Exploiting the Vulnerability of Large Language Models via Defense-Aware Architectural Backdoor

0

Sign in to get full access
Overview
- The paper explores vulnerabilities in large language models (LLMs) and presents a new attack called the "defense-aware architectural backdoor" (DAAB).
- This backdoor can be covertly injected into the model architecture, allowing the attacker to trigger specific behaviors during inference without being detected by existing defense mechanisms.
- The key idea is to exploit the model's complexity and the difficulty of comprehensively validating its internal behavior.
Plain English Explanation
The researchers describe a new way to secretly insert a "backdoor" into large language models (LLMs) like GPT-3 or BERT. A backdoor is a hidden vulnerability that allows an attacker to control the model's behavior, even if the model is deployed with security measures in place.
The researchers' approach, called a "defense-aware architectural backdoor" (DAAB), is designed to be particularly stealthy. Instead of modifying the model's inputs or outputs, the backdoor is embedded directly into the model's internal architecture. This makes it much harder for existing security defenses to detect the backdoor.
The key insight is that LLMs are incredibly complex, with billions of parameters and intricate internal workings. It's virtually impossible to exhaustively test and validate every aspect of the model's behavior. The researchers exploit this complexity to secretly insert their backdoor, which can then be triggered to make the model behave in specific ways that benefit the attacker, without raising any red flags.
Technical Explanation
The paper presents a new attack called the "defense-aware architectural backdoor" (DAAB), which can be covertly inserted into the architecture of large language models (LLMs). This attack exploits the inherent complexity of LLMs to bypass existing defense mechanisms.
The researchers design a backdoor module that can be seamlessly integrated into the model's architecture. This module is trained to activate specific behaviors, such as generating malicious output, when triggered by a particular input pattern. Critically, the module is designed to evade detection by security defenses that aim to identify and remove backdoors.
The key innovation is the "defense-aware" aspect of the DAAB, which allows the backdoor to remain hidden even when the model is subjected to common backdoor detection techniques. The researchers demonstrate the effectiveness of their approach through extensive experiments on various LLM architectures and datasets.
Critical Analysis
The paper raises significant concerns about the security and robustness of large language models, which are becoming increasingly ubiquitous in various applications. The authors' "defense-aware architectural backdoor" highlights the challenges in comprehensively validating the behavior of these complex models, even when security measures are in place.
While the paper provides a rigorous technical implementation and evaluation of the DAAB attack, it does not address several important considerations. For example, the paper does not discuss the potential real-world impacts or misuse cases of such an attack, nor does it propose concrete mitigation strategies beyond the limitations of existing defenses.
Additionally, the researchers focus solely on the technical aspects of the attack, without fully contextualizing the broader implications for the development and deployment of large language models. Further research is needed to explore the social and ethical considerations surrounding these vulnerabilities, as well as to develop more robust and comprehensive defense mechanisms.
Conclusion
The paper presents a novel attack called the "defense-aware architectural backdoor" (DAAB), which exploits the inherent complexity of large language models to covertly insert a backdoor that can bypass existing security defenses. This research highlights the significant challenges in ensuring the security and reliability of these powerful AI systems, which are increasingly being deployed in high-stakes applications.
While the technical details of the DAAB attack are concerning, the broader implications of this vulnerability warrant further investigation and discussion. Addressing these issues will be crucial as large language models continue to play a more prominent role in shaping our digital landscapes and influencing important decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploiting the Vulnerability of Large Language Models via Defense-Aware Architectural Backdoor
Abdullah Arafat Miah, Yu Bi
Deep neural networks (DNNs) have long been recognized as vulnerable to backdoor attacks. By providing poisoned training data in the fine-tuning process, the attacker can implant a backdoor into the victim model. This enables input samples meeting specific textual trigger patterns to be classified as target labels of the attacker's choice. While such black-box attacks have been well explored in both computer vision and natural language processing (NLP), backdoor attacks relying on white-box attack philosophy have hardly been thoroughly investigated. In this paper, we take the first step to introduce a new type of backdoor attack that conceals itself within the underlying model architecture. Specifically, we propose to design separate backdoor modules consisting of two functions: trigger detection and noise injection. The add-on modules of model architecture layers can detect the presence of input trigger tokens and modify layer weights using Gaussian noise to disturb the feature distribution of the baseline model. We conduct extensive experiments to evaluate our attack methods using two model architecture settings on five different large language datasets. We demonstrate that the training-free architectural backdoor on a large language model poses a genuine threat. Unlike the-state-of-art work, it can survive the rigorous fine-tuning and retraining process, as well as evade output probability-based defense methods (i.e. BDDR). All the code and data is available https://github.com/SiSL-URI/Arch_Backdoor_LLM.
Read more9/10/2024

0
A Survey of Backdoor Attacks and Defenses on Large Language Models: Implications for Security Measures
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, Xiaoyu Xu, Xiaobao Wu, Jie Fu, Yichao Feng, Fengjun Pan, Luu Anh Tuan
Large Language Models (LLMs), which bridge the gap between human language understanding and complex problem-solving, achieve state-of-the-art performance on several NLP tasks, particularly in few-shot and zero-shot settings. Despite the demonstrable efficacy of LLMs, due to constraints on computational resources, users have to engage with open-source language models or outsource the entire training process to third-party platforms. However, research has demonstrated that language models are susceptible to potential security vulnerabilities, particularly in backdoor attacks. Backdoor attacks are designed to introduce targeted vulnerabilities into language models by poisoning training samples or model weights, allowing attackers to manipulate model responses through malicious triggers. While existing surveys on backdoor attacks provide a comprehensive overview, they lack an in-depth examination of backdoor attacks specifically targeting LLMs. To bridge this gap and grasp the latest trends in the field, this paper presents a novel perspective on backdoor attacks for LLMs by focusing on fine-tuning methods. Specifically, we systematically classify backdoor attacks into three categories: full-parameter fine-tuning, parameter-efficient fine-tuning, and no fine-tuning Based on insights from a substantial review, we also discuss crucial issues for future research on backdoor attacks, such as further exploring attack algorithms that do not require fine-tuning, or developing more covert attack algorithms.
Read more9/14/2024
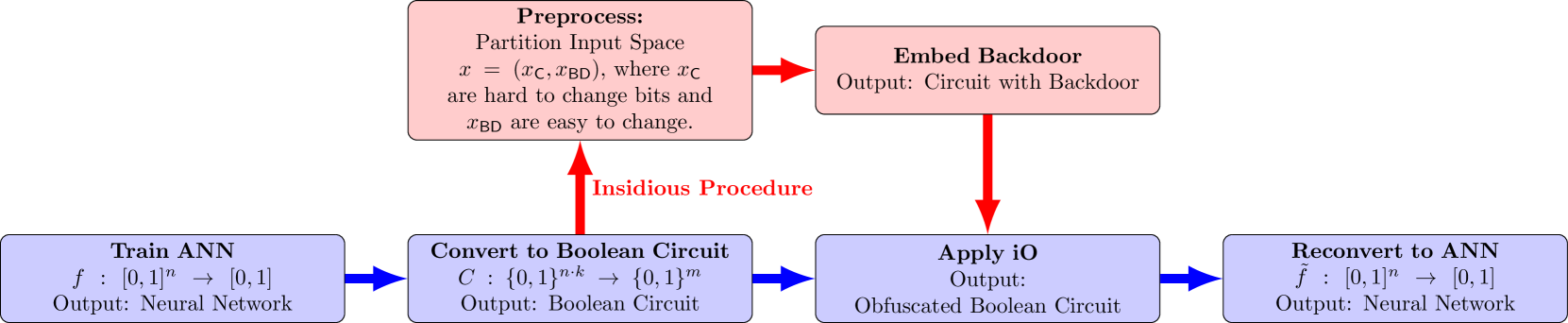
0
Injecting Undetectable Backdoors in Deep Learning and Language Models
Alkis Kalavasis, Amin Karbasi, Argyris Oikonomou, Katerina Sotiraki, Grigoris Velegkas, Manolis Zampetakis
As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors, as defined in Goldwasser et al. (FOCS '22), in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information on how to slightly perturb their input to change the outcome of the model. We develop a general strategy to plant backdoors to obfuscated neural networks, that satisfy the security properties of the celebrated notion of indistinguishability obfuscation. Applying obfuscation before releasing neural networks is a strategy that is well motivated to protect sensitive information of the external expert firm. Our method to plant backdoors ensures that even if the weights and architecture of the obfuscated model are accessible, the existence of the backdoor is still undetectable. Finally, we introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.
Read more9/10/2024
💬
0
Exploring Backdoor Attacks against Large Language Model-based Decision Making
Ruochen Jiao, Shaoyuan Xie, Justin Yue, Takami Sato, Lixu Wang, Yixuan Wang, Qi Alfred Chen, Qi Zhu
Large Language Models (LLMs) have shown significant promise in decision-making tasks when fine-tuned on specific applications, leveraging their inherent common sense and reasoning abilities learned from vast amounts of data. However, these systems are exposed to substantial safety and security risks during the fine-tuning phase. In this work, we propose the first comprehensive framework for Backdoor Attacks against LLM-enabled Decision-making systems (BALD), systematically exploring how such attacks can be introduced during the fine-tuning phase across various channels. Specifically, we propose three attack mechanisms and corresponding backdoor optimization methods to attack different components in the LLM-based decision-making pipeline: word injection, scenario manipulation, and knowledge injection. Word injection embeds trigger words directly into the query prompt. Scenario manipulation occurs in the physical environment, where a high-level backdoor semantic scenario triggers the attack. Knowledge injection conducts backdoor attacks on retrieval augmented generation (RAG)-based LLM systems, strategically injecting word triggers into poisoned knowledge while ensuring the information remains factually accurate for stealthiness. We conduct extensive experiments with three popular LLMs (GPT-3.5, LLaMA2, PaLM2), using two datasets (HighwayEnv, nuScenes), and demonstrate the effectiveness and stealthiness of our backdoor triggers and mechanisms. Finally, we critically assess the strengths and weaknesses of our proposed approaches, highlight the inherent vulnerabilities of LLMs in decision-making tasks, and evaluate potential defenses to safeguard LLM-based decision making systems.
Read more6/3/2024