Explore the Hallucination on Low-level Perception for MLLMs

0
Sign in to get full access
Overview
- Explores hallucination in low-level perception for multi-modal large language models (MLLMs)
- Proposes a benchmark to assess hallucination in low-level vision tasks
- Investigates the causes and characteristics of hallucination in MLLMs
Plain English Explanation
This research paper explores the phenomenon of "hallucination" in multi-modal large language models (MLLMs) - models that can process and generate both text and visual information. Hallucination refers to the model's tendency to generate incorrect or imaginary visual information that does not accurately reflect the real world.
The researchers develop a benchmark to assess how well these MLLMs can perform on low-level vision tasks, such as detecting edges, textures, and colors. By testing the models on these basic visual perception abilities, they can better understand the nature and causes of hallucination in these systems.
The key idea is that if an MLLM struggles with these fundamental visual processing tasks, it is more likely to hallucinate or generate unreliable visual outputs when faced with more complex real-world scenarios. Understanding the roots of hallucination in MLLMs is an important step in improving their reliability and trustworthiness.
Technical Explanation
The researchers propose a new benchmark called "LLSA" (Low-Level Spatial Awareness) to assess hallucination in MLLMs. LLSA consists of a suite of low-level vision tasks, such as edge detection, texture recognition, and color classification. By evaluating model performance on these basic perceptual abilities, the researchers can gain insights into the causes and characteristics of hallucination.
The paper presents experiments where several state-of-the-art MLLMs, including DALL-E 2 and Flamingo, are tested on the LLSA benchmark. The results show that these models struggle with many of the low-level vision tasks, suggesting that their hallucination issues may stem from fundamental deficiencies in visual perception.
Further analysis reveals that the models' hallucination tendencies are influenced by factors such as training data, model architecture, and task complexity. For example, models trained on more diverse visual data tend to exhibit less hallucination, while those with limited low-level visual understanding are more prone to generating unreliable outputs.
Critical Analysis
The research provides valuable insights into the nature of hallucination in MLLMs, but it also highlights several areas for further investigation. While the LLSA benchmark offers a structured way to assess low-level visual perception, the researchers acknowledge that it may not capture the full complexity of real-world visual processing.
Additionally, the paper does not delve deeply into the potential implications of hallucination in practical applications, such as how it might impact the reliability of these models in safety-critical domains. Exploring the downstream effects of hallucination and developing strategies to mitigate it are important areas for future research.
The authors also note that the underlying causes of hallucination are not yet fully understood, and further work is needed to uncover the specific architectural and training-related factors that contribute to this phenomenon.
Conclusion
This research paper makes an important contribution to the understanding of hallucination in multi-modal large language models. By developing a benchmark focused on low-level visual perception, the authors have shed light on the roots of this issue and highlighted the need for more robust and reliable visual processing capabilities in these powerful AI systems.
As MLLMs continue to be deployed in a wide range of applications, addressing hallucination will be crucial to ensuring their trustworthiness and safe deployment. The insights and methods presented in this paper provide a valuable starting point for further research and development in this crucial area of AI safety and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Explore the Hallucination on Low-level Perception for MLLMs
Yinan Sun, Zicheng Zhang, Haoning Wu, Xiaohong Liu, Weisi Lin, Guangtao Zhai, Xiongkuo Min
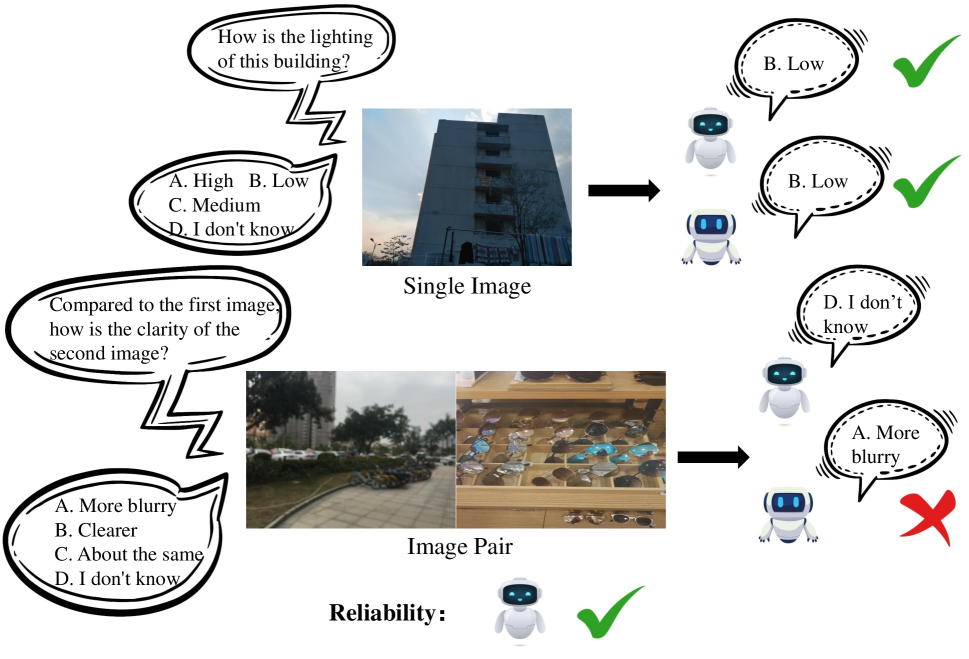
The rapid development of Multi-modality Large Language Models (MLLMs) has significantly influenced various aspects of industry and daily life, showcasing impressive capabilities in visual perception and understanding. However, these models also exhibit hallucinations, which limit their reliability as AI systems, especially in tasks involving low-level visual perception and understanding. We believe that hallucinations stem from a lack of explicit self-awareness in these models, which directly impacts their overall performance. In this paper, we aim to define and evaluate the self-awareness of MLLMs in low-level visual perception and understanding tasks. To this end, we present QL-Bench, a benchmark settings to simulate human responses to low-level vision, investigating self-awareness in low-level visual perception through visual question answering related to low-level attributes such as clarity and lighting. Specifically, we construct the LLSAVisionQA dataset, comprising 2,990 single images and 1,999 image pairs, each accompanied by an open-ended question about its low-level features. Through the evaluation of 15 MLLMs, we demonstrate that while some models exhibit robust low-level visual capabilities, their self-awareness remains relatively underdeveloped. Notably, for the same model, simpler questions are often answered more accurately than complex ones. However, self-awareness appears to improve when addressing more challenging questions. We hope that our benchmark will motivate further research, particularly focused on enhancing the self-awareness of MLLMs in tasks involving low-level visual perception and understanding.
Read more9/17/2024

0
Look Within, Why LLMs Hallucinate: A Causal Perspective
He Li, Haoang Chi, Mingyu Liu, Wenjing Yang
The emergence of large language models (LLMs) is a milestone in generative artificial intelligence, achieving significant success in text comprehension and generation tasks. Despite the tremendous success of LLMs in many downstream tasks, they suffer from severe hallucination problems, posing significant challenges to the practical applications of LLMs. Most of the works about LLMs' hallucinations focus on data quality. Self-attention is a core module in transformer-based LLMs, while its potential relationship with LLMs' hallucination has been hardly investigated. To fill this gap, we study this problem from a causal perspective. We propose a method to intervene in LLMs' self-attention layers and maintain their structures and sizes intact. Specifically, we disable different self-attention layers in several popular open-source LLMs and then compare their degrees of hallucination with the original ones. We evaluate the intervened LLMs on hallucination assessment benchmarks and conclude that disabling some specific self-attention layers in the front or tail of the LLMs can alleviate hallucination issues. The study paves a new way for understanding and mitigating LLMs' hallucinations.
Read more7/16/2024

0
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Read more5/7/2024
💬
0
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
Read more4/30/2024