Injecting Undetectable Backdoors in Deep Learning and Language Models

0
Sign in to get full access
Overview
- This research paper explores the development of undetectable backdoors in deep learning and language models.
- The authors present techniques for injecting hidden vulnerabilities into these AI systems that can be triggered by specific inputs.
- The goal is to create backdoors that are invisible to both model owners and end-users, allowing for potential exploitation.
- The paper builds on previous work on invisible backdoor attacks and analyzing the inner mechanisms of backdoored language models.
Plain English Explanation
The researchers in this paper have discovered ways to secretly insert hidden vulnerabilities, called "backdoors," into deep learning and language models. These backdoors allow the models to be manipulated in invisible ways, without the knowledge of the people who created the models or the people using them.
Imagine a computer program that can do complex tasks like understanding and generating human language. The researchers found that they could make changes to the inner workings of this program, so that if you give it a specific type of input, it will do something unexpected and potentially harmful, even though everything looks normal on the outside.
This is concerning because these AI models are being used for important applications like medical diagnosis, financial decisions, and even national security. If they have hidden vulnerabilities, they could be exploited by bad actors without anyone realizing it. The researchers' goal is to draw attention to this issue and hopefully inspire work on making these AI systems more secure and trustworthy.
Technical Explanation
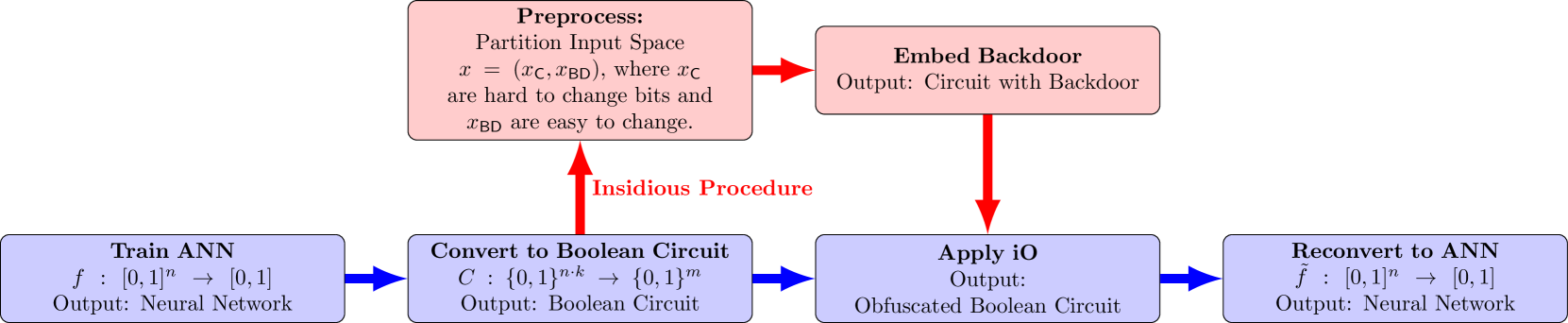
The paper presents several techniques for injecting undetectable backdoors into deep learning and language models. This builds on previous work on invisible backdoor attacks and analyzing the inner mechanisms of backdoored language models.
One approach is to leverage the cryptographic properties of transformer architectures, which are widely used in state-of-the-art language models. The researchers show how they can hide backdoor triggers within the model parameters in a way that is resistant to existing detection methods.
They also demonstrate invisible backdoor attacks on diffusion models, which are a type of generative AI used for tasks like image synthesis. And they present a mask-based approach for inserting invisible backdoors into object detection models.
Through extensive experiments, the authors validate the effectiveness of their techniques and show that the backdoors are extremely difficult to detect, even with access to the model's internals.
Critical Analysis
The research presented in this paper is concerning, as it highlights serious vulnerabilities in state-of-the-art AI systems. The authors acknowledge that their work could potentially be misused by bad actors, and they call for increased scrutiny and security measures in the development and deployment of these powerful technologies.
One limitation of the paper is that it does not provide a comprehensive solution to the backdoor problem. While the authors describe various detection and mitigation strategies, there is still much work to be done to make AI systems truly secure against these types of attacks.
Additionally, the paper focuses primarily on the technical aspects of the backdoor injection process, without delving deeply into the broader ethical and societal implications. As these AI models become more widely deployed, it will be critical to consider the potential for misuse and to develop robust governance frameworks to ensure they are used responsibly.
Conclusion
This research paper demonstrates that deep learning and language models can be secretly compromised through the injection of undetectable backdoors. The authors have developed techniques that allow for the exploitation of these AI systems, even by those without direct access to their inner workings.
While this work is concerning, it is also an important step in bringing attention to this critical issue. By highlighting these vulnerabilities, the researchers hope to spur further research and development of more secure and trustworthy AI systems. As these technologies become increasingly integral to our society, ensuring their safety and reliability must be a top priority.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Injecting Undetectable Backdoors in Deep Learning and Language Models
Alkis Kalavasis, Amin Karbasi, Argyris Oikonomou, Katerina Sotiraki, Grigoris Velegkas, Manolis Zampetakis
As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors, as defined in Goldwasser et al. (FOCS '22), in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information on how to slightly perturb their input to change the outcome of the model. We develop a general strategy to plant backdoors to obfuscated neural networks, that satisfy the security properties of the celebrated notion of indistinguishability obfuscation. Applying obfuscation before releasing neural networks is a strategy that is well motivated to protect sensitive information of the external expert firm. Our method to plant backdoors ensures that even if the weights and architecture of the obfuscated model are accessible, the existence of the backdoor is still undetectable. Finally, we introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.
Read more9/10/2024

0
Exploiting the Vulnerability of Large Language Models via Defense-Aware Architectural Backdoor
Abdullah Arafat Miah, Yu Bi
Deep neural networks (DNNs) have long been recognized as vulnerable to backdoor attacks. By providing poisoned training data in the fine-tuning process, the attacker can implant a backdoor into the victim model. This enables input samples meeting specific textual trigger patterns to be classified as target labels of the attacker's choice. While such black-box attacks have been well explored in both computer vision and natural language processing (NLP), backdoor attacks relying on white-box attack philosophy have hardly been thoroughly investigated. In this paper, we take the first step to introduce a new type of backdoor attack that conceals itself within the underlying model architecture. Specifically, we propose to design separate backdoor modules consisting of two functions: trigger detection and noise injection. The add-on modules of model architecture layers can detect the presence of input trigger tokens and modify layer weights using Gaussian noise to disturb the feature distribution of the baseline model. We conduct extensive experiments to evaluate our attack methods using two model architecture settings on five different large language datasets. We demonstrate that the training-free architectural backdoor on a large language model poses a genuine threat. Unlike the-state-of-art work, it can survive the rigorous fine-tuning and retraining process, as well as evade output probability-based defense methods (i.e. BDDR). All the code and data is available https://github.com/SiSL-URI/Arch_Backdoor_LLM.
Read more9/10/2024

0
Rethinking Backdoor Detection Evaluation for Language Models
Jun Yan, Wenjie Jacky Mo, Xiang Ren, Robin Jia
Backdoor attacks, in which a model behaves maliciously when given an attacker-specified trigger, pose a major security risk for practitioners who depend on publicly released language models. Backdoor detection methods aim to detect whether a released model contains a backdoor, so that practitioners can avoid such vulnerabilities. While existing backdoor detection methods have high accuracy in detecting backdoored models on standard benchmarks, it is unclear whether they can robustly identify backdoors in the wild. In this paper, we examine the robustness of backdoor detectors by manipulating different factors during backdoor planting. We find that the success of existing methods highly depends on how intensely the model is trained on poisoned data during backdoor planting. Specifically, backdoors planted with either more aggressive or more conservative training are significantly more difficult to detect than the default ones. Our results highlight a lack of robustness of existing backdoor detectors and the limitations in current benchmark construction.
Read more9/4/2024

0
Unelicitable Backdoors in Language Models via Cryptographic Transformer Circuits
Andis Draguns, Andrew Gritsevskiy, Sumeet Ramesh Motwani, Charlie Rogers-Smith, Jeffrey Ladish, Christian Schroeder de Witt
The rapid proliferation of open-source language models significantly increases the risks of downstream backdoor attacks. These backdoors can introduce dangerous behaviours during model deployment and can evade detection by conventional cybersecurity monitoring systems. In this paper, we introduce a novel class of backdoors in autoregressive transformer models, that, in contrast to prior art, are unelicitable in nature. Unelicitability prevents the defender from triggering the backdoor, making it impossible to evaluate or detect ahead of deployment even if given full white-box access and using automated techniques, such as red-teaming or certain formal verification methods. We show that our novel construction is not only unelicitable thanks to using cryptographic techniques, but also has favourable robustness properties. We confirm these properties in empirical investigations, and provide evidence that our backdoors can withstand state-of-the-art mitigation strategies. Additionally, we expand on previous work by showing that our universal backdoors, while not completely undetectable in white-box settings, can be harder to detect than some existing designs. By demonstrating the feasibility of seamlessly integrating backdoors into transformer models, this paper fundamentally questions the efficacy of pre-deployment detection strategies. This offers new insights into the offence-defence balance in AI safety and security.
Read more6/6/2024