Length Generalization of Causal Transformers without Position Encoding
2404.12224
0
0
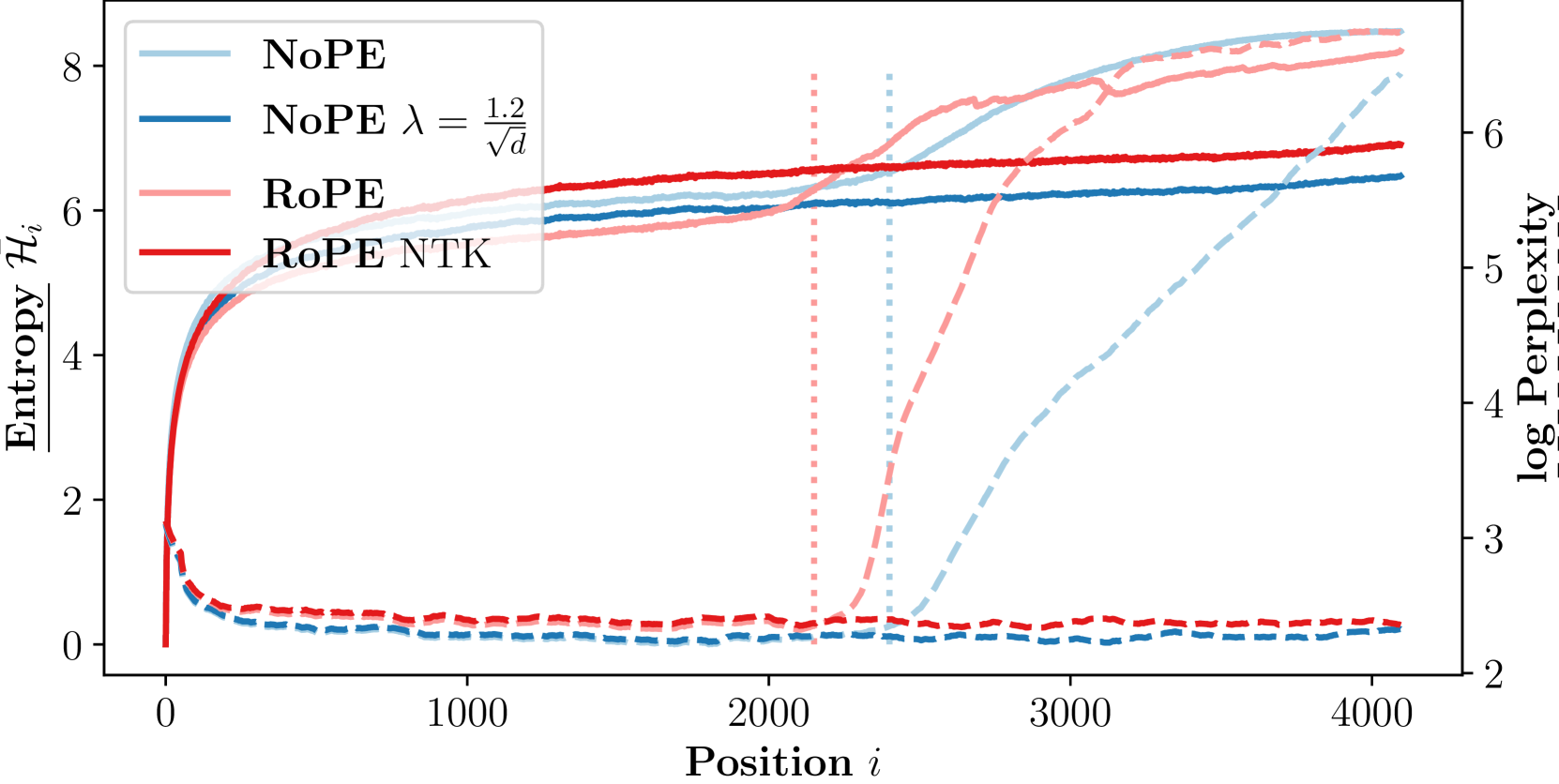
Abstract
Generalizing to longer sentences is important for recent Transformer-based language models. Besides algorithms manipulating explicit position features, the success of Transformers without position encodings (NoPE) provides a new way to overcome the challenge. In this paper, we study the length generalization property of NoPE. We find that although NoPE can extend to longer sequences than the commonly used explicit position encodings, it still has a limited context length. We identify a connection between the failure of NoPE's generalization and the distraction of attention distributions. We propose a parameter-efficient tuning for searching attention heads' best temperature hyper-parameters, which substantially expands NoPE's context size. Experiments on long sequence language modeling, the synthetic passkey retrieval task and real-world long context tasks show that NoPE can achieve competitive performances with state-of-the-art length generalization algorithms. The source code is publicly accessible
Create account to get full access
Overview
- This paper investigates the ability of Causal Transformer models to generalize to input sequences of different lengths, without using traditional positional encoding.
- It proposes a new model called "NoPE" (No Positional Encoding) that can effectively handle variable-length inputs.
- The authors conduct experiments to evaluate NoPE's performance on language modeling tasks and compare it to other Transformer-based models.
Plain English Explanation
Transformer models are a type of artificial intelligence that have become very popular for tasks like language processing and generation. These models work by analyzing the relationships between words in a piece of text, rather than just looking at the words one by one.
One key component of Transformer models is the "positional encoding" - information that tells the model where each word appears in the sequence. This helps the model understand the structure and flow of the text.
However, traditional positional encoding methods can limit a model's ability to handle input sequences of different lengths. This paper explores an approach called "NoPE" (No Positional Encoding) that allows Transformer models to work effectively with variable-length inputs, without relying on explicit positional encoding.
The researchers show that NoPE can match or exceed the performance of other Transformer models on language modeling tasks, while being more flexible and adaptable to inputs of different lengths. This could be particularly useful for applications where the length of the input text is not known ahead of time, such as open-ended conversational AI or long-form question answering.
Technical Explanation
The paper proposes a novel Transformer-based architecture called "NoPE" (No Positional Encoding) that can effectively handle variable-length input sequences without relying on traditional positional encoding.
Instead of using a fixed positional encoding scheme, NoPE learns the positional information directly from the input data through a self-attention mechanism. This allows the model to be more flexible and adaptive to input sequences of different lengths, without introducing the potential biases associated with certain positional encoding methods.
The authors conduct experiments on language modeling tasks, evaluating NoPE's performance on both in-domain and out-of-domain test sets with varying input lengths. They compare NoPE to other Transformer-based models, including those that use traditional positional encoding approaches.
The results show that NoPE can match or outperform the other models on the language modeling tasks, while being more robust to changes in input length. This suggests that the self-attention-based positional learning in NoPE is an effective way to handle variable-length inputs, without compromising the overall performance of the model.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the NoPE model, exploring its performance on a range of language modeling tasks and input lengths. The authors acknowledge several limitations and areas for future research, such as the need to further understand the mechanisms behind NoPE's length generalization capabilities and the potential impact of the self-attention-based positional learning on model interpretability.
One potential concern is the computational complexity of the self-attention mechanism in NoPE, which could make the model less efficient for very long input sequences. The authors mention this as a future research direction, and it would be interesting to see how NoPE's performance and efficiency scales with input length compared to other Transformer variants.
Additionally, the paper focuses on language modeling tasks, and it would be valuable to see how the NoPE approach generalizes to other natural language processing applications, such as machine translation or text summarization, where input length can also be an important factor.
Overall, the paper presents a compelling and well-executed study on a novel Transformer architecture that could have significant implications for the development of more flexible and adaptive natural language processing models.
Conclusion
This paper introduces a novel Transformer-based model called "NoPE" (No Positional Encoding) that can effectively handle variable-length input sequences without relying on traditional positional encoding approaches. The key innovation of NoPE is its use of self-attention-based positional learning, which allows the model to adapt to input lengths dynamically, rather than being constrained by a fixed positional encoding scheme.
The authors' experimental results demonstrate that NoPE can match or exceed the performance of other Transformer-based models on language modeling tasks, while being more robust to changes in input length. This flexibility and adaptability could make NoPE a valuable tool for a wide range of natural language processing applications, particularly those where the length of the input text is not known a priori.
Overall, the NoPE approach represents an exciting step forward in the development of more versatile and robust Transformer models, with the potential to unlock new opportunities for advanced language understanding and generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Exploration of Length Generalization in Transformer-Based Speech Enhancement
Qiquan Zhang, Hongxu Zhu, Xinyuan Qian, Eliathamby Ambikairajah, Haizhou Li
0
0
The use of Transformer architectures has facilitated remarkable progress in speech enhancement. Training Transformers using substantially long speech utterances is often infeasible as self-attention suffers from quadratic complexity. It is a critical and unexplored challenge for a Transformer-based speech enhancement model to learn from short speech utterances and generalize to longer ones. In this paper, we conduct comprehensive experiments to explore the length generalization problem in speech enhancement with Transformer. Our findings first establish that position embedding provides an effective instrument to alleviate the impact of utterance length on Transformer-based speech enhancement. Specifically, we explore four different position embedding schemes to enable length generalization. The results confirm the superiority of relative position embeddings (RPEs) over absolute PE (APEs) in length generalization.
6/18/2024

Length Extrapolation of Transformers: A Survey from the Perspective of Positional Encoding
Liang Zhao, Xiaocheng Feng, Xiachong Feng, Dongliang Xu, Qing Yang, Hongtao Liu, Bing Qin, Ting Liu
0
0
Transformer has taken the field of natural language processing (NLP) by storm since its birth. Further, Large language models (LLMs) built upon it have captured worldwide attention due to its superior abilities. Nevertheless, all Transformer-based models including these powerful LLMs suffer from a preset length limit and can hardly generalize from short training sequences to longer inference ones, namely, they can not perform length extrapolation. Hence, a plethora of methods have been proposed to enhance length extrapolation of Transformer, in which the positional encoding (PE) is recognized as the major factor. In this survey, we present these advances towards length extrapolation in a unified notation from the perspective of PE. Specifically, we first introduce extrapolatable PEs, including absolute and relative PEs. Then, we dive into extrapolation methods based on them, covering position interpolation and randomized position methods. Finally, several challenges and future directions in this area are highlighted. Through this survey, We aim to enable the reader to gain a deep understanding of existing methods and provide stimuli for future research.
4/3/2024
⛏️
CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
Chuanyang Zheng, Yihang Gao, Han Shi, Minbin Huang, Jingyao Li, Jing Xiong, Xiaozhe Ren, Michael Ng, Xin Jiang, Zhenguo Li, Yu Li
0
0
Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be context-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that CAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
5/24/2024

Long-Context Language Modeling with Parallel Context Encoding
Howard Yen, Tianyu Gao, Danqi Chen
0
0
Extending large language models (LLMs) to process longer inputs is crucial for a wide range of applications. However, the substantial computational cost of transformers and limited generalization of positional encoding restrict the size of their context window. We introduce Context Expansion with Parallel Encoding (CEPE), a framework that can be applied to any existing decoder-only LLMs to extend their context window. CEPE employs a small encoder to process long inputs chunk by chunk, enabling the frozen decoder to utilize additional contexts via cross-attention. CEPE is efficient, generalizable, and versatile: trained with 8K-token documents, it extends the context window of LLAMA-2 to 128K tokens, offering 10x the throughput with only 1/6 of the memory. CEPE yields strong performance on language modeling and in-context learning. CEPE also excels in retrieval-augmented applications, while existing long-context models degenerate with retrieved contexts. We further introduce a CEPE variant that can extend the context window of instruction-tuned models using only unlabeled data, and showcase its effectiveness on LLAMA-2-CHAT, leading to a strong instruction-following model that can leverage very long contexts on downstream tasks.
6/13/2024