Exploiting Style Latent Flows for Generalizing Deepfake Video Detection

0

Sign in to get full access
Overview
- This paper presents a new approach for detecting deepfake videos that aims to generalize well across diverse datasets and scenarios.
- The key idea is to exploit the style latent flows in deepfake generation, which capture the visual style of the source and target identities.
- By modeling these style latent flows, the proposed method can more effectively distinguish real from fake videos, even when faced with unseen identities or synthesis techniques.
- The paper includes experiments on multiple deepfake detection benchmarks, demonstrating improved generalization compared to prior state-of-the-art approaches.
Plain English Explanation
Deepfake videos, where a person's face is digitally manipulated to look like someone else, are a growing concern as they can be used to spread misinformation or create synthetic media. Latent Forensics: Towards Frugal Deepfake Detection and Towards More General Video-Based Deepfake Detection have shown that analyzing the "style" of a deepfake video - the visual characteristics that are unique to the source and target identities - can help distinguish real from fake footage.
This paper builds on that idea, proposing a new method that more deeply exploits the "style latent flows" in deepfake generation. The key insight is that these style latent flows, which capture how the source and target visual styles are blended together, contain valuable forensic cues that can aid deepfake detection. By modeling these style latent flows, the method can more effectively identify cases where the visual style doesn't match the claimed identity, even if the manipulation is done skillfully.
The paper demonstrates that this approach generalizes better than prior methods, meaning it can accurately detect deepfakes across a wider range of identities, synthesis techniques, and datasets. This is an important capability, as real-world deepfake threats are likely to involve unseen identities and evolving manipulation methods.
Technical Explanation
The paper introduces a new deepfake detection framework called "Style Latent Flow Forensics" (SLFF) that aims to generalize well across diverse deepfake scenarios. The core idea is to exploit the style latent flows - the intermediate latent representations that capture the visual styles of the source and target identities - that are generated during the deepfake synthesis process.
The SLFF architecture consists of two key components: a Style Latent Flow Encoder and a Deepfake Classifier. The Style Latent Flow Encoder takes in video frames and extracts the corresponding style latent flows. These style latent flows are then passed to the Deepfake Classifier, which learns to distinguish real from fake videos based on the patterns in the style latent flows.
Crucially, the SLFF framework is designed to work with different deepfake generation models, such as Disrupting Style Mimicry Attacks on Video Imagery and Compressed Deepfake Video Detection Based on 3D Spatiotemporal Features. This allows the method to generalize to a wider range of deepfake synthesis techniques, beyond just those seen during training.
The paper evaluates SLFF on multiple deepfake detection benchmarks, including Explainable Deepfake Video Detection Using Convolutional Neural Networks, and demonstrates improved generalization performance compared to prior state-of-the-art approaches. The authors also provide detailed ablation studies to analyze the contributions of different components of the SLFF framework.
Critical Analysis
The paper presents a promising approach for improving the generalization of deepfake detection, an important challenge as the threat landscape continues to evolve. The exploitation of style latent flows is a novel and insightful idea, and the evaluation across diverse datasets and synthesis techniques is a strength of the work.
However, the paper does not address some potential limitations and areas for further research. For example, it is not clear how the SLFF framework would perform on highly compressed or low-quality deepfake videos, which are common in real-world scenarios. Additionally, the paper does not discuss the computational efficiency of the approach, which is an important practical consideration for deployable deepfake detection systems.
Furthermore, while the paper demonstrates improved generalization, it would be valuable to understand the specific types of deepfake manipulations and datasets where the SLFF approach excels or struggles. This could help identify the key strengths and weaknesses of the method and guide future research directions.
Overall, the paper makes a valuable contribution to the field of deepfake detection, but there remains room for further exploration and refinement of the proposed techniques to address real-world challenges and limitations.
Conclusion
This paper presents a new deepfake detection framework called "Style Latent Flow Forensics" (SLFF) that aims to generalize well across diverse deepfake scenarios. The key innovation is the exploitation of style latent flows, the intermediate latent representations that capture the visual styles of the source and target identities during deepfake synthesis.
By modeling these style latent flows, the SLFF framework can more effectively distinguish real from fake videos, even when faced with unseen identities or synthesis techniques. The paper demonstrates improved generalization performance compared to prior state-of-the-art approaches on multiple deepfake detection benchmarks.
While the paper makes a valuable contribution to the field, there are still opportunities for further research to address potential limitations, such as the impact of video compression and the specific strengths and weaknesses of the SLFF approach. Continued advancements in generalized deepfake detection will be crucial as the threat landscape evolves and becomes more challenging to address.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploiting Style Latent Flows for Generalizing Deepfake Video Detection
Jongwook Choi, Taehoon Kim, Yonghyun Jeong, Seungryul Baek, Jongwon Choi
This paper presents a new approach for the detection of fake videos, based on the analysis of style latent vectors and their abnormal behavior in temporal changes in the generated videos. We discovered that the generated facial videos suffer from the temporal distinctiveness in the temporal changes of style latent vectors, which are inevitable during the generation of temporally stable videos with various facial expressions and geometric transformations. Our framework utilizes the StyleGRU module, trained by contrastive learning, to represent the dynamic properties of style latent vectors. Additionally, we introduce a style attention module that integrates StyleGRU-generated features with content-based features, enabling the detection of visual and temporal artifacts. We demonstrate our approach across various benchmark scenarios in deepfake detection, showing its superiority in cross-dataset and cross-manipulation scenarios. Through further analysis, we also validate the importance of using temporal changes of style latent vectors to improve the generality of deepfake video detection.
Read more5/21/2024
🔎
0
LatentForensics: Towards frugal deepfake detection in the StyleGAN latent space
Matthieu Delmas, Amine Kacete, Stephane Paquelet, Simon Leglaive, Renaud Seguier
The classification of forged videos has been a challenge for the past few years. Deepfake classifiers can now reliably predict whether or not video frames have been tampered with. However, their performance is tied to both the dataset used for training and the analyst's computational power. We propose a deepfake detection method that operates in the latent space of a state-of-the-art generative adversarial network (GAN) trained on high-quality face images. The proposed method leverages the structure of the latent space of StyleGAN to learn a lightweight binary classification model. Experimental results on standard datasets reveal that the proposed approach outperforms other state-of-the-art deepfake classification methods, especially in contexts where the data available to train the models is rare, such as when a new manipulation method is introduced. To the best of our knowledge, this is the first study showing the interest of the latent space of StyleGAN for deepfake classification. Combined with other recent studies on the interpretation and manipulation of this latent space, we believe that the proposed approach can further help in developing frugal deepfake classification methods based on interpretable high-level properties of face images.
Read more5/7/2024
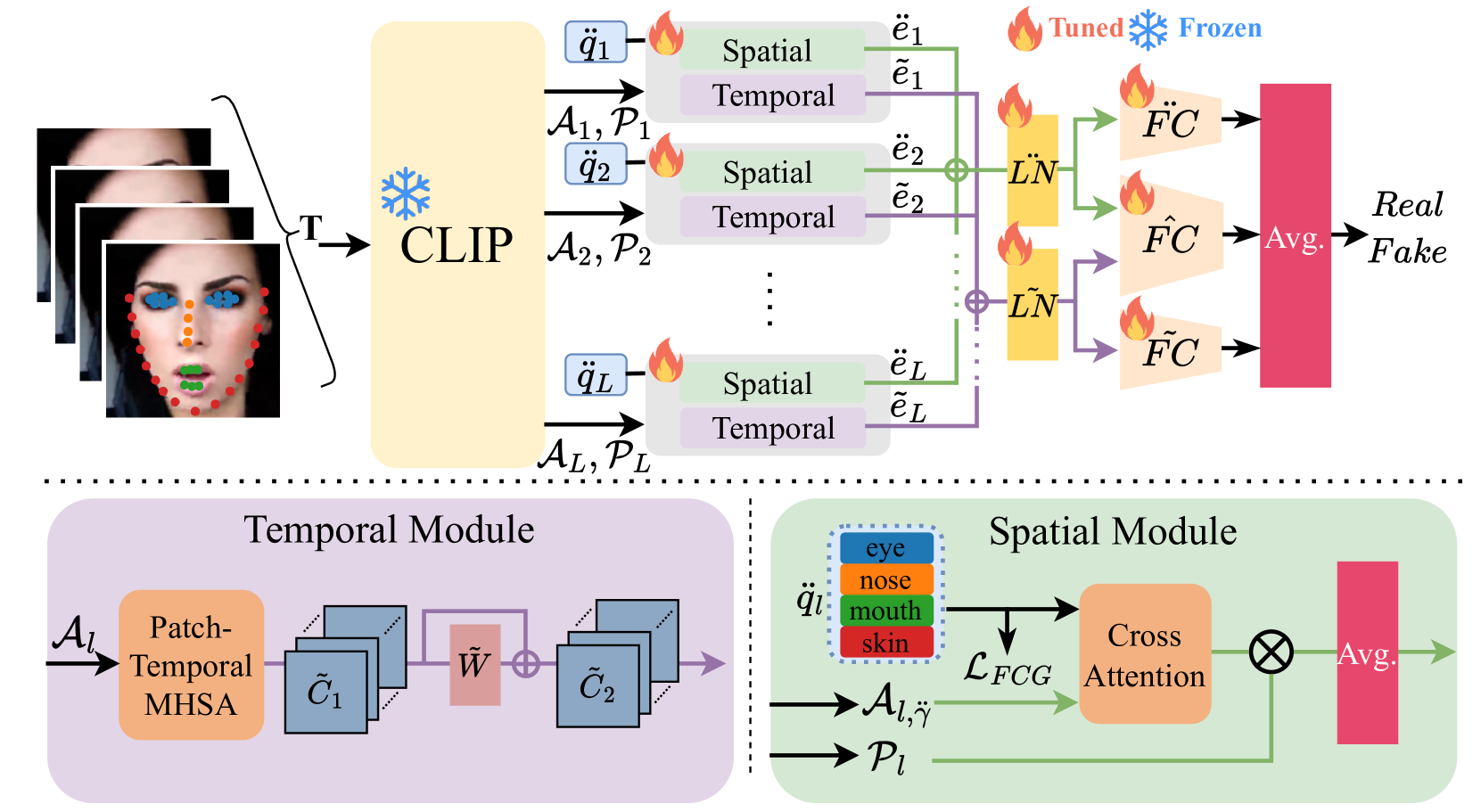
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024

0
What Matters in Detecting AI-Generated Videos like Sora?
Chirui Chang, Zhengzhe Liu, Xiaoyang Lyu, Xiaojuan Qi
Recent advancements in diffusion-based video generation have showcased remarkable results, yet the gap between synthetic and real-world videos remains under-explored. In this study, we examine this gap from three fundamental perspectives: appearance, motion, and geometry, comparing real-world videos with those generated by a state-of-the-art AI model, Stable Video Diffusion. To achieve this, we train three classifiers using 3D convolutional networks, each targeting distinct aspects: vision foundation model features for appearance, optical flow for motion, and monocular depth for geometry. Each classifier exhibits strong performance in fake video detection, both qualitatively and quantitatively. This indicates that AI-generated videos are still easily detectable, and a significant gap between real and fake videos persists. Furthermore, utilizing the Grad-CAM, we pinpoint systematic failures of AI-generated videos in appearance, motion, and geometry. Finally, we propose an Ensemble-of-Experts model that integrates appearance, optical flow, and depth information for fake video detection, resulting in enhanced robustness and generalization ability. Our model is capable of detecting videos generated by Sora with high accuracy, even without exposure to any Sora videos during training. This suggests that the gap between real and fake videos can be generalized across various video generative models. Project page: https://justin-crchang.github.io/3DCNNDetection.github.io/
Read more7/1/2024