Length Extrapolation of Transformers: A Survey from the Perspective of Positional Encoding
2312.17044
0
0

Abstract
Transformer has taken the field of natural language processing (NLP) by storm since its birth. Further, Large language models (LLMs) built upon it have captured worldwide attention due to its superior abilities. Nevertheless, all Transformer-based models including these powerful LLMs suffer from a preset length limit and can hardly generalize from short training sequences to longer inference ones, namely, they can not perform length extrapolation. Hence, a plethora of methods have been proposed to enhance length extrapolation of Transformer, in which the positional encoding (PE) is recognized as the major factor. In this survey, we present these advances towards length extrapolation in a unified notation from the perspective of PE. Specifically, we first introduce extrapolatable PEs, including absolute and relative PEs. Then, we dive into extrapolation methods based on them, covering position interpolation and randomized position methods. Finally, several challenges and future directions in this area are highlighted. Through this survey, We aim to enable the reader to gain a deep understanding of existing methods and provide stimuli for future research.
Create account to get full access
Overview
- This paper provides a comprehensive survey of research on length extrapolation in Transformer models, with a focus on position encoding techniques.
- The paper examines how Transformer models, which are widely used in natural language processing, perform when applied to inputs longer than those seen during training.
- It explores various position encoding methods and their impact on a model's ability to handle longer sequences effectively.
Plain English Explanation
Transformer models have become incredibly powerful for tasks like language understanding and generation. These models work by analyzing the relationships between different parts of an input, without relying on the traditional approach of processing the input sequentially.
A key component of Transformers is the position encoding, which tells the model where each piece of the input is located. This allows the model to understand the context and structure of the full input, rather than just processing it one piece at a time.
The challenge is that Transformer models are often trained on relatively short inputs, like sentences or short paragraphs. But in the real world, people sometimes need to use these models on much longer texts, like entire documents or even books.
This paper investigates how well Transformer models can handle these longer inputs, and explores different techniques for position encoding that may help the models extrapolate beyond the lengths they were trained on. The researchers examine the strengths and limitations of various position encoding approaches, providing insights that can guide the development of more robust and flexible Transformer architectures.
Technical Explanation
The paper begins by providing background on the Transformer architecture and the role of position encoding. It explains how Transformer models use self-attention mechanisms to capture relationships between different parts of the input, rather than processing the input sequentially like traditional neural networks.
The paper then delves into the problem of length extrapolation - the ability of Transformer models to handle inputs that are longer than those seen during training. This is an important practical challenge, as Transformer models are often deployed on real-world texts of varying lengths.
The core of the paper explores different position encoding techniques and their impact on length extrapolation performance. The researchers evaluate methods like sinusoidal position encoding, learned position embeddings, and relative position representations. They analyze the strengths and weaknesses of each approach, considering factors like computational efficiency, parameter count, and the model's ability to generalize to longer sequences.
Through extensive experiments on various benchmark tasks, the paper provides insights into the key factors that influence a Transformer model's capacity for length extrapolation. The findings highlight the importance of the position encoding scheme and suggest promising directions for future research and development of more robust Transformer architectures.
Critical Analysis
The paper provides a thorough and well-structured investigation of length extrapolation in Transformer models, considering a range of position encoding techniques. The experimental results offer valuable empirical insights that can guide the design of Transformer models for applications requiring the processing of longer inputs.
One potential limitation of the study is its focus on a relatively narrow set of benchmarks and tasks. While the researchers do explore a variety of sequence lengths and datasets, it would be interesting to see the performance of the studied position encoding methods on a broader range of real-world applications, such as long-form document understanding or multi-document summarization.
Additionally, the paper does not delve deeply into the underlying reasons why certain position encoding approaches are more effective for length extrapolation. Further analysis of the model's internal representations and attention patterns could shed light on the mechanisms by which these methods enable better handling of longer inputs.
Despite these minor caveats, the paper makes a valuable contribution to the understanding of Transformer models and their limitations. The insights provided can inform the development of more robust and adaptable Transformer architectures, with potential applications in a wide range of natural language processing tasks.
Conclusion
This comprehensive survey on length extrapolation in Transformer models offers important insights for the continued advancement of these powerful deep learning architectures. By exploring the role of position encoding techniques, the paper sheds light on a crucial component that can significantly impact a model's ability to handle inputs beyond the lengths encountered during training.
The findings presented in this work can guide researchers and practitioners in designing more flexible and versatile Transformer models, unlocking their potential for a broader range of real-world applications that involve processing longer, more complex textual inputs. As the use of Transformer models continues to grow, this research represents an important step towards building more robust and adaptable natural language processing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Exploration of Length Generalization in Transformer-Based Speech Enhancement
Qiquan Zhang, Hongxu Zhu, Xinyuan Qian, Eliathamby Ambikairajah, Haizhou Li
0
0
The use of Transformer architectures has facilitated remarkable progress in speech enhancement. Training Transformers using substantially long speech utterances is often infeasible as self-attention suffers from quadratic complexity. It is a critical and unexplored challenge for a Transformer-based speech enhancement model to learn from short speech utterances and generalize to longer ones. In this paper, we conduct comprehensive experiments to explore the length generalization problem in speech enhancement with Transformer. Our findings first establish that position embedding provides an effective instrument to alleviate the impact of utterance length on Transformer-based speech enhancement. Specifically, we explore four different position embedding schemes to enable length generalization. The results confirm the superiority of relative position embeddings (RPEs) over absolute PE (APEs) in length generalization.
6/18/2024
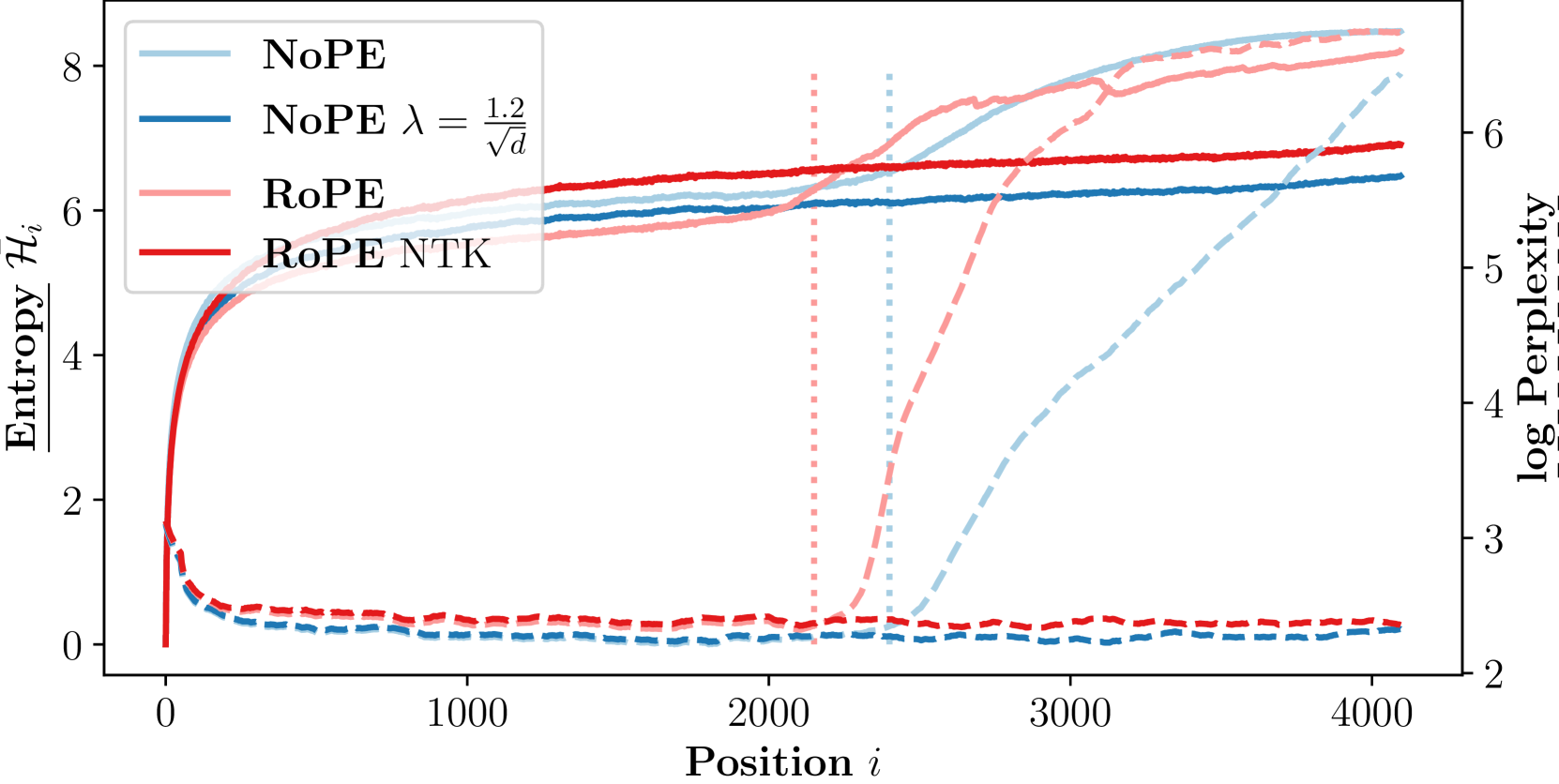
Length Generalization of Causal Transformers without Position Encoding
Jie Wang, Tao Ji, Yuanbin Wu, Hang Yan, Tao Gui, Qi Zhang, Xuanjing Huang, Xiaoling Wang
0
0
Generalizing to longer sentences is important for recent Transformer-based language models. Besides algorithms manipulating explicit position features, the success of Transformers without position encodings (NoPE) provides a new way to overcome the challenge. In this paper, we study the length generalization property of NoPE. We find that although NoPE can extend to longer sequences than the commonly used explicit position encodings, it still has a limited context length. We identify a connection between the failure of NoPE's generalization and the distraction of attention distributions. We propose a parameter-efficient tuning for searching attention heads' best temperature hyper-parameters, which substantially expands NoPE's context size. Experiments on long sequence language modeling, the synthetic passkey retrieval task and real-world long context tasks show that NoPE can achieve competitive performances with state-of-the-art length generalization algorithms. The source code is publicly accessible
5/29/2024
⛏️
CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
Chuanyang Zheng, Yihang Gao, Han Shi, Minbin Huang, Jingyao Li, Jing Xiong, Xiaozhe Ren, Michael Ng, Xin Jiang, Zhenguo Li, Yu Li
0
0
Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be context-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that CAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
5/24/2024
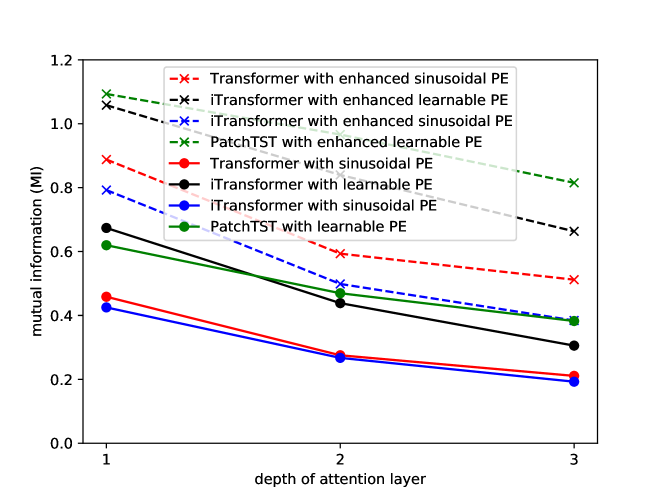
Intriguing Properties of Positional Encoding in Time Series Forecasting
Jianqi Zhang, Jingyao Wang, Wenwen Qiang, Fanjiang Xu, Changwen Zheng, Fuchun Sun, Hui Xiong
0
0
Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
4/17/2024