Exploring Adversarial Robustness of Deep State Space Models

0

Sign in to get full access
Overview
- This paper explores the adversarial robustness of deep state space models (SSMs), a class of neural network architectures used for sequence modeling tasks.
- The authors investigate how various adversarial attack techniques can be applied to deep SSMs and evaluate their robustness against such attacks.
- They propose a novel defense mechanism called "robust state space modeling" to improve the adversarial robustness of deep SSMs.
Plain English Explanation
Deep state space models are a type of neural network that can be used to analyze sequential data, such as time series or video. These models work by learning the underlying "state" of the system at each time step, which allows them to make predictions about the future.
However, these models can be vulnerable to adversarial attacks, where small, carefully crafted perturbations to the input data can cause the model to make incorrect predictions. This paper explores how different types of adversarial attacks can affect deep state space models and proposes a new defense mechanism to make them more robust.
The authors show that deep state space models can be susceptible to various adversarial attacks, such as link to "Adversarial Training via Adaptive Knowledge Amalgamation and Ensemble" and link to "Duality between Sharpness-Aware Minimization and Adversarial Training". They then introduce a new defense technique called "robust state space modeling" that can help improve the models' resilience to these attacks.
The key idea behind robust state space modeling is to explicitly incorporate adversarial robustness into the model training process, rather than treating it as a separate concern. This helps the model learn representations that are more resistant to perturbations, without sacrificing its performance on the original task.
Technical Explanation
The paper begins by providing an overview of state space models (SSMs) and their use in deep learning link to "State Space Model: A New Generation Network Alternative". SSMs are a type of neural network architecture that can effectively model the dynamics of sequential data by learning the underlying "state" of the system at each time step.
The authors then describe how adversarial attacks can be applied to deep SSMs. They consider several types of attacks, including link to "Adversarial Training via Adaptive Knowledge Amalgamation and Ensemble" and link to "Duality between Sharpness-Aware Minimization and Adversarial Training", and evaluate their impact on the performance of deep SSMs.
To address the issue of adversarial vulnerability, the authors propose a novel defense mechanism called "robust state space modeling." This approach integrates adversarial robustness into the training process of deep SSMs, rather than treating it as a separate concern. The key idea is to explicitly encourage the model to learn representations that are resistant to perturbations, without compromising its performance on the original task.
The authors evaluate the effectiveness of their robust state space modeling approach through extensive experiments on various datasets and tasks. They demonstrate that their method can significantly improve the adversarial robustness of deep SSMs while maintaining competitive performance on the original tasks.
Critical Analysis
The paper presents a thorough investigation of the adversarial robustness of deep state space models, which is an important and timely topic in the field of machine learning. The authors' proposed "robust state space modeling" approach is a novel and promising defense mechanism that addresses the vulnerability of deep SSMs to adversarial attacks.
One potential limitation of the study is the scope of the evaluated adversarial attacks. While the authors consider several well-known attack types, there may be other attack techniques or scenarios that were not explored in this work. Additionally, the authors do not provide a comprehensive analysis of the computational or training overhead associated with the robust state space modeling approach, which could be an important practical consideration.
Another area that could be explored further is the relationship between the interpretability and robustness of deep SSMs. Link to "Exploring the Interplay of Interpretability and Robustness in Deep Neural Networks" has discussed the potential trade-offs between these two desirable properties, and it would be interesting to see if the robust state space modeling approach has any implications for the interpretability of the learned representations.
Overall, the paper presents a valuable contribution to the understanding of adversarial robustness in deep state space models and proposes a promising defense mechanism. The findings and insights from this work could be useful for researchers and practitioners working on developing more secure and reliable sequence modeling systems.
Conclusion
This paper explores the adversarial robustness of deep state space models, a class of neural network architectures that are commonly used for sequence modeling tasks. The authors investigate how various adversarial attack techniques can affect the performance of deep SSMs and propose a novel defense mechanism called "robust state space modeling" to improve their resilience to such attacks.
The key contribution of this work is the integration of adversarial robustness into the training process of deep SSMs, rather than treating it as a separate concern. This approach helps the models learn representations that are more resistant to perturbations, without compromising their performance on the original tasks.
The findings from this research could have important implications for the development of secure and reliable sequence modeling systems, which are crucial in many real-world applications such as time series analysis, video processing, and natural language processing. The insights and techniques presented in this paper could inspire further advancements in the field of adversarial machine learning and contribute to the broader goal of building more robust and trustworthy artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Adversarial Robustness of Deep State Space Models
Biqing Qi, Yang Luo, Junqi Gao, Pengfei Li, Kai Tian, Zhiyuan Ma, Bowen Zhou
Deep State Space Models (SSMs) have proven effective in numerous task scenarios but face significant security challenges due to Adversarial Perturbations (APs) in real-world deployments. Adversarial Training (AT) is a mainstream approach to enhancing Adversarial Robustness (AR) and has been validated on various traditional DNN architectures. However, its effectiveness in improving the AR of SSMs remains unclear. While many enhancements in SSM components, such as integrating Attention mechanisms and expanding to data-dependent SSM parameterizations, have brought significant gains in Standard Training (ST) settings, their potential benefits in AT remain unexplored. To investigate this, we evaluate existing structural variants of SSMs with AT to assess their AR performance. We observe that pure SSM structures struggle to benefit from AT, whereas incorporating Attention yields a markedly better trade-off between robustness and generalization for SSMs in AT compared to other components. Nonetheless, the integration of Attention also leads to Robust Overfitting (RO) issues. To understand these phenomena, we empirically and theoretically analyze the output error of SSMs under AP. We find that fixed-parameterized SSMs have output error bounds strictly related to their parameters, limiting their AT benefits, while input-dependent SSMs may face the problem of error explosion. Furthermore, we show that the Attention component effectively scales the output error of SSMs during training, enabling them to benefit more from AT, but at the cost of introducing RO due to its high model complexity. Inspired by this, we propose a simple and effective Adaptive Scaling (AdS) mechanism that brings AT performance close to Attention-integrated SSMs without introducing the issue of RO.
Read more6/11/2024
0
Exploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
Enes Altinisik, Safa Messaoud, Husrev Taha Sencar, Hassan Sajjad, Sanjay Chawla
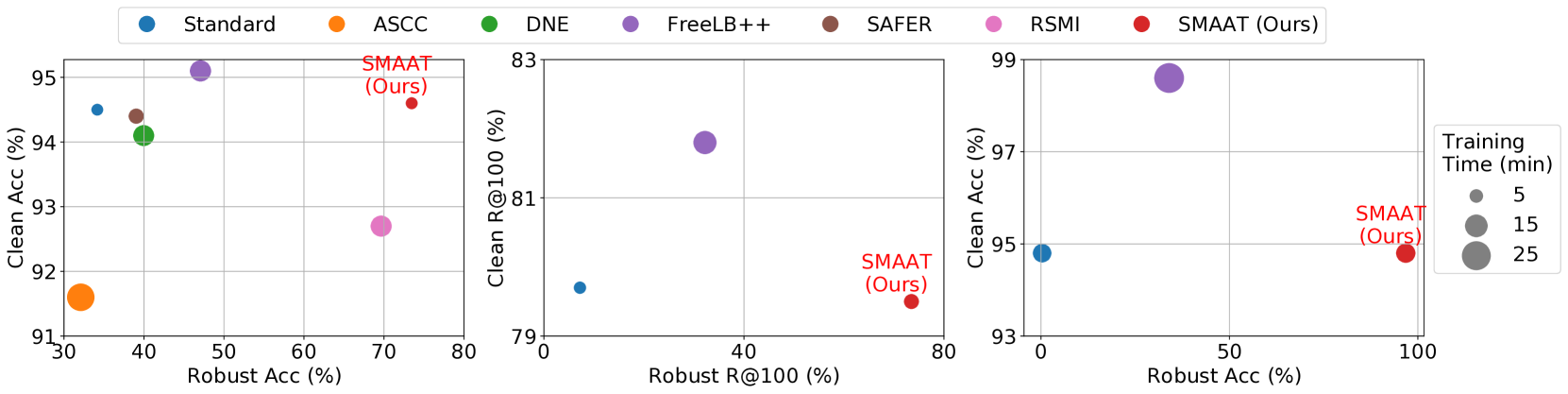
Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
Read more5/28/2024
0
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, Ziwen Wang, Bo Jiang, Chenglong Li, Yaowei Wang, Yonghong Tian, Jin Tang
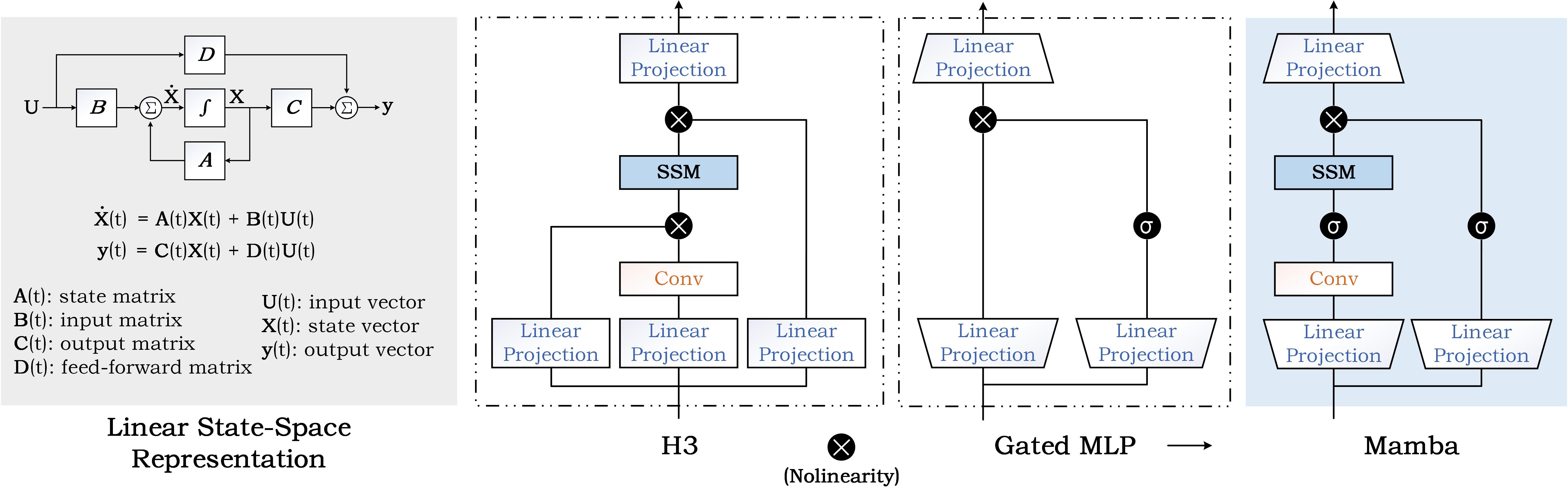
In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
Read more4/16/2024
🏋️
0
On the Duality Between Sharpness-Aware Minimization and Adversarial Training
Yihao Zhang, Hangzhou He, Jingyu Zhu, Huanran Chen, Yifei Wang, Zeming Wei
Adversarial Training (AT), which adversarially perturb the input samples during training, has been acknowledged as one of the most effective defenses against adversarial attacks, yet suffers from inevitably decreased clean accuracy. Instead of perturbing the samples, Sharpness-Aware Minimization (SAM) perturbs the model weights during training to find a more flat loss landscape and improve generalization. However, as SAM is designed for better clean accuracy, its effectiveness in enhancing adversarial robustness remains unexplored. In this work, considering the duality between SAM and AT, we investigate the adversarial robustness derived from SAM. Intriguingly, we find that using SAM alone can improve adversarial robustness. To understand this unexpected property of SAM, we first provide empirical and theoretical insights into how SAM can implicitly learn more robust features, and conduct comprehensive experiments to show that SAM can improve adversarial robustness notably without sacrificing any clean accuracy, shedding light on the potential of SAM to be a substitute for AT when accuracy comes at a higher priority. Code is available at https://github.com/weizeming/SAM_AT.
Read more6/6/2024