Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
2402.12336
0
0

Abstract
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
Create account to get full access
Overview
- This paper proposes a new method called "Robust CLIP" for fine-tuning vision embeddings in large vision-language models to improve their robustness against adversarial attacks.
- The method uses unsupervised adversarial training to fine-tune the vision encoder of a pre-trained CLIP model, making the model more robust without requiring additional labeled data.
- The authors demonstrate that Robust CLIP outperforms standard CLIP and other state-of-the-art vision-language models on a range of robustness benchmarks.
Plain English Explanation
The paper focuses on improving the robustness of large vision-language models, which are AI systems that can understand and process both visual and textual information. These models are powerful, but they can be vulnerable to "adversarial attacks" - small, carefully crafted changes to an image that can cause the model to misclassify it.
To address this issue, the researchers developed a new technique called "Robust CLIP." Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models involves fine-tuning the vision encoder of a pre-trained CLIP model using adversarial training. This means exposing the model to slightly modified, adversarial versions of images during the training process, which helps the model become more robust to these types of attacks.
Crucially, the fine-tuning is done in an unsupervised way, without requiring any additional labeled data. This makes the process more efficient and practical than approaches that require manually annotated data.
The researchers show that Robust CLIP outperforms standard CLIP and other state-of-the-art vision-language models on several robustness benchmarks. This means the model is better able to maintain its performance even when faced with adversarial attacks or other types of image distortions.
Overall, this research represents an important step towards building more reliable and secure vision-language models, which have a wide range of applications in areas like image detection, continual learning, and bias mitigation. The techniques developed here could also be applied more broadly to improve the robustness of other types of deep learning models.
Technical Explanation
The key technical innovation in this paper is the Robust CLIP method, which fine-tunes the vision encoder of a pre-trained CLIP model in an unsupervised, adversarial manner.
The CLIP model is a popular large vision-language model that has shown strong performance on a variety of visual tasks. However, like many deep learning models, CLIP can be vulnerable to adversarial attacks, where small, carefully crafted perturbations to an input image can cause the model to misclassify it.
To address this issue, the researchers propose a two-stage fine-tuning process:
-
Unsupervised Adversarial Fine-Tuning: The vision encoder of the pre-trained CLIP model is fine-tuned in an unsupervised manner, using a novel adversarial training objective. This involves generating adversarial examples by applying small, imperceptible perturbations to the input images, and then updating the model parameters to make the vision embeddings more robust to these perturbations.
-
Supervised Fine-Tuning: After the unsupervised adversarial fine-tuning, the researchers perform a standard supervised fine-tuning step on a target task, such as image classification or visual question answering.
The authors show that this two-stage process significantly improves the robustness of the CLIP model, as measured by its performance on a range of robustness benchmarks. Compared to standard CLIP and other state-of-the-art vision-language models, Robust CLIP demonstrates superior performance in the face of adversarial attacks, common corruptions, and natural distribution shifts.
Additionally, the researchers conduct extensive ablation studies to understand the key components of their method, such as the importance of the unsupervised adversarial fine-tuning stage and the choice of adversarial training objective.
Overall, this work represents an important contribution to the field of robust vision-language modeling, and the techniques developed here could potentially be applied to other pre-trained models to improve their robustness.
Critical Analysis
The Robust CLIP method presented in this paper is a promising approach to improving the robustness of large vision-language models. The authors' key insight - that unsupervised adversarial fine-tuning can significantly boost a model's performance on robustness benchmarks - is compelling and well-supported by the experimental results.
However, it's important to note that the paper does not address several potential limitations and caveats of the Robust CLIP method:
-
Computational Overhead: The adversarial fine-tuning process used in Robust CLIP is likely to be computationally intensive, as it requires generating and optimizing against adversarial examples. This could limit the practical applicability of the method, especially for resource-constrained settings.
-
Transferability of Robustness: The paper focuses on evaluating Robust CLIP's performance on specific robustness benchmarks, but it's unclear how well the improved robustness would transfer to real-world deployment scenarios or other types of attacks.
-
Dependence on Pre-trained CLIP: Robust CLIP relies on a pre-trained CLIP model as its starting point. It's possible that the method may not be as effective when applied to other vision-language models with different architectural choices or pre-training procedures.
-
Interpretability and Explainability: The paper does not provide much insight into how the adversarial fine-tuning process affects the internal representations and decision-making of the Robust CLIP model. Improving the interpretability and explainability of robust vision-language models is an important area for future research.
Despite these limitations, the Robust CLIP method represents a valuable contribution to the field of robust AI systems. The authors have demonstrated the potential for unsupervised adversarial fine-tuning to enhance the robustness of large-scale vision-language models, paving the way for further research and development in this area.
Conclusion
The "Robust CLIP" paper presents a novel approach for improving the robustness of large vision-language models against adversarial attacks and other types of input distortions. By fine-tuning the vision encoder of a pre-trained CLIP model using unsupervised adversarial training, the researchers are able to significantly boost the model's performance on a range of robustness benchmarks.
This work is an important step forward in the development of more reliable and secure AI systems, particularly in applications where vision-language models are used, such as image detection, continual learning, and bias mitigation. The techniques developed in this research could also be applied more broadly to improve the robustness of other types of deep learning models.
While the paper does not address certain limitations and caveats, such as the computational overhead of the adversarial fine-tuning process and the interpretability of the resulting model, the Robust CLIP method represents an important contribution to the field of robust AI. As the deployment of large-scale vision-language models becomes more widespread, research like this will be crucial in ensuring the reliability and security of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
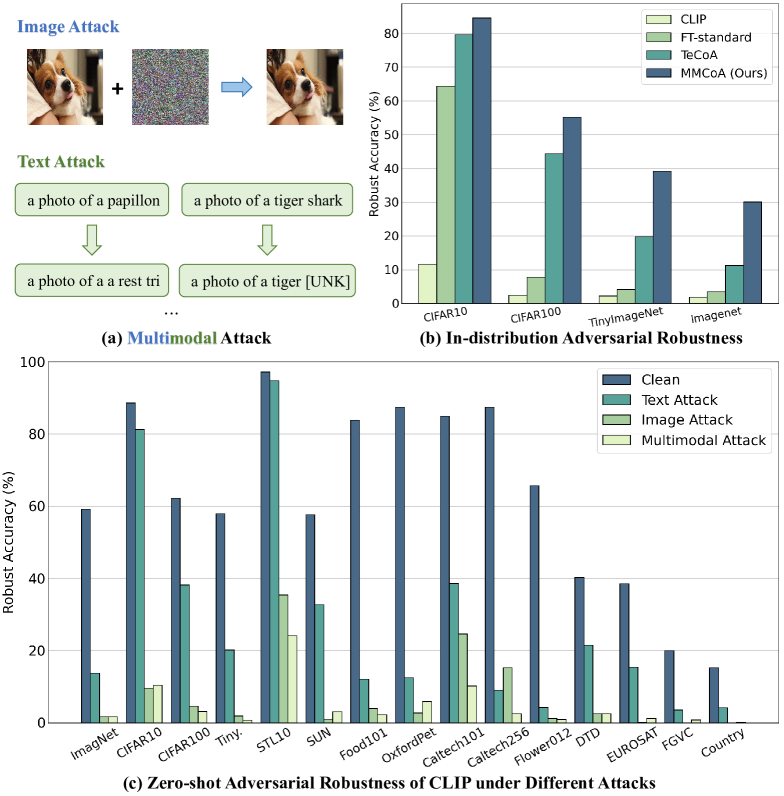
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
0
0
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
5/1/2024
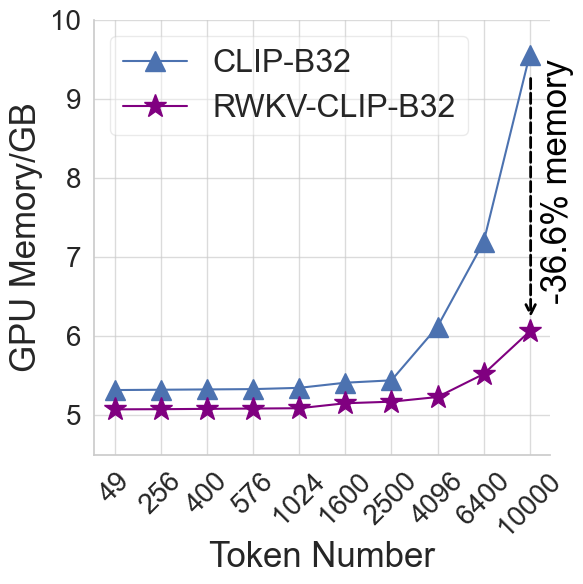
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024
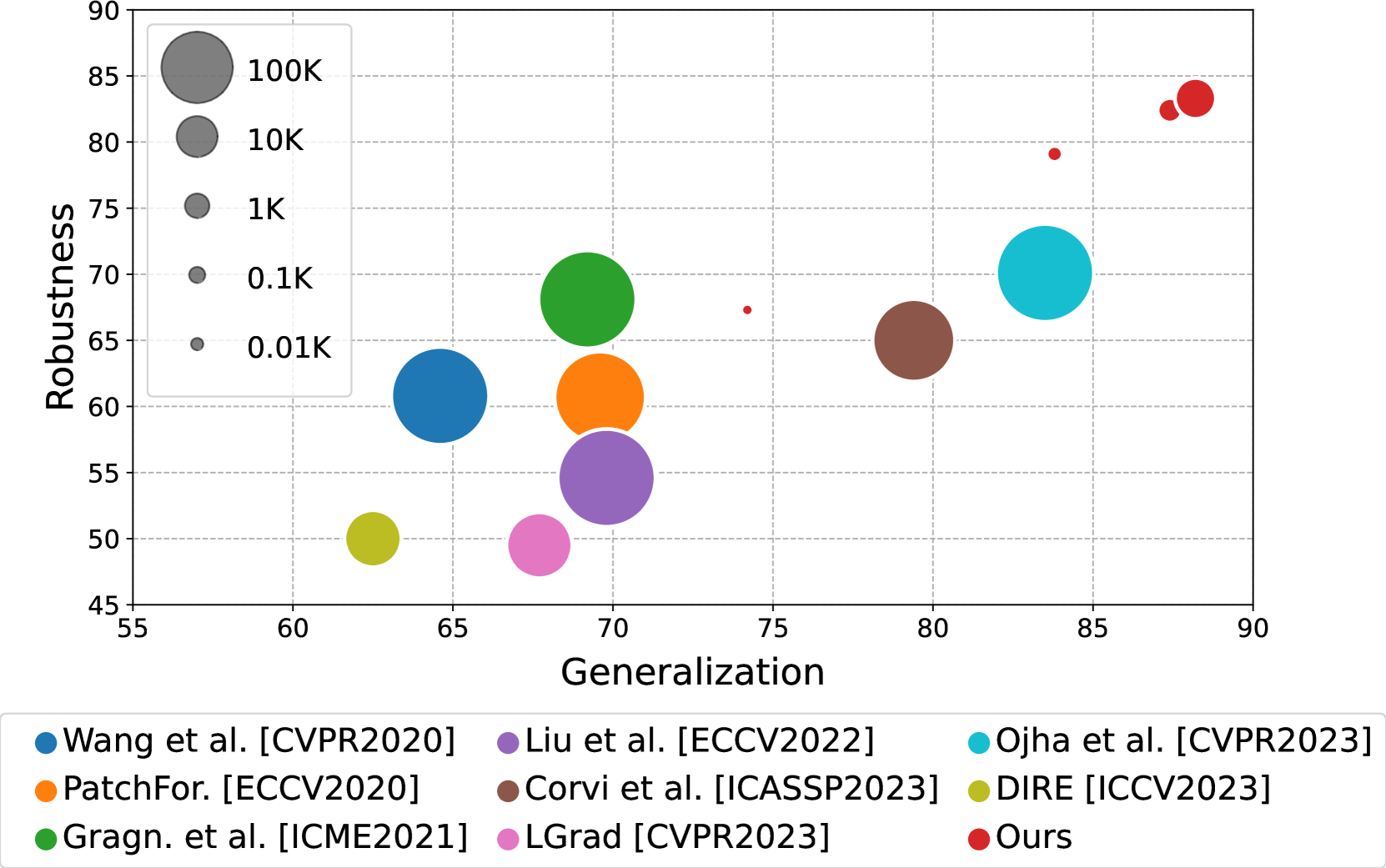
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024
CLAP4CLIP: Continual Learning with Probabilistic Finetuning for Vision-Language Models
Saurav Jha, Dong Gong, Lina Yao
0
0
Continual learning (CL) aims to help deep neural networks to learn new knowledge while retaining what has been learned. Recently, pre-trained vision-language models such as CLIP, with powerful generalizability, have been gaining traction as practical CL candidates. However, the domain mismatch between the pre-training and the downstream CL tasks calls for finetuning of the CLIP on the latter. The deterministic nature of the existing finetuning methods makes them overlook the many possible interactions across the modalities and deems them unsafe for high-risk CL tasks requiring reliable uncertainty estimation. To address these, our work proposes Continual LeArning with Probabilistic finetuning (CLAP). CLAP develops probabilistic modeling over task-specific modules with visual-guided text features, providing more calibrated finetuning in CL. It further alleviates forgetting by exploiting the rich pre-trained knowledge of CLIP for weight initialization and distribution regularization of task-specific modules. Cooperating with the diverse range of existing prompting methods, CLAP can surpass the predominant deterministic finetuning approaches for CL with CLIP. We conclude with out-of-the-box applications of superior uncertainty estimation abilities of CLAP for novel data detection and exemplar selection within CL setups. Our code is available at url{https://github.com/srvCodes/clap4clip}.
5/24/2024