Exploring the Adversarial Robustness of CLIP for AI-generated Image Detection

0

Sign in to get full access
Overview
- This paper explores the adversarial robustness of CLIP, a popular AI-based image detection model, in the context of detecting AI-generated images.
- The researchers investigate how CLIP's performance holds up against adversarial attacks aimed at fooling the model.
- They assess CLIP's ability to accurately classify AI-generated images, even when those images have been modified to evade detection.
Plain English Explanation
CLIP is a powerful AI model that can identify the contents of images. Researchers wanted to see how well CLIP could detect images that were created by other AI systems, rather than real photographs. This is an important task, as AI-generated "deepfake" images can be used to spread misinformation or create synthetic media.
The researchers tried to trick CLIP by making small changes to AI-generated images, to see if the model could still correctly identify them as artificial. They found that CLIP was generally quite good at detecting these AI-generated images, even when they had been slightly altered. This suggests that CLIP is a robust tool for spotting AI-generated content, which is important for maintaining trust and authenticity online.
However, the researchers also found that there were some types of adversarial attacks that could sometimes fool CLIP into misclassifying AI-generated images. This means that there is still room for improvement in making these detection models fully secure against attempts to bypass them.
Overall, the study provides valuable insights into the strengths and limitations of CLIP when it comes to identifying AI-generated imagery. This information can help guide the development of even more reliable and secure systems for combating the spread of synthetic media.
Technical Explanation
The paper examines the adversarial robustness of CLIP, a prominent vision-language model, in the context of detecting AI-generated images. The researchers evaluate CLIP's performance under various adversarial attacks aimed at fooling the model's classification of AI-generated content.
They first establish a benchmark dataset of real and AI-generated images, using state-of-the-art generative models like StyleGAN2 and Stable Diffusion. They then apply different attack strategies, such as gradient-based optimization and image transformation, to generate adversarial examples that can mislead CLIP's AI-generated image detection.
The results show that CLIP exhibits strong baseline performance in identifying AI-generated images. However, the model is still vulnerable to certain adversarial attacks, particularly those based on optimization-driven perturbations. The researchers find that while CLIP is generally robust to common image transformations, it can be more easily fooled by carefully crafted, iterative perturbations.
The paper also explores potential mitigation strategies, including adversarial training and ensemble approaches, to enhance CLIP's robustness against these adversarial attacks. The insights gained from this study contribute to the ongoing efforts to develop more reliable and secure AI-generated content detection systems.
Critical Analysis
The paper provides a thorough and rigorous examination of CLIP's adversarial robustness in the context of AI-generated image detection. The researchers have carefully designed their experiments and used state-of-the-art attack methods to stress-test the model's capabilities.
One potential limitation is that the study focuses solely on CLIP and does not compare its performance to other AI-generated image detection models. It would be valuable to see how CLIP's robustness compares to other approaches, as this could help identify the relative strengths and weaknesses of different detection strategies.
Additionally, while the paper discusses potential mitigation strategies, it does not provide a comprehensive evaluation of their effectiveness. Further research into the most effective techniques for improving CLIP's adversarial robustness would be a valuable addition to this line of work.
Overall, the paper makes a significant contribution to the understanding of CLIP's capabilities and limitations in the critical task of AI-generated image detection. The findings highlight the need for continued research and development to create more secure and reliable systems for combating the spread of synthetic media.
Conclusion
This paper presents a detailed exploration of the adversarial robustness of CLIP, a prominent AI-based image detection model, in the context of identifying AI-generated content. The researchers demonstrate that CLIP exhibits strong baseline performance in detecting AI-generated images, but is still vulnerable to certain adversarial attacks aimed at fooling the model.
The insights gained from this study are crucial for the ongoing efforts to develop more reliable and secure systems for combating the spread of synthetic media. By understanding the strengths and limitations of CLIP's adversarial robustness, researchers can work towards creating even more robust and effective AI-generated image detection tools. This ultimately contributes to the broader goal of maintaining trust and authenticity in the digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring the Adversarial Robustness of CLIP for AI-generated Image Detection
Vincenzo De Rosa, Fabrizio Guillaro, Giovanni Poggi, Davide Cozzolino, Luisa Verdoliva
In recent years, many forensic detectors have been proposed to detect AI-generated images and prevent their use for malicious purposes. Convolutional neural networks (CNNs) have long been the dominant architecture in this field and have been the subject of intense study. However, recently proposed Transformer-based detectors have been shown to match or even outperform CNN-based detectors, especially in terms of generalization. In this paper, we study the adversarial robustness of AI-generated image detectors, focusing on Contrastive Language-Image Pretraining (CLIP)-based methods that rely on Visual Transformer backbones and comparing their performance with CNN-based methods. We study the robustness to different adversarial attacks under a variety of conditions and analyze both numerical results and frequency-domain patterns. CLIP-based detectors are found to be vulnerable to white-box attacks just like CNN-based detectors. However, attacks do not easily transfer between CNN-based and CLIP-based methods. This is also confirmed by the different distribution of the adversarial noise patterns in the frequency domain. Overall, this analysis provides new insights into the properties of forensic detectors that can help to develop more effective strategies.
Read more7/30/2024
0
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
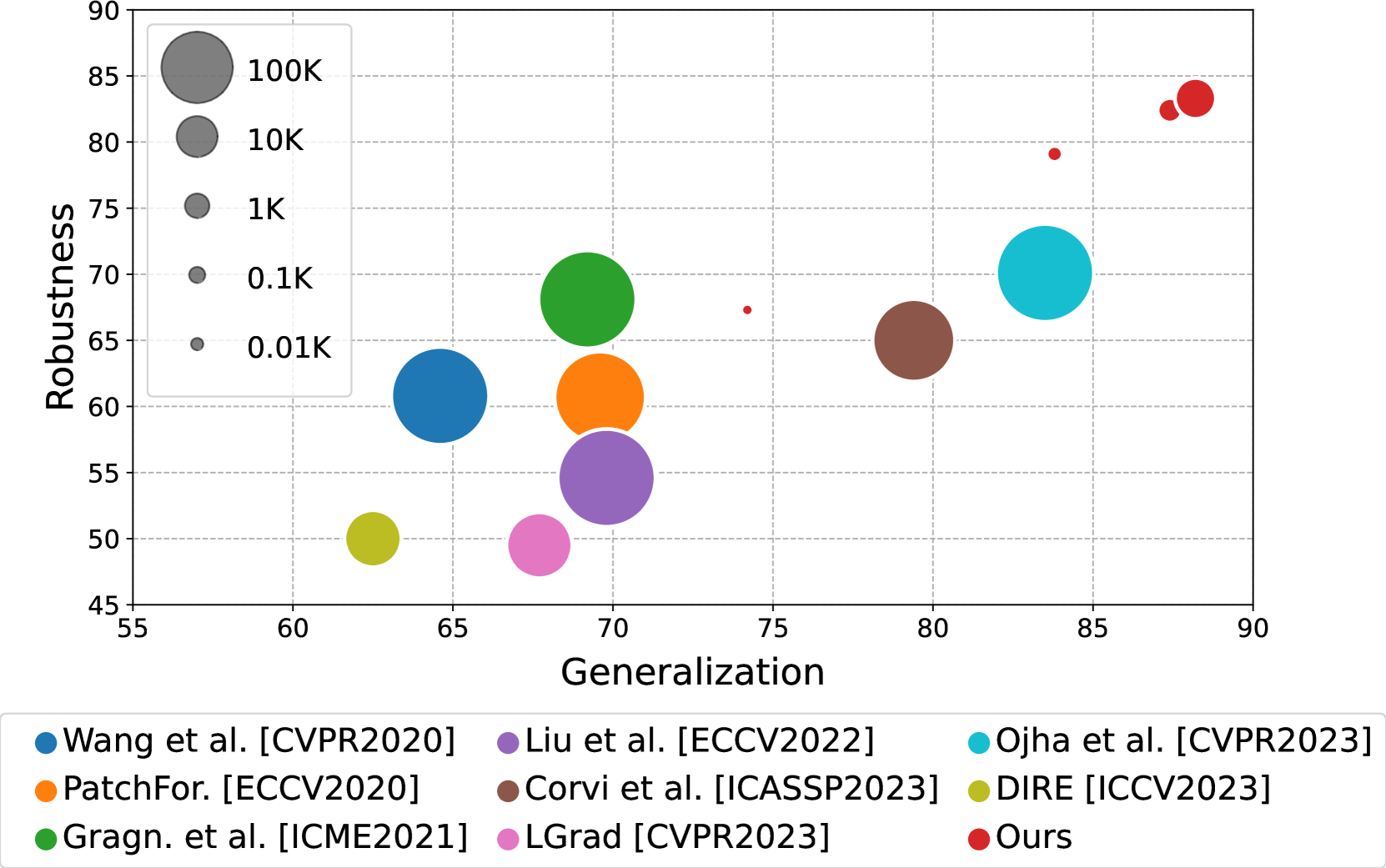
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Read more4/30/2024
0
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
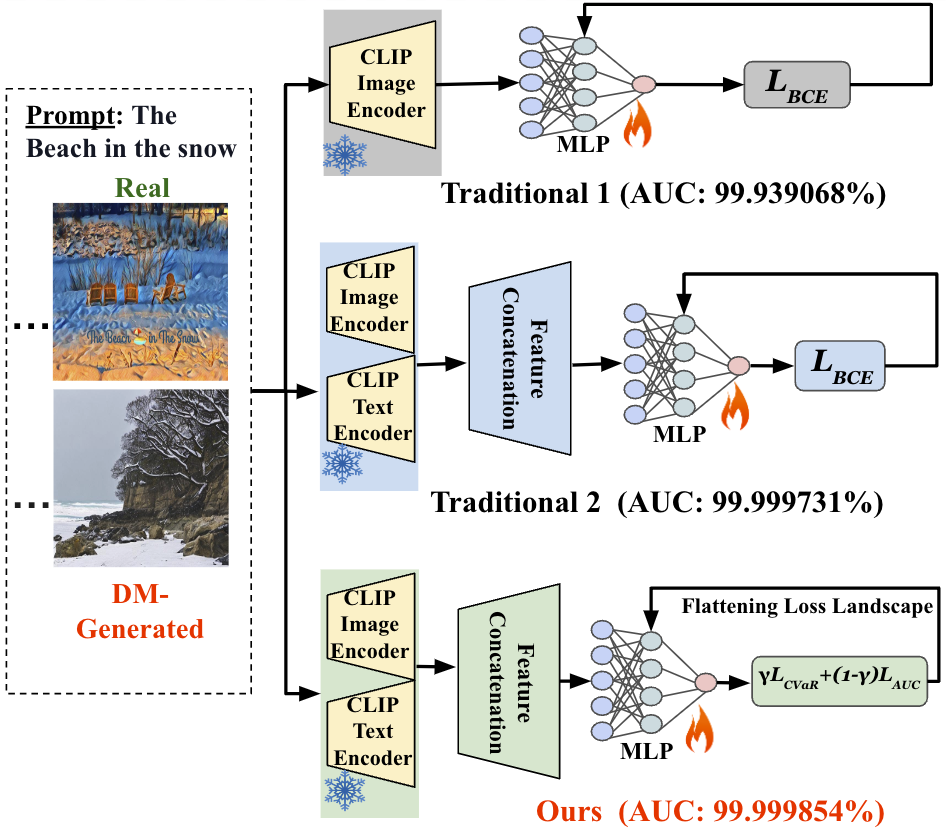
Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector's robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector's generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
Read more9/10/2024

0
Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, Matthias Hein
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
Read more6/6/2024