Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection

0

Sign in to get full access
Overview
- The paper explores the fusion of LiDAR and camera data for improved 3D object detection.
- It proposes a dynamic adjustment mechanism to optimize the alignment between LiDAR and camera features.
- Experiments show the approach outperforms state-of-the-art multi-modal 3D detection methods.
Plain English Explanation
The paper focuses on combining data from two common sensors used in autonomous vehicles - a LiDAR laser scanner and a camera. LiDAR can accurately measure 3D distances, while cameras provide rich visual information. By fusing these two data sources, the researchers aim to improve the performance of 3D object detection, which is crucial for autonomous navigation.
The key innovation is a "dynamic adjustment" mechanism that continuously optimizes the alignment between the LiDAR and camera features during the detection process. This helps compensate for any initial misalignment between the two sensor modalities, which can occur due to factors like sensor calibration errors or changing environmental conditions.
Technical Explanation
The paper proposes a multi-modal 3D object detection framework that fuses LiDAR and camera data. The approach starts by extracting features from the LiDAR point cloud and camera image using separate neural network backbones.
To address the challenge of imperfect sensor alignment, the framework includes a dynamic adjustment module. This module learns to predict spatial transformations that can continuously refine the alignment between the LiDAR and camera features during inference. By dynamically adjusting the feature alignment, the model can better leverage the complementary information from both sensors.
The fused features are then used to predict 3D bounding boxes and other object attributes. Experiments on benchmark datasets show that this LiDAR-camera fusion approach outperforms state-of-the-art multi-modal 3D object detection methods, particularly in challenging scenarios with partial occlusions or domain shifts.
Critical Analysis
The paper provides a novel solution to the problem of imperfect sensor alignment in multi-modal 3D object detection. The dynamic adjustment mechanism is a clever way to address this challenge, and the experimental results demonstrate its effectiveness.
However, the paper does not extensively explore the limitations of the approach. For example, it is unclear how the method would perform in situations with severe occlusions or drastic changes in lighting/weather conditions, which could still hamper the ability of the sensors to provide complementary information. Additionally, the computational cost of the dynamic adjustment module is not discussed, which could be an important practical consideration.
Further research could investigate more robust fusion strategies that can handle a wider range of real-world scenarios, as well as optimizations to improve the efficiency of the overall system. Exploring the use of more advanced sensor fusion techniques, such as contrastive alignment, could also be a promising direction.
Conclusion
This paper presents a novel approach to fusing LiDAR and camera data for improved 3D object detection. The key innovation is a dynamic adjustment mechanism that continuously refines the alignment between the two sensor modalities, helping to overcome challenges posed by imperfect sensor calibration or changing environmental conditions.
The experimental results demonstrate the effectiveness of this approach, with significant performance gains over state-of-the-art multi-modal detection methods. While the paper does not fully address the limitations of the technique, it represents an important step forward in leveraging the complementary strengths of LiDAR and cameras for robust 3D perception in autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection
Yiran Yang, Xu Gao, Tong Wang, Xin Hao, Yifeng Shi, Xiao Tan, Xiaoqing Ye, Jingdong Wang
Camera and LiDAR serve as informative sensors for accurate and robust autonomous driving systems. However, these sensors often exhibit heterogeneous natures, resulting in distributional modality gaps that present significant challenges for fusion. To address this, a robust fusion technique is crucial, particularly for enhancing 3D object detection. In this paper, we introduce a dynamic adjustment technology aimed at aligning modal distributions and learning effective modality representations to enhance the fusion process. Specifically, we propose a triphase domain aligning module. This module adjusts the feature distributions from both the camera and LiDAR, bringing them closer to the ground truth domain and minimizing differences. Additionally, we explore improved representation acquisition methods for dynamic fusion, which includes modal interaction and specialty enhancement. Finally, an adaptive learning technique that merges the semantics and geometry information for dynamical instance optimization. Extensive experiments in the nuScenes dataset present competitive performance with state-of-the-art approaches. Our code will be released in the future.
Read more7/23/2024

0
BiCo-Fusion: Bidirectional Complementary LiDAR-Camera Fusion for Semantic- and Spatial-Aware 3D Object Detection
Yang Song, Lin Wang
3D object detection is an important task that has been widely applied in autonomous driving. Recently, fusing multi-modal inputs, i.e., LiDAR and camera data, to perform this task has become a new trend. Existing methods, however, either ignore the sparsity of Lidar features or fail to preserve the original spatial structure of LiDAR and the semantic density of camera features simultaneously due to the modality gap. To address issues, this letter proposes a novel bidirectional complementary Lidar-camera fusion framework, called BiCo-Fusion that can achieve robust semantic- and spatial-aware 3D object detection. The key insight is to mutually fuse the multi-modal features to enhance the semantics of LiDAR features and the spatial awareness of the camera features and adaptatively select features from both modalities to build a unified 3D representation. Specifically, we introduce Pre-Fusion consisting of a Voxel Enhancement Module (VEM) to enhance the semantics of voxel features from 2D camera features and Image Enhancement Module (IEM) to enhance the spatial characteristics of camera features from 3D voxel features. Both VEM and IEM are bidirectionally updated to effectively reduce the modality gap. We then introduce Unified Fusion to adaptively weight to select features from the enchanted Lidar and camera features to build a unified 3D representation. Extensive experiments demonstrate the superiority of our BiCo-Fusion against the prior arts. Project page: https://t-ys.github.io/BiCo-Fusion/.
Read more6/28/2024

0
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, Ziwei Liu
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
Read more5/9/2024
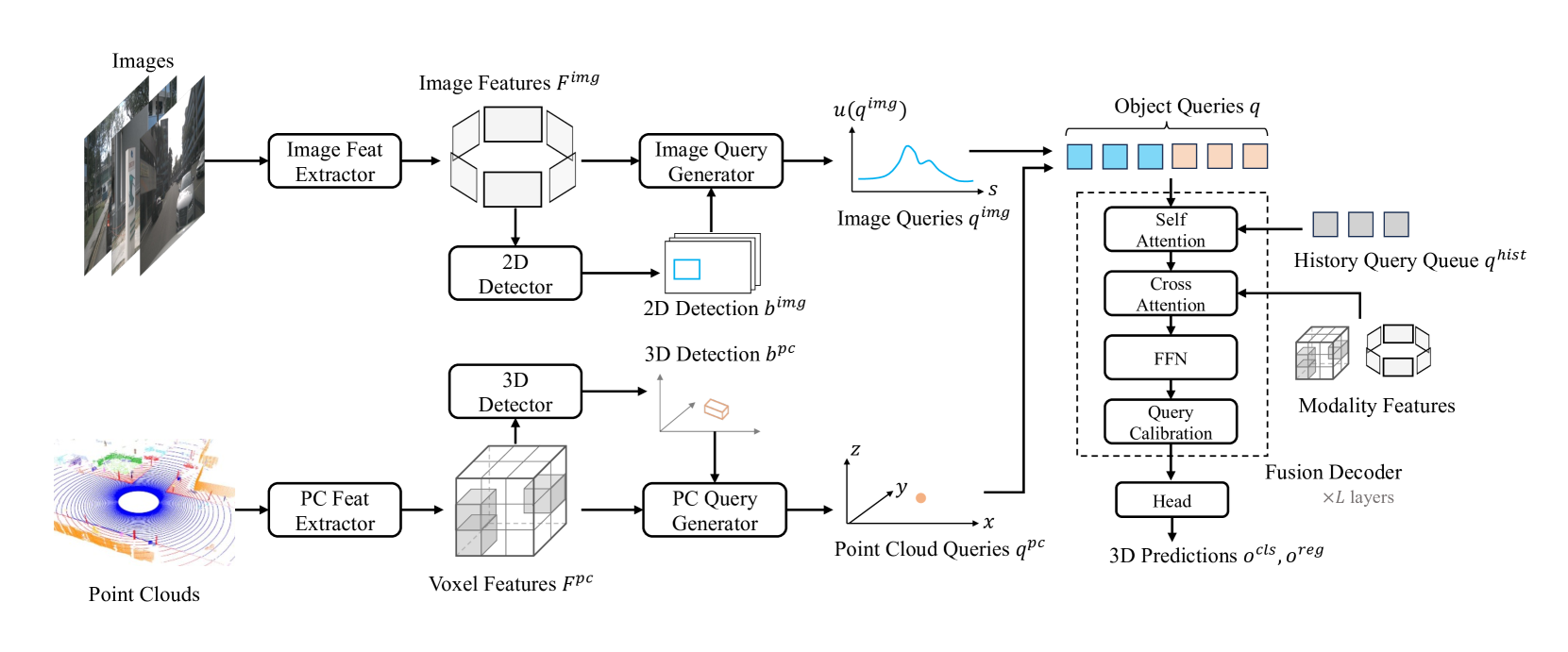
0
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Read more8/13/2024