TAVGBench: Benchmarking Text to Audible-Video Generation
2404.14381
0
0
Abstract
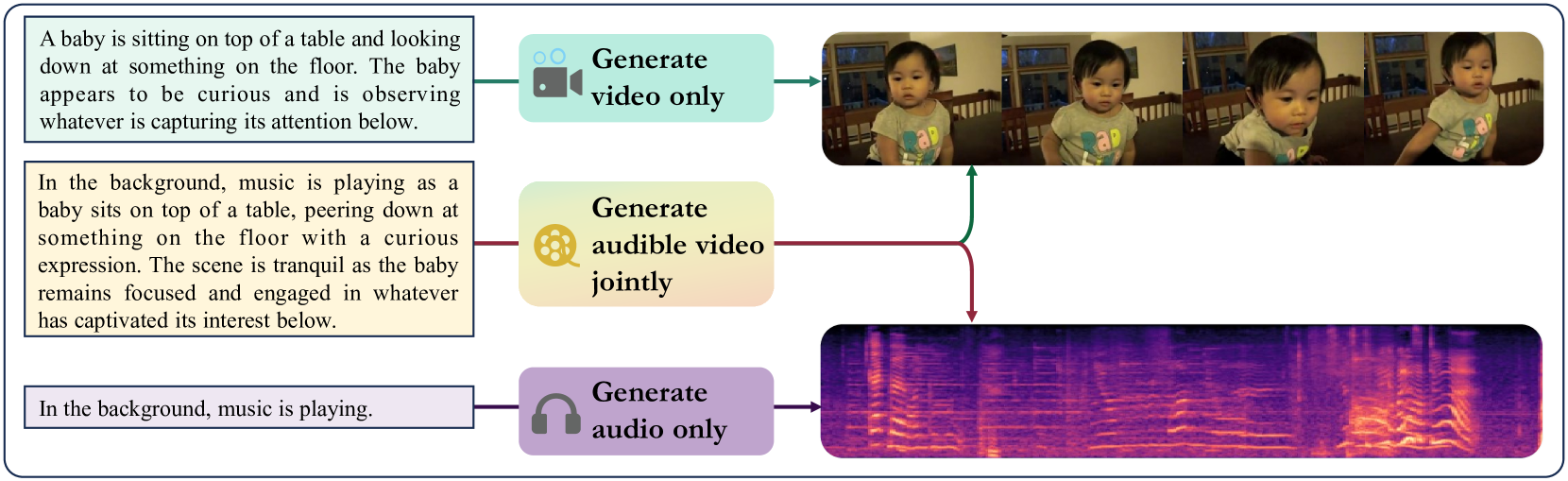
The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.
Create account to get full access
Overview
- This paper introduces TAVGBench, a new benchmark for evaluating text-to-audible-video generation models.
- TAVGBench aims to serve as a standardized evaluation platform for these types of AI models, which can generate synchronized audio and video outputs from text inputs.
- The benchmark includes a diverse dataset of text prompts, as well as metrics for assessing the quality, accuracy, and synchronization of the generated audible-video outputs.
Plain English Explanation
The paper describes a new benchmark called TAVGBench that is designed to test and compare AI models that can generate synchronized audio and video outputs from text inputs. This is an emerging area of AI known as "text-to-audible-video generation," where the goal is to create animated videos with matching speech that correspond to a given text prompt.
The TAVGBench includes a diverse dataset of text prompts that the AI models can use to generate these audible-video outputs. It also defines a set of metrics that can be used to evaluate the quality, accuracy, and synchronization of the generated content. This provides a standardized way to assess and compare the performance of different text-to-audible-video generation models.
The availability of a benchmark like TAVGBench is important, as it allows researchers and developers to rigorously test their AI models and identify areas for improvement. This can help advance the state-of-the-art in this emerging field and unlock new applications, such as automated video creation, visual text-to-speech, and ad hoc video search.
Technical Explanation
The paper introduces TAVGBench, a new benchmark for evaluating text-to-audible-video generation models. The benchmark includes a diverse dataset of text prompts, along with a set of metrics for assessing the quality, accuracy, and synchronization of the generated audible-video outputs.
The dataset in TAVGBench covers a range of topics and styles, from descriptive narrations to dialogue-based scripts. The text prompts are designed to challenge the AI models in various ways, such as generating coherent and natural-sounding speech, as well as creating visually compelling animated videos that align with the content.
The evaluation metrics in TAVGBench include both subjective and objective measures. Subjective metrics focus on the overall quality and believability of the generated audible-video content, as perceived by human raters. Objective metrics assess the accuracy of the speech and lip movements, as well as the temporal synchronization between the audio and video components.
The paper also introduces a novel model called TAVDiffusion, which is designed specifically for text-to-audible-video generation. TAVDiffusion leverages diffusion-based models to generate the audio and video outputs in a well-aligned and coherent manner.
Critical Analysis
The TAVGBench benchmark represents an important step forward in the field of text-to-audible-video generation. By providing a standardized evaluation platform, the benchmark can help drive progress and innovation in this area of AI.
One potential limitation of the TAVGBench dataset is the scope of the text prompts. While the authors have aimed to include a diverse range of topics and styles, there may be opportunities to expand the dataset further to capture an even wider range of use cases and challenge the AI models in new ways.
Additionally, the paper does not delve deeply into the limitations or potential biases of the TAVDiffusion model. As with any AI system, it is important to carefully examine the model's performance across different demographics and use cases to ensure it does not perpetuate or amplify societal biases.
Future research could also explore ways to incorporate multimodal feedback, such as allowing human raters to provide comments or annotations on the generated audible-video outputs. This could provide valuable insights to further refine the benchmark and the underlying models.
Conclusion
The TAVGBench benchmark introduced in this paper represents a significant advancement in the field of text-to-audible-video generation. By providing a standardized evaluation platform, the benchmark can help drive progress and innovation in this area of AI, ultimately unlocking new applications and use cases, such as aligning diffusion-based text-to-video generation and improving interpretable video search embeddings.
The authors' introduction of the TAVDiffusion model also represents a valuable contribution to the field, demonstrating the potential of diffusion-based approaches for tackling the challenges of text-to-audible-video generation. As the research in this area continues to evolve, the TAVGBench benchmark will serve as an essential tool for evaluating and comparing the performance of various models and techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, Ning Liu
0
0
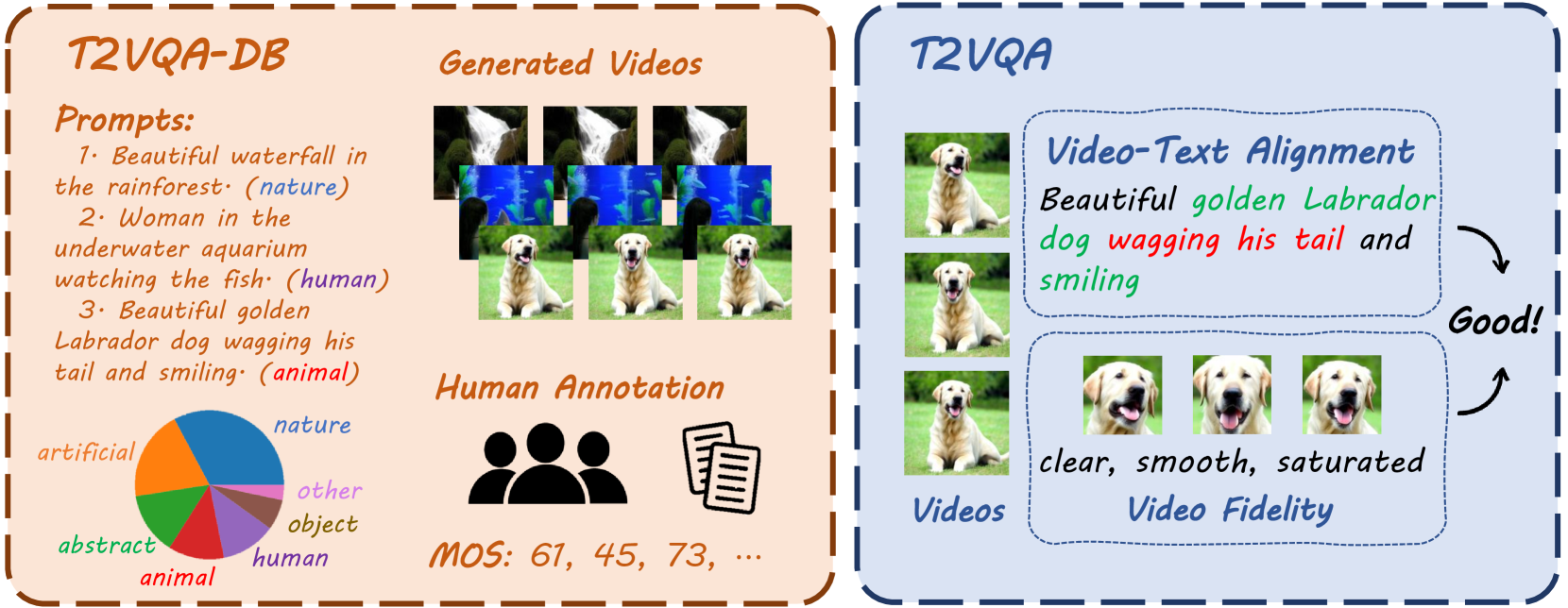
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
5/21/2024
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
0
0
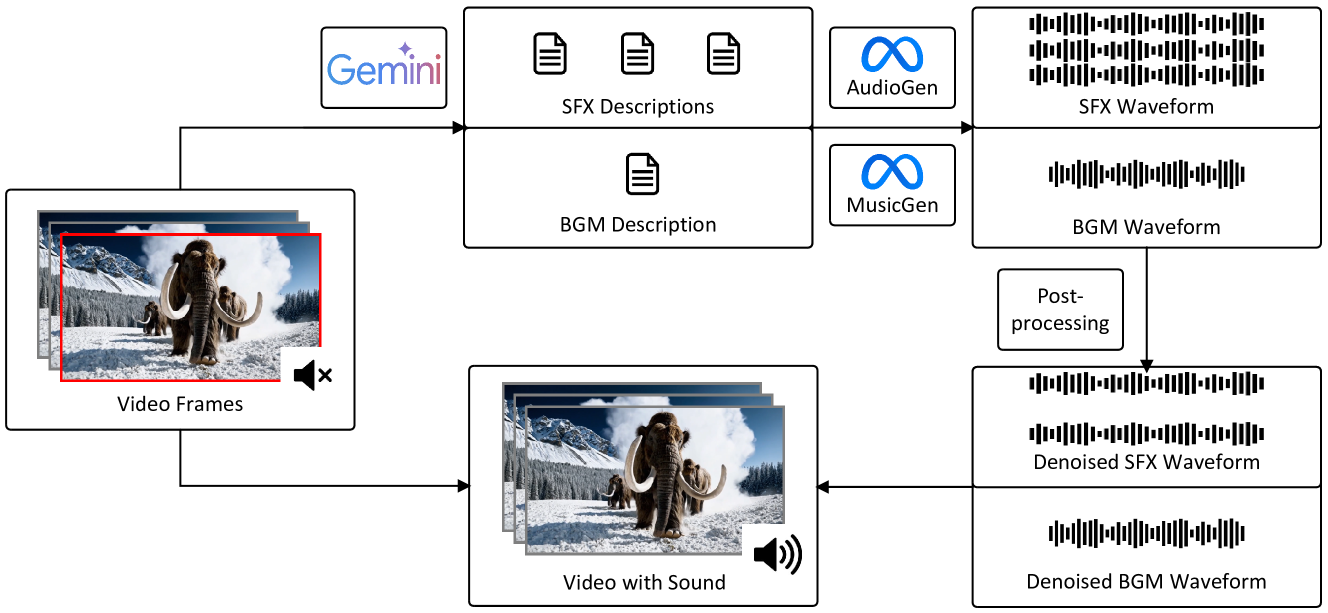
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
4/29/2024
🛸
Evaluating Text-to-Visual Generation with Image-to-Text Generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, Deva Ramanan
0
0
Despite significant progress in generative AI, comprehensive evaluation remains challenging because of the lack of effective metrics and standardized benchmarks. For instance, the widely-used CLIPScore measures the alignment between a (generated) image and text prompt, but it fails to produce reliable scores for complex prompts involving compositions of objects, attributes, and relations. One reason is that text encoders of CLIP can notoriously act as a bag of words, conflating prompts such as the horse is eating the grass with the grass is eating the horse. To address this, we introduce the VQAScore, which uses a visual-question-answering (VQA) model to produce an alignment score by computing the probability of a Yes answer to a simple Does this figure show '{text}'? question. Though simpler than prior art, VQAScore computed with off-the-shelf models produces state-of-the-art results across many (8) image-text alignment benchmarks. We also compute VQAScore with an in-house model that follows best practices in the literature. For example, we use a bidirectional image-question encoder that allows image embeddings to depend on the question being asked (and vice versa). Our in-house model, CLIP-FlanT5, outperforms even the strongest baselines that make use of the proprietary GPT-4V. Interestingly, although we train with only images, VQAScore can also align text with video and 3D models. VQAScore allows researchers to benchmark text-to-visual generation using complex texts that capture the compositional structure of real-world prompts. We introduce GenAI-Bench, a more challenging benchmark with 1,600 compositional text prompts that require parsing scenes, objects, attributes, relationships, and high-order reasoning like comparison and logic. GenAI-Bench also offers over 15,000 human ratings for leading image and video generation models such as Stable Diffusion, DALL-E 3, and Gen2.
6/19/2024

Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, Soujanya Poria
0
0
Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
4/17/2024