MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection

0
Sign in to get full access
Overview
- MV2DFusion is a multi-modal 3D object detection system that leverages modality-specific object semantics.
- It combines information from LiDAR and camera sensors to improve 3D detection performance.
- The key innovation is using modality-specific object semantic features to guide the fusion process.
Plain English Explanation
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection is a research paper that describes a new approach to 3D object detection for autonomous vehicles. The core idea is to combine information from two different sensor types - LiDAR (laser-based) and cameras - in a way that takes advantage of the unique properties of each.
LiDAR sensors provide very accurate 3D spatial information, but lack the rich semantic understanding that cameras can provide about the objects in a scene. Cameras, on the other hand, excel at identifying and classifying objects, but struggle to accurately localize them in 3D space.
By jointly leveraging the modality-specific strengths of these sensors, MV2DFusion is able to produce 3D object detections that are more accurate and robust than what either sensor could achieve alone. The system learns to fuse the complementary information from LiDAR and cameras in an intelligent way, using the semantic knowledge from the camera to guide and refine the 3D localization from the LiDAR.
This combined 3D detection approach could be very valuable for autonomous vehicles, which need to perceive the world around them with high accuracy in order to navigate safely. The authors show that MV2DFusion outperforms other state-of-the-art multi-modal 3D detection methods, demonstrating the power of this modality-specific fusion strategy.
Technical Explanation
MV2DFusion is built on top of a baseline 3D object detection model that uses only LiDAR data. It then adds a camera-based branch that extracts semantic object features. These features are fused with the LiDAR features to produce the final 3D object detections.
The key innovation is the way this fusion is performed. Rather than simply concatenating or averaging the features from the two modalities, MV2DFusion learns to selectively attend to and combine the most relevant semantic and spatial cues. This is done through a modality-specific attention mechanism that adaptively weights the contributions of the LiDAR and camera branches based on the properties of each object.
For example, the system may rely more heavily on the LiDAR features for large, rigid objects like cars, but favor the camera features for smaller, more diverse objects like pedestrians and cyclists. This modality-specific fusion strategy allows MV2DFusion to better leverage the complementary strengths of the sensors.
The authors evaluate MV2DFusion on standard 3D object detection benchmarks and show it outperforms other state-of-the-art multi-modal approaches. They also provide detailed ablation studies to understand the importance of the modality-specific fusion mechanism and other key design choices.
Critical Analysis
The MV2DFusion paper presents a well-designed and thorough study of multi-modal 3D object detection. The authors carefully justify their design decisions and provide extensive experimental validation of the approach.
One potential limitation is that the system still relies on the availability of both LiDAR and camera sensors. In some real-world scenarios, one or the other sensor may be unavailable or unreliable, so a truly robust system would need to handle such situations. The authors mention this as an area for future work.
Additionally, the paper focuses mainly on evaluating MV2DFusion on standard benchmarks, but does not provide much insight into how the system would perform in truly complex, real-world environments. Further testing in diverse, challenging driving scenarios would help better understand the practical limitations and failure modes of the approach.
Overall, though, the MV2DFusion paper presents a compelling multi-modal 3D detection system that demonstrates the value of leveraging modality-specific object semantics. The authors have made a valuable contribution to the field of autonomous vehicle perception.
Conclusion
MV2DFusion is a novel multi-modal 3D object detection system that combines information from LiDAR and camera sensors in an intelligent way. By using modality-specific object semantics to guide the fusion process, it is able to outperform other state-of-the-art approaches on standard benchmarks.
This work highlights the importance of developing perception systems that can effectively leverage the complementary strengths of different sensor modalities. As autonomous vehicles continue to advance, techniques like MV2DFusion will be crucial for building reliable and robust 3D object detection capabilities.
While the paper demonstrates promising results, there are still areas for further research, such as handling sensor failures and testing in more diverse real-world environments. Overall, though, MV2DFusion represents an important step forward in multi-modal 3D perception for autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
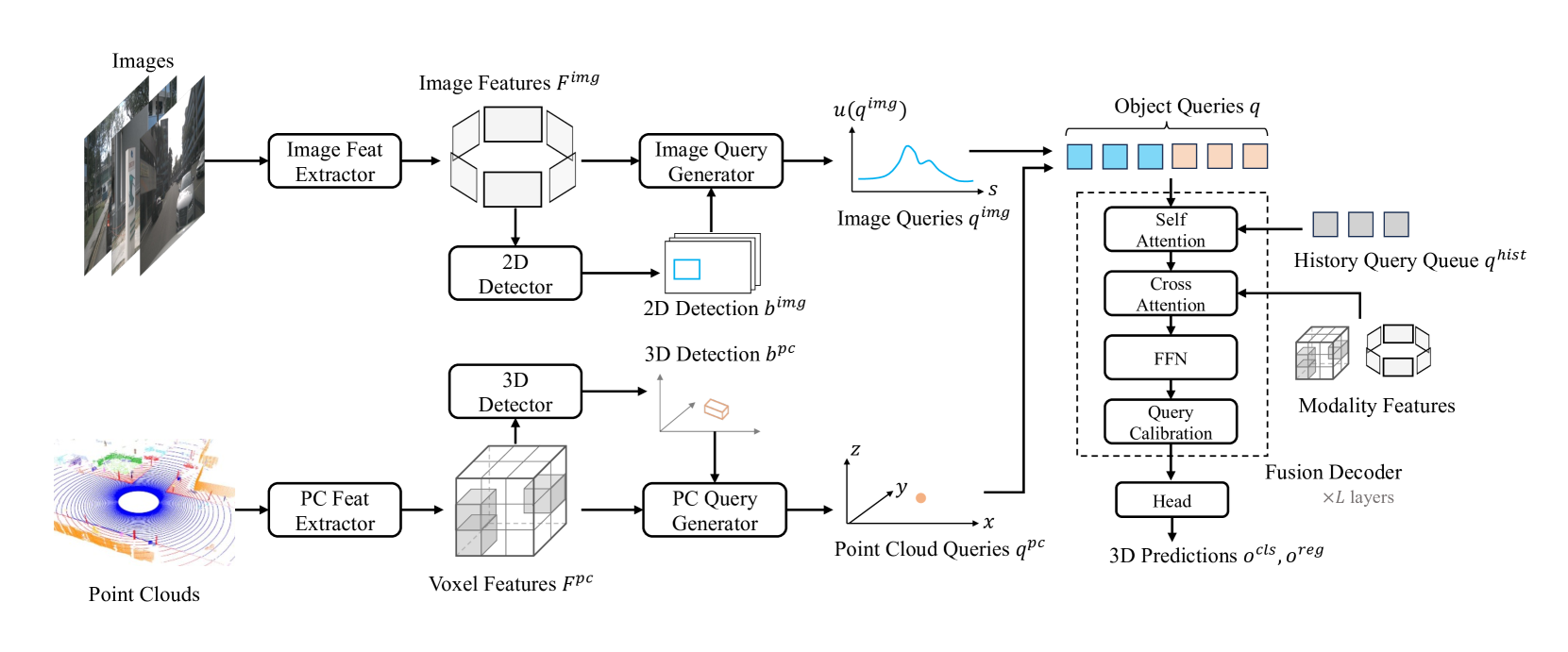
The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Read more8/13/2024
🔎
0
RoboFusion: Towards Robust Multi-Modal 3D Object Detection via SAM
Ziying Song, Guoxing Zhang, Lin Liu, Lei Yang, Shaoqing Xu, Caiyan Jia, Feiyang Jia, Li Wang
Multi-modal 3D object detectors are dedicated to exploring secure and reliable perception systems for autonomous driving (AD).Although achieving state-of-the-art (SOTA) performance on clean benchmark datasets, they tend to overlook the complexity and harsh conditions of real-world environments. With the emergence of visual foundation models (VFMs), opportunities and challenges are presented for improving the robustness and generalization of multi-modal 3D object detection in AD. Therefore, we propose RoboFusion, a robust framework that leverages VFMs like SAM to tackle out-of-distribution (OOD) noise scenarios. We first adapt the original SAM for AD scenarios named SAM-AD. To align SAM or SAM-AD with multi-modal methods, we then introduce AD-FPN for upsampling the image features extracted by SAM. We employ wavelet decomposition to denoise the depth-guided images for further noise reduction and weather interference. At last, we employ self-attention mechanisms to adaptively reweight the fused features, enhancing informative features while suppressing excess noise. In summary, RoboFusion significantly reduces noise by leveraging the generalization and robustness of VFMs, thereby enhancing the resilience of multi-modal 3D object detection. Consequently, RoboFusion achieves SOTA performance in noisy scenarios, as demonstrated by the KITTI-C and nuScenes-C benchmarks. Code is available at https://github.com/adept-thu/RoboFusion.
Read more4/24/2024

0
vFusedSeg3D: 3rd Place Solution for 2024 Waymo Open Dataset Challenge in Semantic Segmentation
Osama Amjad, Ammad Nadeem
In this technical study, we introduce VFusedSeg3D, an innovative multi-modal fusion system created by the VisionRD team that combines camera and LiDAR data to significantly enhance the accuracy of 3D perception. VFusedSeg3D uses the rich semantic content of the camera pictures and the accurate depth sensing of LiDAR to generate a strong and comprehensive environmental understanding, addressing the constraints inherent in each modality. Through a carefully thought-out network architecture that aligns and merges these information at different stages, our novel feature fusion technique combines geometric features from LiDAR point clouds with semantic features from camera images. With the use of multi-modality techniques, performance has significantly improved, yielding a state-of-the-art mIoU of 72.46% on the validation set as opposed to the prior 70.51%.VFusedSeg3D sets a new benchmark in 3D segmentation accuracy. making it an ideal solution for applications requiring precise environmental perception.
Read more8/29/2024
🔎
0
Fully Sparse Fusion for 3D Object Detection
Yingyan Li, Lue Fan, Yang Liu, Zehao Huang, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang
Currently prevalent multimodal 3D detection methods are built upon LiDAR-based detectors that usually use dense Bird's-Eye-View (BEV) feature maps. However, the cost of such BEV feature maps is quadratic to the detection range, making it not suitable for long-range detection. Fully sparse architecture is gaining attention as they are highly efficient in long-range perception. In this paper, we study how to effectively leverage image modality in the emerging fully sparse architecture. Particularly, utilizing instance queries, our framework integrates the well-studied 2D instance segmentation into the LiDAR side, which is parallel to the 3D instance segmentation part in the fully sparse detector. This design achieves a uniform query-based fusion framework in both the 2D and 3D sides while maintaining the fully sparse characteristic. Extensive experiments showcase state-of-the-art results on the widely used nuScenes dataset and the long-range Argoverse 2 dataset. Notably, the inference speed of the proposed method under the long-range LiDAR perception setting is 2.7 $times$ faster than that of other state-of-the-art multimodal 3D detection methods. Code will be released at url{https://github.com/BraveGroup/FullySparseFusion}.
Read more4/30/2024