboptimal generalization when training or fine-tuning data is small or less diverse. This contrasts poorly with ConvNets, which have already established themselves as robust feature extractors. Additionally, training and optimizing transformers from scratch requires significant computational resources, making this accessible primarily to large companies and hindering broader investigation within the academic community. Recent advancements in using self-supervised learning (SSL) in transformers, such as DINO and its derivatives, have showcased significant adaptability across diverse vision tasks and possess explicit semantic segmentation capabilities. By leveraging DINO for deepfake detection with modest training data and implementing partial fine-tuning, we observe comparable adaptability to the task and the natural explainability of the detection result via the attention mechanism. Moreover, partial fine-tuning of transformers for deepfake detection offers a more resource-efficient alternative, requiring significantly fewer computational resources.
5/2/2024