ViTamin: Designing Scalable Vision Models in the Vision-Language Era
2404.02132
0
0
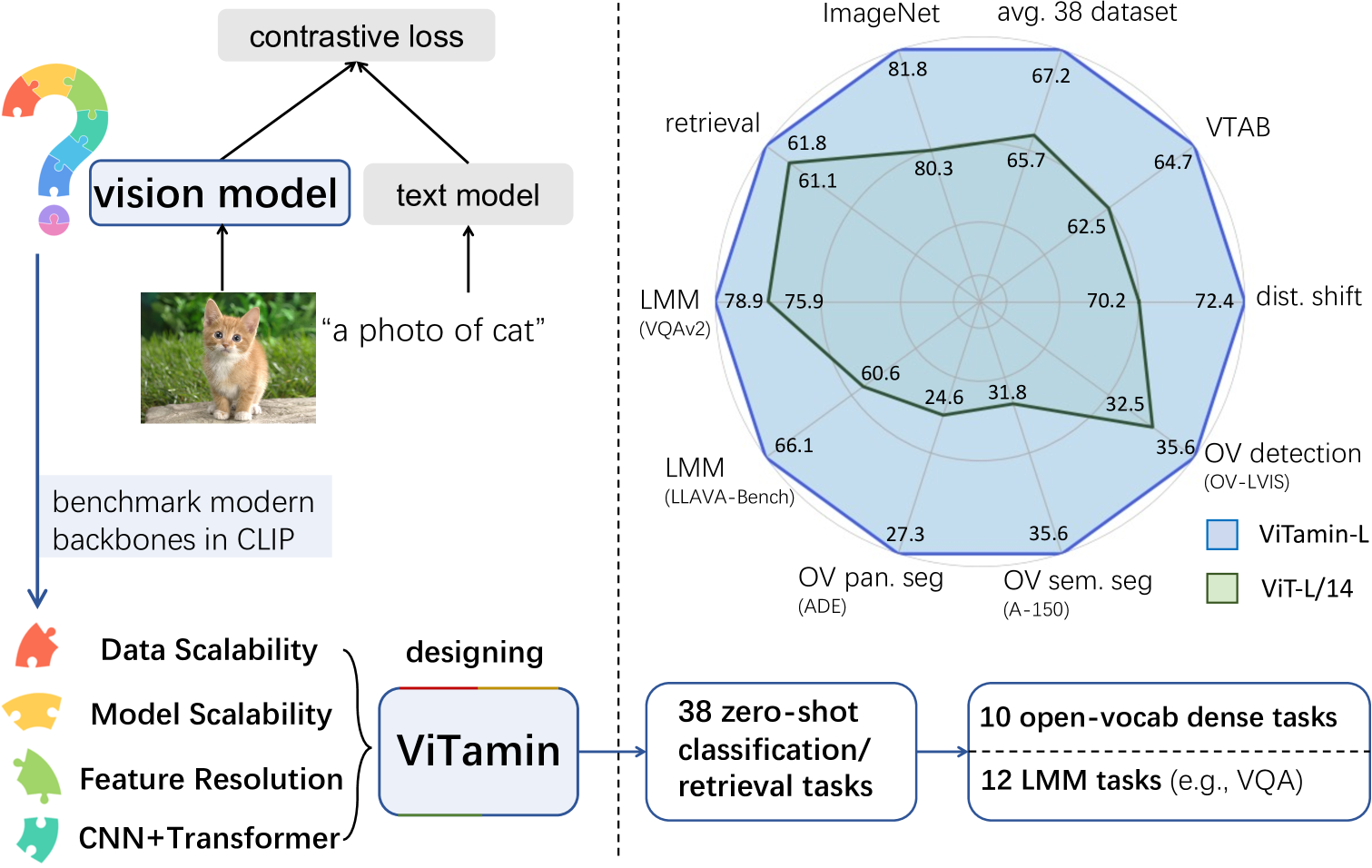
Abstract
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes ViTamin, a new approach for designing scalable vision models in the era of vision-language AI systems.
- The key ideas include using modular and scalable transformer-based architectures, leveraging multi-task learning, and employing efficient pretraining strategies.
- The researchers demonstrate ViTamin's effectiveness on a range of computer vision benchmarks, showing it can achieve state-of-the-art performance while being more efficient and scalable than previous models.
Plain English Explanation
The paper introduces ViTamin, a new way to build powerful vision AI models that can handle a wide variety of tasks. Traditional vision models are often specialized for a single task, like recognizing objects in images. But in the modern era of artificial intelligence, we need models that can understand images in more flexible and comprehensive ways, often in combination with language processing.
ViTamin tackles this challenge by taking a modular and scalable approach. Instead of a single rigid model, ViTamin is built from smaller, interchangeable components that can be combined and scaled up as needed. This allows ViTamin to be more efficient and adaptable than previous vision models.
The key innovations in ViTamin include using transformer-based architectures, which are great at processing visual and language information together. ViTamin also uses multi-task learning, where the model is trained on multiple related tasks at once, allowing it to develop more general and powerful capabilities. And the researchers use clever pretraining strategies to help ViTamin learn effectively from large datasets without excessive computational cost.
Through experiments on standard computer vision benchmarks, the researchers demonstrate that ViTamin can match or exceed the performance of state-of-the-art vision models, while being more efficient and scalable. This suggests ViTamin could be a valuable tool for building the next generation of flexible, high-performing vision-language AI systems.
Technical Explanation
The core of ViTamin is a modular and scalable transformer-based architecture. This allows ViTamin to be efficiently scaled up in depth and width to handle increasing model and task complexity. The backbone is a vision transformer (ViT) that processes visual inputs, combined with language-processing transformer modules to enable multimodal understanding.
ViTamin uses a multi-task learning approach, where the model is trained on multiple related vision and language tasks simultaneously. This encourages the development of more general and transferable capabilities, rather than specialization on a single task.
To enable efficient pretraining, the researchers propose a novel contrastive learning objective that aligns representations of different modalities (e.g. images and text). This pretraining strategy allows ViTamin to learn powerful visual and language representations from large-scale datasets without excessive computational requirements.
The experiments demonstrate ViTamin's strong performance on a range of computer vision benchmarks, including image classification, object detection, and instance segmentation. Compared to previous state-of-the-art models, ViTamin achieves similar or better accuracy while being more parameter-efficient and computationally efficient.
Critical Analysis
The paper provides a thorough technical description of ViTamin and solid empirical evidence of its capabilities. However, the researchers acknowledge some limitations. For example, the current ViTamin model is still trained in a primarily supervised fashion, which may limit its ability to scale to truly open-ended vision-language understanding.
Additionally, while ViTamin shows strong results on standard benchmarks, the researchers do not extensively explore its performance on more challenging, real-world vision-language tasks that require robust multimodal reasoning. Further research is needed to assess ViTamin's generalization and robustness in more diverse and unconstrained settings.
Overall, ViTamin represents an important step forward in designing scalable and efficient vision models for the vision-language era of AI. The modular architecture, multi-task learning, and pretraining strategies are promising directions that could inspire further innovations in this active research area.
Conclusion
The ViTamin paper presents a novel approach for building powerful and scalable vision models that can effectively operate in the emerging vision-language paradigm of artificial intelligence. By introducing a modular transformer-based architecture, multi-task learning, and efficient pretraining techniques, the researchers demonstrate how ViTamin can achieve state-of-the-art performance on computer vision benchmarks while being more parameter- and computationally-efficient than previous models.
This work highlights the importance of rethinking traditional vision models to create more flexible and adaptable AI systems that can seamlessly integrate visual and language understanding. As the field of AI continues to advance, innovations like ViTamin will be crucial for developing the next generation of intelligent systems capable of tackling increasingly complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
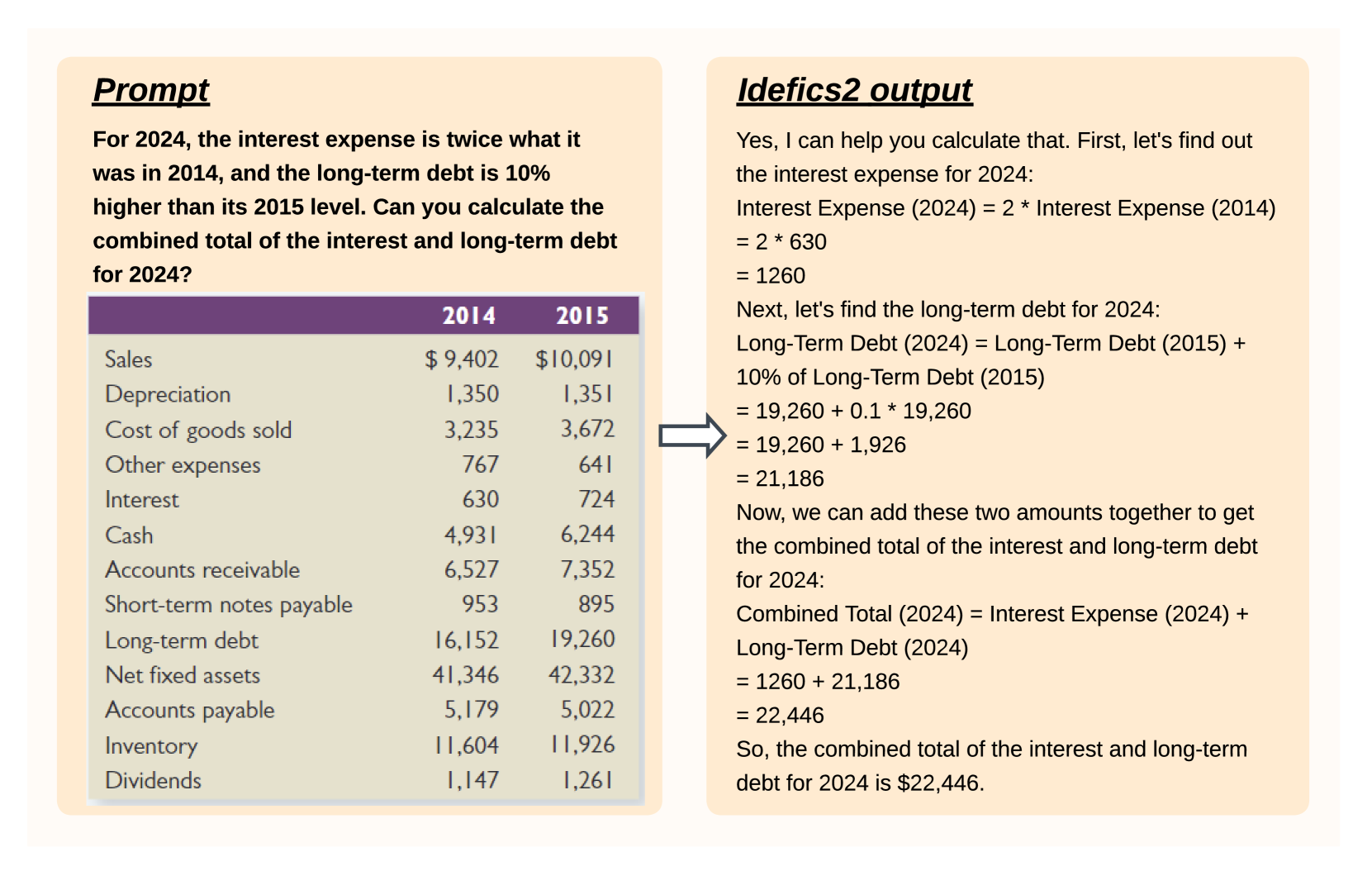
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
0
0
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
5/6/2024

Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
0
0
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
4/17/2024
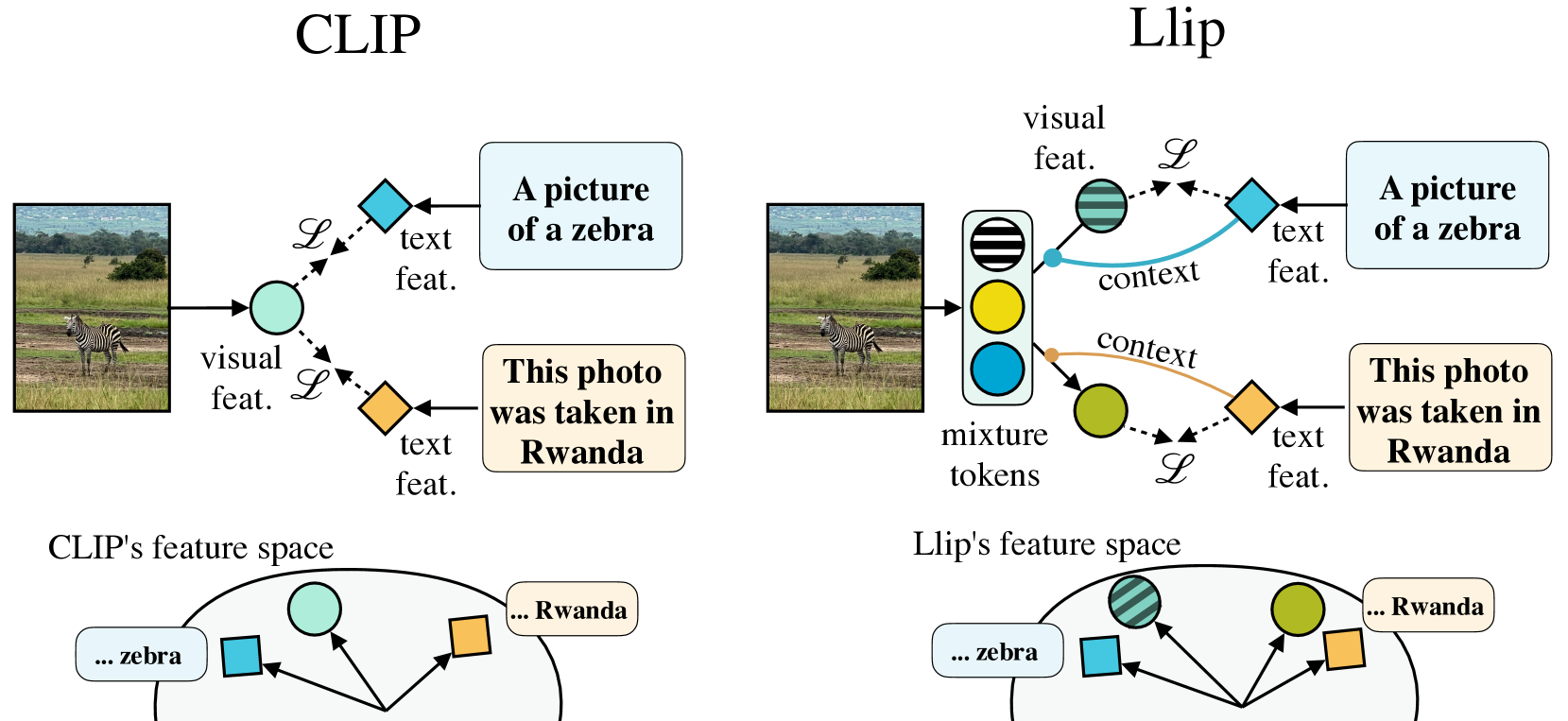
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024
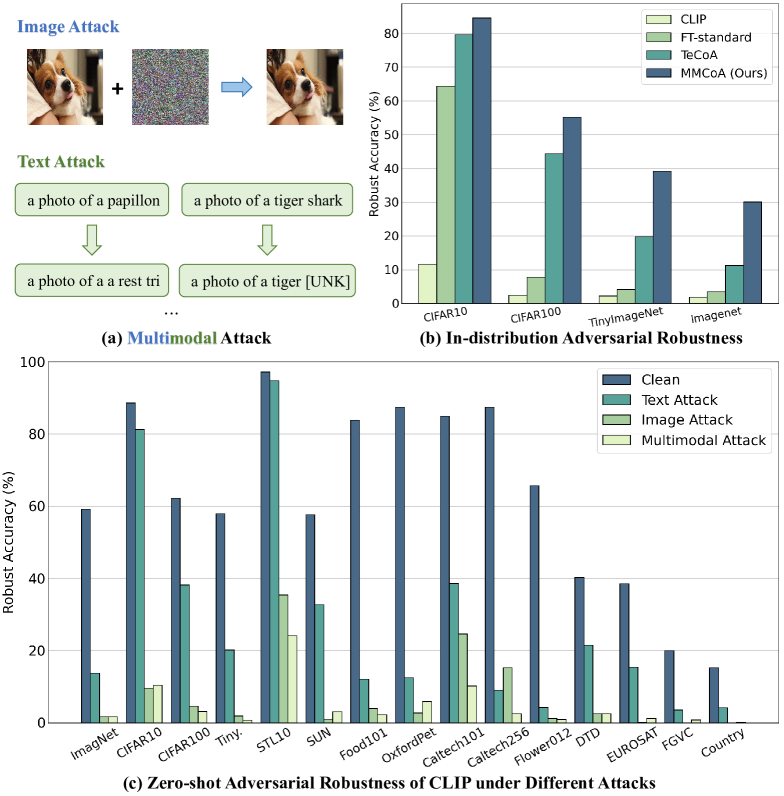
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
0
0
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
5/1/2024