An Exploration of Length Generalization in Transformer-Based Speech Enhancement
2406.11401
0
0

Abstract
The use of Transformer architectures has facilitated remarkable progress in speech enhancement. Training Transformers using substantially long speech utterances is often infeasible as self-attention suffers from quadratic complexity. It is a critical and unexplored challenge for a Transformer-based speech enhancement model to learn from short speech utterances and generalize to longer ones. In this paper, we conduct comprehensive experiments to explore the length generalization problem in speech enhancement with Transformer. Our findings first establish that position embedding provides an effective instrument to alleviate the impact of utterance length on Transformer-based speech enhancement. Specifically, we explore four different position embedding schemes to enable length generalization. The results confirm the superiority of relative position embeddings (RPEs) over absolute PE (APEs) in length generalization.
Create account to get full access
Overview
- This paper explores the ability of Transformer-based models to generalize to different input lengths in the context of speech enhancement.
- The researchers investigate various strategies for improving the length generalization capabilities of Transformer models, including positional encoding and causal masking.
- The paper provides insights into the strengths and limitations of Transformer architectures for tasks that require handling variable-length inputs.
Plain English Explanation
Speech enhancement is the process of improving the quality of audio signals, such as reducing background noise or improving clarity. Transformer models, a type of deep learning architecture, have shown promise in this area, but they can struggle to handle inputs of different lengths.
The researchers in this paper wanted to understand how well Transformer models can generalize to speech samples of different durations. They tested different techniques, like adjusting the model's position encoding or using causal masking, to see if these could improve the model's ability to handle variable-length inputs.
The key findings of the paper are that Transformer models can indeed have trouble generalizing to different input lengths, but there are some strategies that can help. For example, using position encoding that is not tied to the input length can improve performance. The researchers also found that causal masking, which limits the model's access to future information, can be beneficial for length generalization.
Overall, this paper provides valuable insights into the strengths and limitations of Transformer models for speech enhancement tasks that require handling inputs of varying lengths. The findings could help inform the development of more robust and versatile Transformer-based speech processing systems.
Technical Explanation
The paper explores the ability of Transformer-based models to generalize to different input lengths in the context of speech enhancement. Transformer models, which rely on self-attention mechanisms, have shown strong performance in various speech processing tasks. However, their ability to handle variable-length inputs, a common requirement in real-world speech applications, is not well understood.
The researchers investigate several strategies for improving the length generalization capabilities of Transformer models. This includes exploring the role of positional encoding, which is used to inject information about the position of each input element, and causal masking, which limits the model's access to future information.
The paper presents experiments comparing the performance of Transformer models on speech enhancement tasks with varying input lengths. The results show that Transformer models can struggle to generalize to inputs of different durations, and the researchers explore techniques to mitigate this issue.
One key finding is that using position encoding that is not tied to the input length, such as sinusoidal position encoding or learned position encoding, can improve length generalization performance. The researchers also demonstrate the benefits of causal masking, which restricts the model's access to future information and can help with length extrapolation.
Additionally, the paper explores other approaches, such as resonance rope, which aims to improve the model's ability to capture long-range dependencies, and theoretical analysis of the factors that influence length generalization in Transformer-based models.
Critical Analysis
The paper provides a comprehensive exploration of length generalization in Transformer-based speech enhancement models, identifying key factors that can influence their performance. The researchers have conducted a thorough set of experiments and provided valuable insights into the challenges and potential solutions for this important problem.
One potential caveat is that the paper focuses primarily on the specific task of speech enhancement, and the findings may not directly translate to other domains where Transformer models are used. However, the underlying principles and techniques discussed are likely to be applicable to a broader range of variable-length input tasks.
Additionally, the paper does not delve into the computational complexity or resource requirements of the various techniques explored, which could be an important consideration for real-world deployment. Further research may be needed to understand the trade-offs between length generalization performance and model efficiency.
Overall, this paper makes a valuable contribution to the understanding of Transformer models and their ability to handle variable-length inputs. The insights and strategies presented could inform the development of more robust and versatile speech processing systems, as well as inspire further research in this important area.
Conclusion
This paper explores the length generalization capabilities of Transformer-based models in the context of speech enhancement. The researchers investigate various strategies, such as position encoding and causal masking, to improve the models' ability to handle inputs of different durations.
The key findings of the paper highlight the challenges Transformer models can face when dealing with variable-length inputs and provide insights into potential solutions. The researchers demonstrate that techniques like using position encoding that is not tied to the input length and applying causal masking can enhance the models' length generalization performance.
The insights from this paper could have significant implications for the development of Transformer-based speech processing systems that need to handle a wide range of input lengths. The strategies explored could also be applicable to other domains where Transformer models are used with variable-length inputs, contributing to the broader understanding of the strengths and limitations of these architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
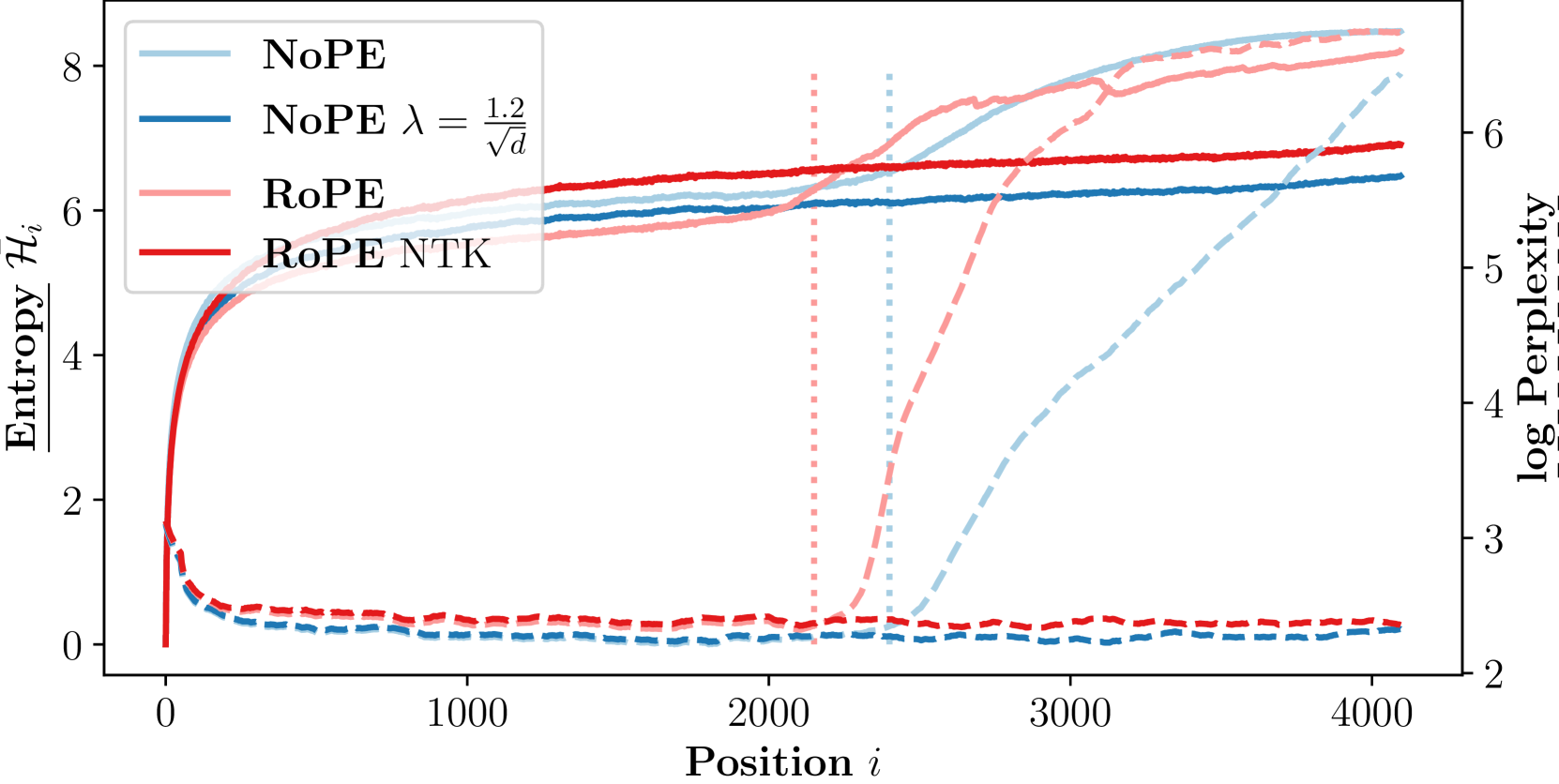
Length Generalization of Causal Transformers without Position Encoding
Jie Wang, Tao Ji, Yuanbin Wu, Hang Yan, Tao Gui, Qi Zhang, Xuanjing Huang, Xiaoling Wang
0
0
Generalizing to longer sentences is important for recent Transformer-based language models. Besides algorithms manipulating explicit position features, the success of Transformers without position encodings (NoPE) provides a new way to overcome the challenge. In this paper, we study the length generalization property of NoPE. We find that although NoPE can extend to longer sequences than the commonly used explicit position encodings, it still has a limited context length. We identify a connection between the failure of NoPE's generalization and the distraction of attention distributions. We propose a parameter-efficient tuning for searching attention heads' best temperature hyper-parameters, which substantially expands NoPE's context size. Experiments on long sequence language modeling, the synthetic passkey retrieval task and real-world long context tasks show that NoPE can achieve competitive performances with state-of-the-art length generalization algorithms. The source code is publicly accessible
5/29/2024

Length Extrapolation of Transformers: A Survey from the Perspective of Positional Encoding
Liang Zhao, Xiaocheng Feng, Xiachong Feng, Dongliang Xu, Qing Yang, Hongtao Liu, Bing Qin, Ting Liu
0
0
Transformer has taken the field of natural language processing (NLP) by storm since its birth. Further, Large language models (LLMs) built upon it have captured worldwide attention due to its superior abilities. Nevertheless, all Transformer-based models including these powerful LLMs suffer from a preset length limit and can hardly generalize from short training sequences to longer inference ones, namely, they can not perform length extrapolation. Hence, a plethora of methods have been proposed to enhance length extrapolation of Transformer, in which the positional encoding (PE) is recognized as the major factor. In this survey, we present these advances towards length extrapolation in a unified notation from the perspective of PE. Specifically, we first introduce extrapolatable PEs, including absolute and relative PEs. Then, we dive into extrapolation methods based on them, covering position interpolation and randomized position methods. Finally, several challenges and future directions in this area are highlighted. Through this survey, We aim to enable the reader to gain a deep understanding of existing methods and provide stimuli for future research.
4/3/2024
🔗
From Interpolation to Extrapolation: Complete Length Generalization for Arithmetic Transformers
Shaoxiong Duan, Yining Shi, Wei Xu
0
0
In this paper, we investigate the inherent capabilities of transformer models in learning arithmetic algorithms, such as addition and parity. Through experiments and attention analysis, we identify a number of crucial factors for achieving optimal length generalization. We show that transformer models are able to generalize to long lengths with the help of targeted attention biasing. In particular, our solution solves the Parity task, a well-known and theoretically proven failure mode for Transformers. We then introduce Attention Bias Calibration (ABC), a calibration stage that enables the model to automatically learn the proper attention biases, which we show to be connected to mechanisms in relative position encoding. We demonstrate that using ABC, the transformer model can achieve unprecedented near-perfect length generalization on certain arithmetic tasks. In addition, we show that ABC bears remarkable similarities to RPE and LoRA, which may indicate the potential for applications to more complex tasks.
5/13/2024

What Improves the Generalization of Graph Transformers? A Theoretical Dive into the Self-attention and Positional Encoding
Hongkang Li, Meng Wang, Tengfei Ma, Sijia Liu, Zaixi Zhang, Pin-Yu Chen
0
0
Graph Transformers, which incorporate self-attention and positional encoding, have recently emerged as a powerful architecture for various graph learning tasks. Despite their impressive performance, the complex non-convex interactions across layers and the recursive graph structure have made it challenging to establish a theoretical foundation for learning and generalization. This study introduces the first theoretical investigation of a shallow Graph Transformer for semi-supervised node classification, comprising a self-attention layer with relative positional encoding and a two-layer perceptron. Focusing on a graph data model with discriminative nodes that determine node labels and non-discriminative nodes that are class-irrelevant, we characterize the sample complexity required to achieve a desirable generalization error by training with stochastic gradient descent (SGD). This paper provides the quantitative characterization of the sample complexity and number of iterations for convergence dependent on the fraction of discriminative nodes, the dominant patterns, and the initial model errors. Furthermore, we demonstrate that self-attention and positional encoding enhance generalization by making the attention map sparse and promoting the core neighborhood during training, which explains the superior feature representation of Graph Transformers. Our theoretical results are supported by empirical experiments on synthetic and real-world benchmarks.
6/5/2024