On the Duality Between Sharpness-Aware Minimization and Adversarial Training
2402.15152
0
0
🏋️
Abstract
Adversarial Training (AT), which adversarially perturb the input samples during training, has been acknowledged as one of the most effective defenses against adversarial attacks, yet suffers from inevitably decreased clean accuracy. Instead of perturbing the samples, Sharpness-Aware Minimization (SAM) perturbs the model weights during training to find a more flat loss landscape and improve generalization. However, as SAM is designed for better clean accuracy, its effectiveness in enhancing adversarial robustness remains unexplored. In this work, considering the duality between SAM and AT, we investigate the adversarial robustness derived from SAM. Intriguingly, we find that using SAM alone can improve adversarial robustness. To understand this unexpected property of SAM, we first provide empirical and theoretical insights into how SAM can implicitly learn more robust features, and conduct comprehensive experiments to show that SAM can improve adversarial robustness notably without sacrificing any clean accuracy, shedding light on the potential of SAM to be a substitute for AT when accuracy comes at a higher priority. Code is available at https://github.com/weizeming/SAM_AT.
Create account to get full access
Overview
- The paper "On the Duality Between Sharpness-Aware Minimization and Adversarial Training" explores the relationship between two techniques used to improve the robustness of machine learning models: sharpness-aware minimization (SAM) and adversarial training.
- SAM is a method that aims to find model parameters that are less sensitive to small perturbations in the input data, while adversarial training involves training models to be robust against intentionally crafted adversarial examples.
- The paper demonstrates a duality between these two approaches, showing that they can be viewed as solving the same underlying optimization problem.
Plain English Explanation
Machine learning models can sometimes be fooled by small changes to their input data, even if those changes are barely noticeable to a human. This can be a problem in real-world applications, where we want our models to be robust and reliable.
Two techniques have been developed to address this issue: sharpness-aware minimization (SAM) and adversarial training.
SAM tries to find model parameters that are less sensitive to small changes in the input data. This means the model's output doesn't change much even if the input is slightly different. Adversarial training, on the other hand, involves training the model to be robust against intentionally crafted "adversarial examples" - inputs that are designed to trick the model.
The key insight from this paper is that these two approaches are actually solving the same underlying problem, just from different angles. They're both trying to make the model more robust, but they go about it in different ways. This duality between SAM and adversarial training is an important theoretical connection that helps us better understand these techniques and how they can be used together.
Technical Explanation
The paper demonstrates a duality between sharpness-aware minimization (SAM) and adversarial training. Specifically, it shows that the optimization problem solved by SAM can be equivalent to solving the inner maximization problem in adversarial training.
The authors first provide the mathematical formulation of SAM, which aims to find model parameters that minimize the maximum loss over a small neighborhood around the training data. They then show that this is equivalent to solving the inner maximization problem in adversarial training, where the goal is to find the input perturbation that maximizes the model's loss.
To illustrate this duality, the authors present a series of theoretical results and experiments. They show that the solutions obtained by SAM and adversarial training converge to the same set of parameters under certain conditions. They also demonstrate that SAM can be interpreted as a way to approximate the inner maximization problem in adversarial training, which can be computationally expensive.
Furthermore, the paper explores the connections between SAM, layered intrinsic dimensionality, and genetic programming. It discusses how these techniques can be used together to enhance the feature quality and robustness of deep learning models.
Critical Analysis
The paper provides a valuable theoretical analysis of the relationship between sharpness-aware minimization and adversarial training. The authors rigorously demonstrate the duality between these two approaches and offer insights into their connections with other techniques like layered intrinsic dimensionality and genetic programming.
One potential limitation of the study is that it focuses primarily on the theoretical aspects and does not provide a comprehensive evaluation of the practical implications of this duality. While the authors mention potential computational advantages of using SAM as an approximation of adversarial training, further empirical investigations would be helpful to quantify the benefits and trade-offs in real-world scenarios.
Additionally, the paper does not address potential drawbacks or limitations of either SAM or adversarial training. For example, it would be valuable to explore the sensitivity of these techniques to hyperparameter choices, the impact on model generalization, and any potential negative side effects on model performance or training stability.
Overall, the paper makes an important contribution to the understanding of the relationship between these two influential techniques in the field of adversarial robustness. Future work could build upon these insights to develop more practical and effective strategies for improving the robustness of machine learning models.
Conclusion
This paper establishes a duality between sharpness-aware minimization (SAM) and adversarial training, two prominent techniques for improving the robustness of machine learning models. The authors show that these approaches can be viewed as solving the same underlying optimization problem, which provides valuable theoretical insights into their relationship and potential synergies.
The findings of this paper have implications for the design and optimization of robust machine learning systems. By understanding the connections between SAM and adversarial training, researchers and practitioners can better leverage these techniques, either individually or in combination, to enhance the feature quality and reliability of their models. This work also highlights the importance of exploring the theoretical underpinnings of different robustness-enhancing methods to uncover fundamental insights that can guide the development of more effective and efficient approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning
Jacob Mitchell Springer, Vaishnavh Nagarajan, Aditi Raghunathan
0
0
Sharpness-Aware Minimization (SAM) has emerged as a promising alternative optimizer to stochastic gradient descent (SGD). The originally-proposed motivation behind SAM was to bias neural networks towards flatter minima that are believed to generalize better. However, recent studies have shown conflicting evidence on the relationship between flatness and generalization, suggesting that flatness does fully explain SAM's success. Sidestepping this debate, we identify an orthogonal effect of SAM that is beneficial out-of-distribution: we argue that SAM implicitly balances the quality of diverse features. SAM achieves this effect by adaptively suppressing well-learned features which gives remaining features opportunity to be learned. We show that this mechanism is beneficial in datasets that contain redundant or spurious features where SGD falls for the simplicity bias and would not otherwise learn all available features. Our insights are supported by experiments on real data: we demonstrate that SAM improves the quality of features in datasets containing redundant or spurious features, including CelebA, Waterbirds, CIFAR-MNIST, and DomainBed.
6/3/2024
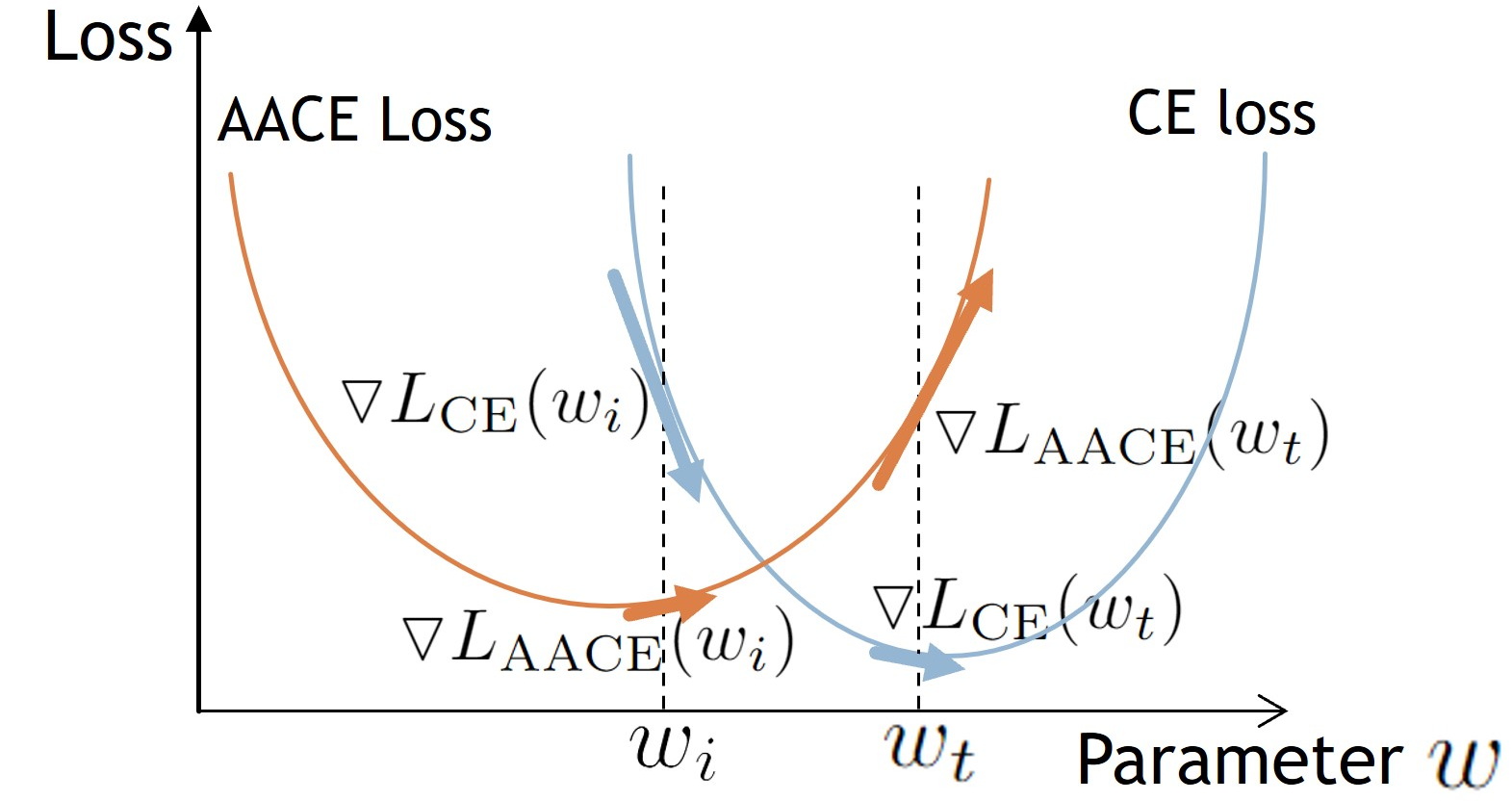
Adaptive Adversarial Cross-Entropy Loss for Sharpness-Aware Minimization
Tanapat Ratchatorn, Masayuki Tanaka
0
0
Recent advancements in learning algorithms have demonstrated that the sharpness of the loss surface is an effective measure for improving the generalization gap. Building upon this concept, Sharpness-Aware Minimization (SAM) was proposed to enhance model generalization and achieved state-of-the-art performance. SAM consists of two main steps, the weight perturbation step and the weight updating step. However, the perturbation in SAM is determined by only the gradient of the training loss, or cross-entropy loss. As the model approaches a stationary point, this gradient becomes small and oscillates, leading to inconsistent perturbation directions and also has a chance of diminishing the gradient. Our research introduces an innovative approach to further enhancing model generalization. We propose the Adaptive Adversarial Cross-Entropy (AACE) loss function to replace standard cross-entropy loss for SAM's perturbation. AACE loss and its gradient uniquely increase as the model nears convergence, ensuring consistent perturbation direction and addressing the gradient diminishing issue. Additionally, a novel perturbation-generating function utilizing AACE loss without normalization is proposed, enhancing the model's exploratory capabilities in near-optimum stages. Empirical testing confirms the effectiveness of AACE, with experiments demonstrating improved performance in image classification tasks using Wide ResNet and PyramidNet across various datasets. The reproduction code is available online
6/21/2024
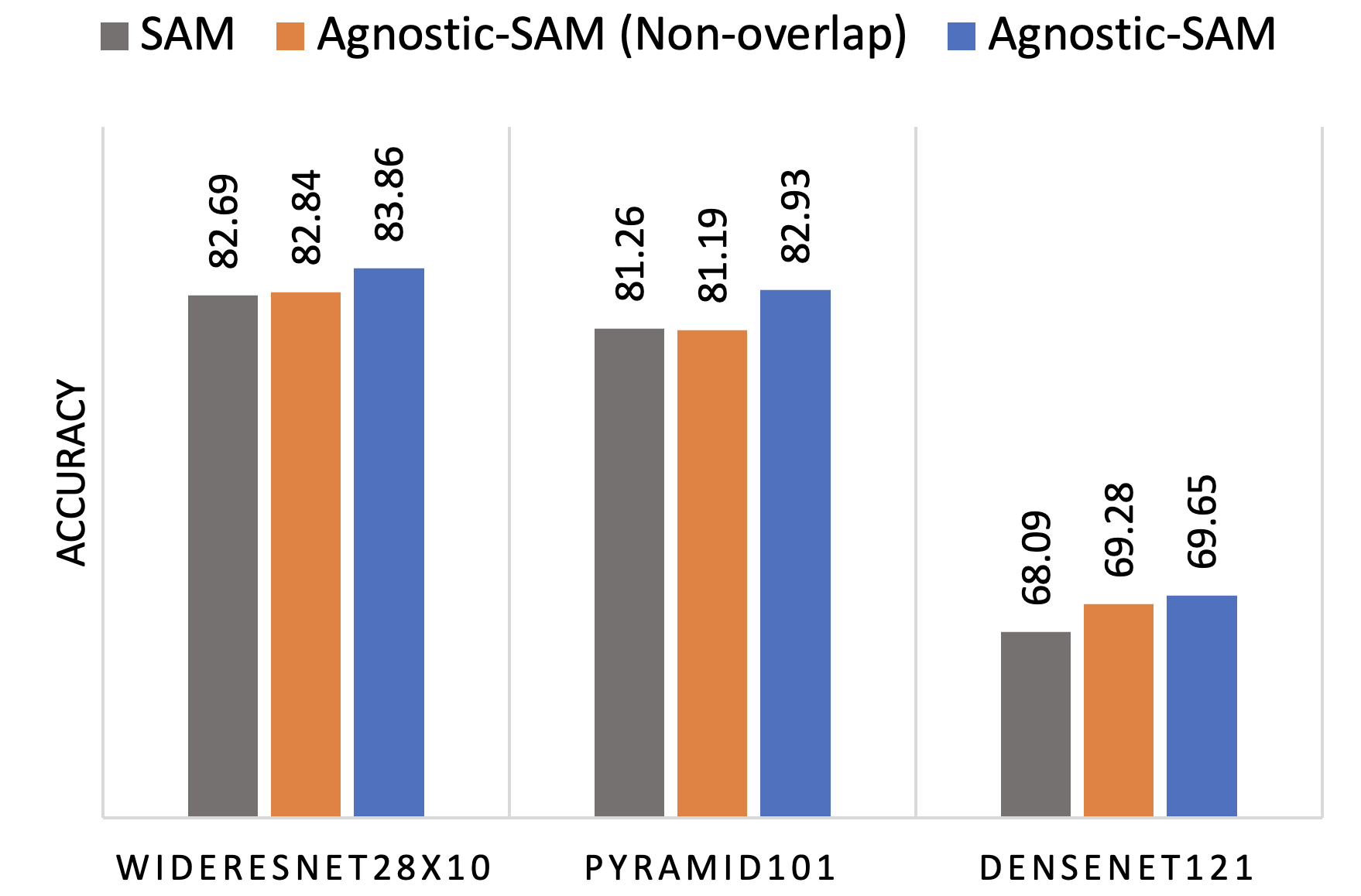
Agnostic Sharpness-Aware Minimization
Van-Anh Nguyen, Quyen Tran, Tuan Truong, Thanh-Toan Do, Dinh Phung, Trung Le
0
0
Sharpness-aware minimization (SAM) has been instrumental in improving deep neural network training by minimizing both the training loss and the sharpness of the loss landscape, leading the model into flatter minima that are associated with better generalization properties. In another aspect, Model-Agnostic Meta-Learning (MAML) is a framework designed to improve the adaptability of models. MAML optimizes a set of meta-models that are specifically tailored for quick adaptation to multiple tasks with minimal fine-tuning steps and can generalize well with limited data. In this work, we explore the connection between SAM and MAML, particularly in terms of enhancing model generalization. We introduce Agnostic-SAM, a novel approach that combines the principles of both SAM and MAML. Agnostic-SAM adapts the core idea of SAM by optimizing the model towards wider local minima using training data, while concurrently maintaining low loss values on validation data. By doing so, it seeks flatter minima that are not only robust to small perturbations but also less vulnerable to data distributional shift problems. Our experimental results demonstrate that Agnostic-SAM significantly improves generalization over baselines across a range of datasets and under challenging conditions such as noisy labels and data limitation.
6/13/2024

Efficient Sharpness-Aware Minimization for Molecular Graph Transformer Models
Yili Wang, Kaixiong Zhou, Ninghao Liu, Ying Wang, Xin Wang
0
0
Sharpness-aware minimization (SAM) has received increasing attention in computer vision since it can effectively eliminate the sharp local minima from the training trajectory and mitigate generalization degradation. However, SAM requires two sequential gradient computations during the optimization of each step: one to obtain the perturbation gradient and the other to obtain the updating gradient. Compared with the base optimizer (e.g., Adam), SAM doubles the time overhead due to the additional perturbation gradient. By dissecting the theory of SAM and observing the training gradient of the molecular graph transformer, we propose a new algorithm named GraphSAM, which reduces the training cost of SAM and improves the generalization performance of graph transformer models. There are two key factors that contribute to this result: (i) textit{gradient approximation}: we use the updating gradient of the previous step to approximate the perturbation gradient at the intermediate steps smoothly (textbf{increases efficiency}); (ii) textit{loss landscape approximation}: we theoretically prove that the loss landscape of GraphSAM is limited to a small range centered on the expected loss of SAM (textbf{guarantees generalization performance}). The extensive experiments on six datasets with different tasks demonstrate the superiority of GraphSAM, especially in optimizing the model update process. The code is in:https://github.com/YL-wang/GraphSAM/tree/graphsam
6/21/2024