Exploring AIGC Video Quality: A Focus on Visual Harmony, Video-Text Consistency and Domain Distribution Gap
2404.13573
0
0

Abstract
The recent advancements in Text-to-Video Artificial Intelligence Generated Content (AIGC) have been remarkable. Compared with traditional videos, the assessment of AIGC videos encounters various challenges: visual inconsistency that defy common sense, discrepancies between content and the textual prompt, and distribution gap between various generative models, etc. Target at these challenges, in this work, we categorize the assessment of AIGC video quality into three dimensions: visual harmony, video-text consistency, and domain distribution gap. For each dimension, we design specific modules to provide a comprehensive quality assessment of AIGC videos. Furthermore, our research identifies significant variations in visual quality, fluidity, and style among videos generated by different text-to-video models. Predicting the source generative model can make the AIGC video features more discriminative, which enhances the quality assessment performance. The proposed method was used in the third-place winner of the NTIRE 2024 Quality Assessment for AI-Generated Content - Track 2 Video, demonstrating its effectiveness. Code will be available at https://github.com/Coobiw/TriVQA.
Create account to get full access
Overview
- This paper explores the quality assessment of AI-generated (AIGC) videos, focusing on three key aspects: visual harmony, video-text consistency, and domain distribution gap.
- The authors propose novel metrics and benchmarks to evaluate these aspects, aiming to provide a comprehensive framework for AIGC video quality assessment.
- The research aims to advance the understanding of AIGC video quality and inform the development of better AIGC systems.
Plain English Explanation
The paper investigates the quality of videos created by AI systems, with a particular focus on three key areas: visual harmony, consistency between video and text, and the gap between the training data and the real-world data.
Visual harmony refers to how well the different elements in the video, such as colors, shapes, and compositions, work together to create a visually pleasing and coherent experience. The researchers developed new ways to measure this, which can help identify areas where the AI-generated videos need improvement.
Video-text consistency is about how well the content of the video aligns with the accompanying text or captions. This is important because AIGC videos often have text or narration that should match the visual content. The paper introduces new methods to assess this consistency.
The domain distribution gap is the difference between the data the AI system was trained on and the real-world data it might encounter when deployed. This can affect the system's performance, and the paper explores ways to measure and understand this gap.
By addressing these three aspects, the research aims to provide a more comprehensive framework for evaluating the quality of AIGC videos. This can help drive the development of better AI systems that create higher-quality videos, which could have applications in areas like video generation from text, text-to-audible video generation, and cross-modal generative communications.
Technical Explanation
The paper addresses three key aspects of AIGC video quality assessment:
-
Visual Harmony: The authors propose a no-reference video quality assessment (NRQVA) method to measure the visual harmony of AIGC videos. This involves developing new objective metrics to quantify attributes like color harmony, spatial composition, and temporal consistency.
-
Video-Text Consistency: To assess the alignment between the video content and accompanying text, the researchers introduce a new benchmark called AIGIQA-20K, a large-scale dataset of AIGC videos with text annotations. They then develop novel evaluation metrics to measure various aspects of video-text consistency.
-
Domain Distribution Gap: The authors analyze the distribution gap between the training data used to develop AIGC systems and the real-world data these systems may encounter. They propose a PCQA-Strong Baseline method to quantify this gap and understand its impact on AIGC video quality.
Through extensive experiments, the paper demonstrates the effectiveness of the proposed metrics and benchmarks in capturing the key aspects of AIGC video quality. The insights gained can inform the design of better AIGC systems and guide future research in this area.
Critical Analysis
The paper presents a comprehensive and well-designed framework for AIGC video quality assessment, addressing important aspects that were not previously explored in depth. However, there are a few potential limitations and areas for further research:
-
The proposed metrics, while novel and insightful, may not fully capture the subjective and holistic nature of video quality perception. Additional user studies or human-in-the-loop evaluations could provide valuable insights.
-
The AIGIQA-20K dataset, while a significant contribution, may not represent the full diversity of AIGC videos in the real world. Expanding the dataset or exploring cross-dataset evaluations could strengthen the findings.
-
The analysis of the domain distribution gap provides useful insights, but the impact of this gap on the performance of specific AIGC systems is not thoroughly explored. Further investigations into the relationships between distribution shift and video quality could yield additional insights.
-
The paper focuses on three key aspects of AIGC video quality, but there may be other important factors, such as emotional engagement, storytelling, or coherence, that could be incorporated into a more comprehensive framework.
Despite these potential limitations, the research presented in this paper represents an important step towards a deeper understanding of AIGC video quality and provides a solid foundation for future work in this area.
Conclusion
This paper introduces a comprehensive framework for assessing the quality of AI-generated videos, focusing on three key aspects: visual harmony, video-text consistency, and the domain distribution gap. The authors propose novel metrics and benchmarks to evaluate these aspects, aiming to advance the state of the art in AIGC video quality assessment.
The insights gained from this research can inform the development of better AIGC systems, leading to the creation of higher-quality videos that are more visually appealing, semantically consistent, and robust to real-world deployment conditions. This could have far-reaching implications for a wide range of applications, from video generation from text to text-to-audible video generation and cross-modal generative communications.
Overall, this paper represents an important contribution to the field of AIGC video quality assessment and lays the groundwork for future research in this rapidly evolving area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

PCQA: A Strong Baseline for AIGC Quality Assessment Based on Prompt Condition
Xi Fang, Weigang Wang, Xiaoxin Lv, Jun Yan
0
0
The development of Large Language Models (LLM) and Diffusion Models brings the boom of Artificial Intelligence Generated Content (AIGC). It is essential to build an effective quality assessment framework to provide a quantifiable evaluation of different images or videos based on the AIGC technologies. The content generated by AIGC methods is driven by the crafted prompts. Therefore, it is intuitive that the prompts can also serve as the foundation of the AIGC quality assessment. This study proposes an effective AIGC quality assessment (QA) framework. First, we propose a hybrid prompt encoding method based on a dual-source CLIP (Contrastive Language-Image Pre-Training) text encoder to understand and respond to the prompt conditions. Second, we propose an ensemble-based feature mixer module to effectively blend the adapted prompt and vision features. The empirical study practices in two datasets: AIGIQA-20K (AI-Generated Image Quality Assessment database) and T2VQA-DB (Text-to-Video Quality Assessment DataBase), which validates the effectiveness of our proposed method: Prompt Condition Quality Assessment (PCQA). Our proposed simple and feasible framework may promote research development in the multimodal generation field.
4/23/2024
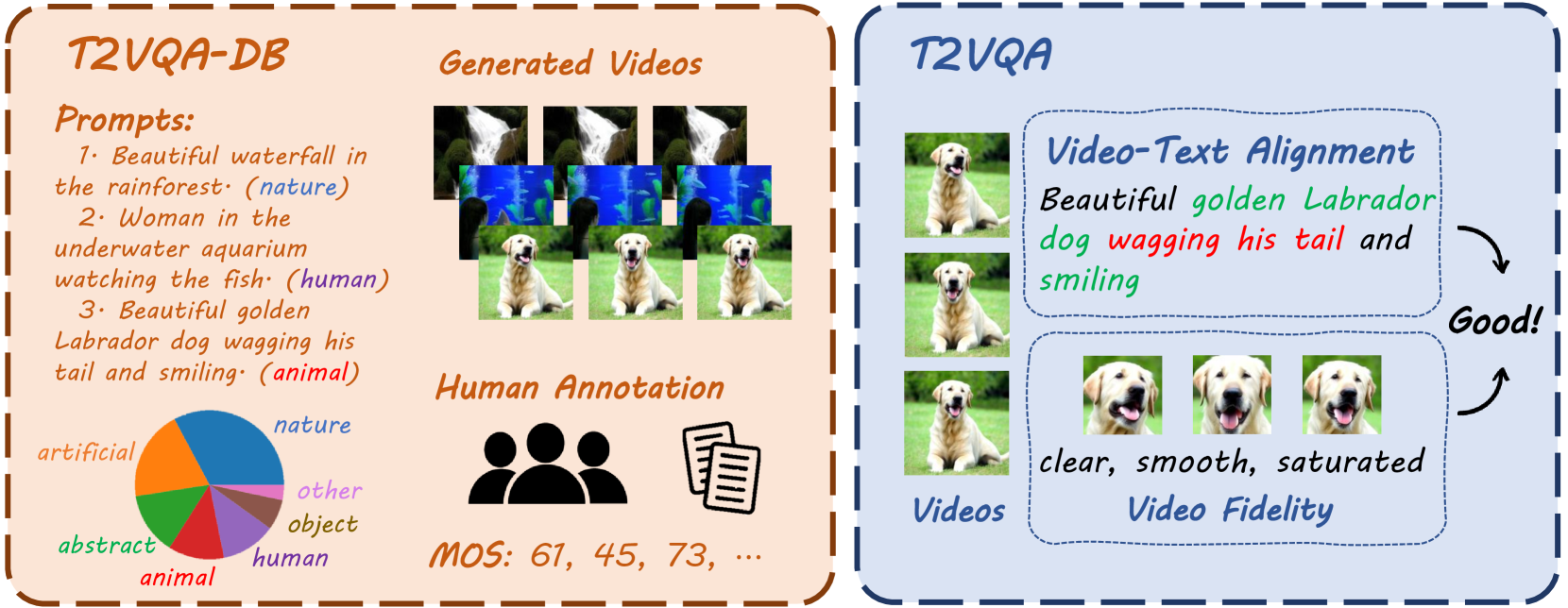
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, Ning Liu
0
0
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
5/21/2024
🗣️
NTIRE 2024 Quality Assessment of AI-Generated Content Challenge
Xiaohong Liu, Xiongkuo Min, Guangtao Zhai, Chunyi Li, Tengchuan Kou, Wei Sun, Haoning Wu, Yixuan Gao, Yuqin Cao, Zicheng Zhang, Xiele Wu, Radu Timofte, Fei Peng, Huiyuan Fu, Anlong Ming, Chuanming Wang, Huadong Ma, Shuai He, Zifei Dou, Shu Chen, Huacong Zhang, Haiyi Xie, Chengwei Wang, Baoying Chen, Jishen Zeng, Jianquan Yang, Weigang Wang, Xi Fang, Xiaoxin Lv, Jun Yan, Tianwu Zhi, Yabin Zhang, Yaohui Li, Yang Li, Jingwen Xu, Jianzhao Liu, Yiting Liao, Junlin Li, Zihao Yu, Yiting Lu, Xin Li, Hossein Motamednia, S. Farhad Hosseini-Benvidi, Fengbin Guan, Ahmad Mahmoudi-Aznaveh, Azadeh Mansouri, Ganzorig Gankhuyag, Kihwan Yoon, Yifang Xu, Haotian Fan, Fangyuan Kong, Shiling Zhao, Weifeng Dong, Haibing Yin, Li Zhu, Zhiling Wang, Bingchen Huang, Avinab Saha, Sandeep Mishra, Shashank Gupta, Rajesh Sureddi, Oindrila Saha, Luigi Celona, Simone Bianco, Paolo Napoletano, Raimondo Schettini, Junfeng Yang, Jing Fu, Wei Zhang, Wenzhi Cao, Limei Liu, Han Peng, Weijun Yuan, Zhan Li, Yihang Cheng, Yifan Deng, Haohui Li, Bowen Qu, Yao Li, Shuqing Luo, Shunzhou Wang, Wei Gao, Zihao Lu, Marcos V. Conde, Xinrui Wang, Zhibo Chen, Ruling Liao, Yan Ye, Qiulin Wang, Bing Li, Zhaokun Zhou, Miao Geng, Rui Chen, Xin Tao, Xiaoyu Liang, Shangkun Sun, Xingyuan Ma, Jiaze Li, Mengduo Yang, Haoran Xu, Jie Zhou, Shiding Zhu, Bohan Yu, Pengfei Chen, Xinrui Xu, Jiabin Shen, Zhichao Duan, Erfan Asadi, Jiahe Liu, Qi Yan, Youran Qu, Xiaohui Zeng, Lele Wang, Renjie Liao
0
0
This paper reports on the NTIRE 2024 Quality Assessment of AI-Generated Content Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2024. This challenge is to address a major challenge in the field of image and video processing, namely, Image Quality Assessment (IQA) and Video Quality Assessment (VQA) for AI-Generated Content (AIGC). The challenge is divided into the image track and the video track. The image track uses the AIGIQA-20K, which contains 20,000 AI-Generated Images (AIGIs) generated by 15 popular generative models. The image track has a total of 318 registered participants. A total of 1,646 submissions are received in the development phase, and 221 submissions are received in the test phase. Finally, 16 participating teams submitted their models and fact sheets. The video track uses the T2VQA-DB, which contains 10,000 AI-Generated Videos (AIGVs) generated by 9 popular Text-to-Video (T2V) models. A total of 196 participants have registered in the video track. A total of 991 submissions are received in the development phase, and 185 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. Some methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on AIGC.
5/8/2024
Fake Artificial Intelligence Generated Contents (FAIGC): A Survey of Theories, Detection Methods, and Opportunities
Xiaomin Yu, Yezhaohui Wang, Yanfang Chen, Zhen Tao, Dinghao Xi, Shichao Song, Simin Niu, Zhiyu Li
0
0
In recent years, generative artificial intelligence models, represented by Large Language Models (LLMs) and Diffusion Models (DMs), have revolutionized content production methods. These artificial intelligence-generated content (AIGC) have become deeply embedded in various aspects of daily life and work. However, these technologies have also led to the emergence of Fake Artificial Intelligence Generated Content (FAIGC), posing new challenges in distinguishing genuine information. It is crucial to recognize that AIGC technology is akin to a double-edged sword; its potent generative capabilities, while beneficial, also pose risks for the creation and dissemination of FAIGC. In this survey, We propose a new taxonomy that provides a more comprehensive breakdown of the space of FAIGC methods today. Next, we explore the modalities and generative technologies of FAIGC. We introduce FAIGC detection methods and summarize the related benchmark from various perspectives. Finally, we discuss outstanding challenges and promising areas for future research.
5/6/2024