A Survey on Hallucination in Large Vision-Language Models
2402.00253
0
0

Abstract
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Create account to get full access
Overview
- This paper provides a comprehensive survey on the issue of hallucination in large vision-language models (LVLMs), which are AI systems that can process and generate text and images together.
- Hallucination refers to the tendency of these models to produce false or nonsensical information that appears plausible but is not grounded in reality.
- The paper examines the causes, detection, and mitigation of hallucination in LVLMs, and discusses the broader implications for the responsible development and deployment of these powerful AI systems.
Plain English Explanation
Large vision-language models (LVLMs) are a type of artificial intelligence that can understand and generate both text and images. These models have shown impressive capabilities, but they also have a concerning tendency to produce information that seems real but is actually made up or incorrect. This phenomenon is known as "hallucination."
The survey paper explores the problem of hallucination in LVLMs in depth. It examines what causes these models to hallucinate, how we can detect when they are producing false information, and techniques that can be used to mitigate or prevent hallucination.
Understanding and addressing hallucination is crucial as LVLMs become more widely used, as these models could have significant real-world impact if they start generating inaccurate or misleading content. The paper highlights the importance of developing LVLMs that are reliable, truthful, and aligned with human values.
Technical Explanation
The paper begins by providing an overview of large vision-language models (LVLMs), which are AI systems trained on vast amounts of text and image data to perform tasks such as image captioning, visual question answering, and multimodal generation. These models have achieved impressive results, but they also exhibit a concerning tendency to hallucinate - producing responses that appear plausible but are factually incorrect or nonsensical.
The paper then delves into the causes of hallucination in LVLMs. It explains how these models can struggle with out-of-distribution inputs, lack of grounding in the real world, and biases in their training data, all of which can lead to hallucinated outputs. The authors also discuss how the underlying architecture and training procedures of LVLMs can contribute to hallucination.
Next, the paper explores techniques for detecting hallucination in LVLM outputs. This includes approaches like anomaly detection, consistency checking, and plausibility scoring. The authors also highlight the need for comprehensive benchmarks to assess and compare the hallucination behaviors of different LVLM models.
Finally, the paper discusses various mitigation strategies for hallucination, such as improved model architectures, data curation, and calibration techniques. The authors emphasize the importance of developing LVLMs that are reliable, truthful, and aligned with human values as these models become more widely deployed.
Critical Analysis
The survey paper provides a thorough and well-researched overview of the hallucination problem in large vision-language models. The authors do an admirable job of covering the key technical details, while also highlighting the broader societal implications of this issue.
One potential limitation of the paper is that it primarily focuses on the current state of the research, without delving too deeply into potential future directions or open challenges. For example, the authors mention the need for comprehensive benchmarks to measure hallucination, but do not discuss the specific challenges involved in developing such benchmarks.
Additionally, while the paper covers a range of detection and mitigation techniques, it does not provide a comparative analysis of their relative strengths and weaknesses. This could be a useful addition for readers looking to better understand the trade-offs between different approaches.
Overall, the paper serves as an excellent starting point for understanding the hallucination problem in LVLMs. However, readers may benefit from supplemental resources that explore the topic in greater depth or provide more critical analysis.
Conclusion
The survey paper highlights a critical issue facing the development of large vision-language models (LVLMs) - the tendency of these AI systems to hallucinate, or produce false or nonsensical information that appears plausible.
By examining the causes, detection, and mitigation of hallucination, the authors emphasize the importance of creating LVLMs that are reliable, truthful, and aligned with human values. As these powerful AI models become more widely deployed, addressing the hallucination problem will be crucial for ensuring their responsible and beneficial use in real-world applications.
The insights and techniques discussed in this paper provide a solid foundation for continued research and development in this area, with the ultimate goal of realizing the full potential of LVLMs while mitigating the risks posed by their tendency to hallucinate.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024
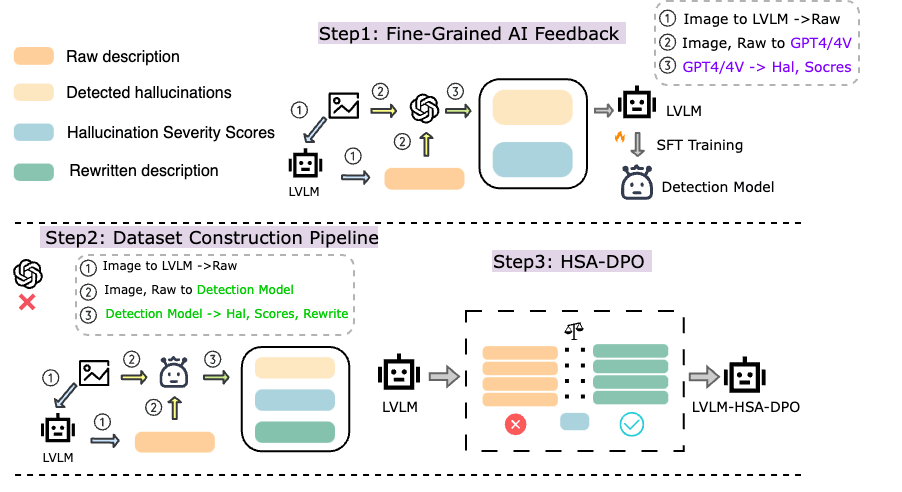
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
0
0
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
4/23/2024

Visual Hallucinations of Multi-modal Large Language Models
Wen Huang, Hongbin Liu, Minxin Guo, Neil Zhenqiang Gong
0
0
Visual hallucination (VH) means that a multi-modal LLM (MLLM) imagines incorrect details about an image in visual question answering. Existing studies find VH instances only in existing image datasets, which results in biased understanding of MLLMs' performance under VH due to limited diversity of such VH instances. In this work, we propose a tool called VHTest to generate a diverse set of VH instances. Specifically, VHTest finds some initial VH instances in existing image datasets (e.g., COCO), generates a text description for each VH mode, and uses a text-to-image generative model (e.g., DALL-E-3) to generate VH images based on the text descriptions. We collect a benchmark dataset with 1,200 VH instances in 8 VH modes using VHTest. We find that existing MLLMs such as GPT-4V, LLaVA-1.5, and MiniGPT-v2 hallucinate for a large fraction of the instances in our benchmark. Moreover, we find that fine-tuning an MLLM using our benchmark dataset reduces its likelihood to hallucinate without sacrificing its performance on other benchmarks. Our benchmarks are publicly available: https://github.com/wenhuang2000/VHTest.
6/18/2024

Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization
Beitao Chen, Xinyu Lyu, Lianli Gao, Jingkuan Song, Heng Tao Shen
0
0
Although Large Visual Language Models (LVLMs) have demonstrated exceptional abilities in understanding multimodal data, they invariably suffer from hallucinations, leading to a disconnect between the generated text and the corresponding images. Almost all current visual contrastive decoding methods attempt to mitigate these hallucinations by introducing visual uncertainty information that appropriately widens the contrastive logits gap between hallucinatory and targeted ones. However, due to uncontrollable nature of the global visual uncertainty, they struggle to precisely induce the hallucinatory tokens, which severely limits their effectiveness in mitigating hallucinations and may even lead to the generation of undesired hallucinations. To tackle this issue, we conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO). This strategy seeks to amplify the contrast between hallucinatory and targeted tokens relying on a fine-tuned theoretical preference model (i.e., Contrary Bradley-Terry Model), thereby facilitating efficient contrast decoding to alleviate hallucinations in LVLMs. Extensive experimental research demonstrates that our HIO strategy can effectively reduce hallucinations in LVLMs, outperforming state-of-the-art methods across various benchmarks.
5/27/2024