Exploring Data Efficiency in Zero-Shot Learning with Diffusion Models
2406.02929
0
0
📊
Abstract
Zero-Shot Learning (ZSL) aims to enable classifiers to identify unseen classes by enhancing data efficiency at the class level. This is achieved by generating image features from pre-defined semantics of unseen classes. However, most current approaches heavily depend on the number of samples from seen classes, i.e. they do not consider instance-level effectiveness. In this paper, we demonstrate that limited seen examples generally result in deteriorated performance of generative models. To overcome these challenges, we propose ZeroDiff, a Diffusion-based Generative ZSL model. This unified framework incorporates diffusion models to improve data efficiency at both the class and instance levels. Specifically, for instance-level effectiveness, ZeroDiff utilizes a forward diffusion chain to transform limited data into an expanded set of noised data. For class-level effectiveness, we design a two-branch generation structure that consists of a Diffusion-based Feature Generator (DFG) and a Diffusion-based Representation Generator (DRG). DFG focuses on learning and sampling the distribution of cross-entropy-based features, whilst DRG learns the supervised contrastive-based representation to boost the zero-shot capabilities of DFG. Additionally, we employ three discriminators to evaluate generated features from various aspects and introduce a Wasserstein-distance-based mutual learning loss to transfer knowledge among discriminators, thereby enhancing guidance for generation. Demonstrated through extensive experiments on three popular ZSL benchmarks, our ZeroDiff not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code will be released upon acceptance.
Create account to get full access
Overview
- The paper introduces a new method called ZeroDiff, a Diffusion-based Generative Zero-Shot Learning (ZSL) model.
- ZSL aims to enable classifiers to identify unseen classes by enhancing data efficiency at the class level.
- The proposed ZeroDiff framework incorporates diffusion models to improve data efficiency at both the class and instance levels.
Plain English Explanation
Zero-Shot Learning (ZSL) is a technique that allows AI models to recognize objects or concepts they've never seen before. This is done by using information about the semantic properties of the unseen classes, such as their names or descriptions. However, most current ZSL approaches heavily depend on having a large number of examples from the "seen" classes (classes the model has been trained on) which can limit their effectiveness.
To address this, the researchers developed a new model called ZeroDiff. ZeroDiff uses a diffusion-based generative approach to improve data efficiency at both the class and instance levels. For instance-level effectiveness, it transforms limited training data into a larger set of noisy samples, which can help the model learn better. For class-level effectiveness, ZeroDiff has a two-branch structure that focuses on learning the distribution of features and representations to boost the model's zero-shot capabilities.
Additionally, ZeroDiff employs multiple discriminators to evaluate the generated features from different perspectives and introduces a special loss function to help transfer knowledge between the discriminators, further enhancing the model's performance.
The researchers demonstrate through extensive experiments that ZeroDiff outperforms existing ZSL methods and maintains robust performance even with limited training data. This could make ZSL techniques more practical and accessible for real-world applications.
Technical Explanation
The key elements of the ZeroDiff framework are:
-
Instance-level Effectiveness: ZeroDiff utilizes a forward diffusion chain to transform limited training data into an expanded set of noised data, improving data efficiency at the instance level.
-
Class-level Effectiveness: ZeroDiff has a two-branch generation structure that consists of a Diffusion-based Feature Generator (DFG) and a Diffusion-based Representation Generator (DRG). DFG focuses on learning and sampling the distribution of cross-entropy-based features, while DRG learns the supervised contrastive-based representation to boost the zero-shot capabilities of DFG.
-
Discriminators and Mutual Learning: ZeroDiff employs three discriminators to evaluate the generated features from various aspects and introduces a Wasserstein-distance-based mutual learning loss to transfer knowledge among the discriminators, enhancing the guidance for generation.
The researchers evaluated ZeroDiff on three popular ZSL benchmarks and showed that it outperforms existing ZSL methods. Notably, ZeroDiff also maintains robust performance even with scarce training data, as demonstrated by the FreeSeg-Diff and High Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning experiments.
Critical Analysis
The researchers acknowledge that their approach still has some limitations. For example, the performance of ZeroDiff can be affected by the quality and diversity of the semantic information available for the unseen classes. Additionally, the complexity of the diffusion-based generative model may make it computationally expensive compared to some simpler ZSL methods.
Further research could explore ways to make the ZeroDiff framework more efficient or investigate techniques to better leverage the available semantic information for unseen classes. Incorporating other types of side information, such as visual attributes, could also be a promising direction to enhance the zero-shot capabilities of the model.
Overall, the ZeroDiff approach represents an interesting and promising step forward in the field of Zero-Shot Learning, demonstrating the potential of diffusion-based generative models to improve data efficiency and classification performance for unseen classes.
Conclusion
The ZeroDiff framework introduced in this paper is a novel approach to Zero-Shot Learning that leverages diffusion models to enhance data efficiency at both the class and instance levels. By incorporating a two-branch generation structure and a mutual learning loss between multiple discriminators, ZeroDiff is able to outperform existing ZSL methods while maintaining robust performance even with limited training data.
This research highlights the potential of diffusion-based generative models to address the key challenges in Zero-Shot Learning, potentially making these techniques more practical and accessible for real-world applications. Further advancements in this area could lead to even more powerful AI systems capable of recognizing and understanding a wider range of concepts and objects.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Evolutionary Generalized Zero-Shot Learning
Dubing Chen, Chenyi Jiang, Haofeng Zhang
0
0
Attribute-based Zero-Shot Learning (ZSL) has revolutionized the ability of models to recognize new classes not seen during training. However, with the advancement of large-scale models, the expectations have risen. Beyond merely achieving zero-shot generalization, there is a growing demand for universal models that can continually evolve in expert domains using unlabeled data. To address this, we introduce a scaled-down instantiation of this challenge: Evolutionary Generalized Zero-Shot Learning (EGZSL). This setting allows a low-performing zero-shot model to adapt to the test data stream and evolve online. We elaborate on three challenges of this special task, ie, catastrophic forgetting, initial prediction bias, and evolutionary data class bias. Moreover, we propose targeted solutions for each challenge, resulting in a generic method capable of continuous evolution from a given initial IGZSL model. Experiments on three popular GZSL benchmark datasets demonstrate that our model can learn from the test data stream while other baselines fail. Codes are available at url{https://github.com/cdb342/EGZSL}.
5/14/2024
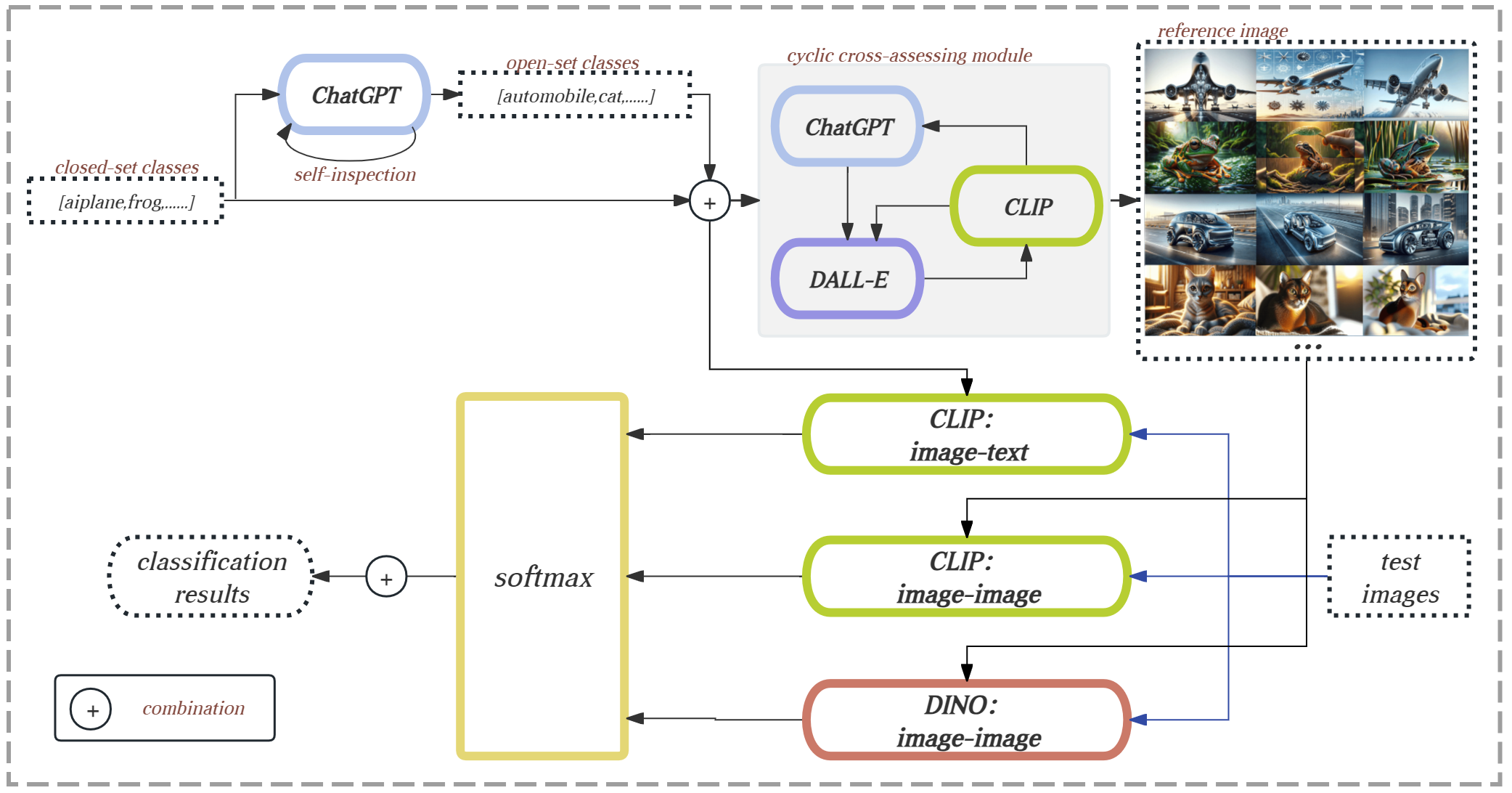
Multi-method Integration with Confidence-based Weighting for Zero-shot Image Classification
Siqi Yin, Lifan Jiang
0
0
This paper introduces a novel framework for zero-shot learning (ZSL), i.e., to recognize new categories that are unseen during training, by using a multi-model and multi-alignment integration method. Specifically, we propose three strategies to enhance the model's performance to handle ZSL: 1) Utilizing the extensive knowledge of ChatGPT and the powerful image generation capabilities of DALL-E to create reference images that can precisely describe unseen categories and classification boundaries, thereby alleviating the information bottleneck issue; 2) Integrating the results of text-image alignment and image-image alignment from CLIP, along with the image-image alignment results from DINO, to achieve more accurate predictions; 3) Introducing an adaptive weighting mechanism based on confidence levels to aggregate the outcomes from different prediction methods. Experimental results on multiple datasets, including CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate that our model can significantly improve classification accuracy compared to single-model approaches, achieving AUROC scores above 96% across all test datasets, and notably surpassing 99% on the CIFAR-10 dataset.
5/6/2024

Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Jiaqi Yue, Jiancheng Zhao, Chunhui Zhao
0
0
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.
5/24/2024
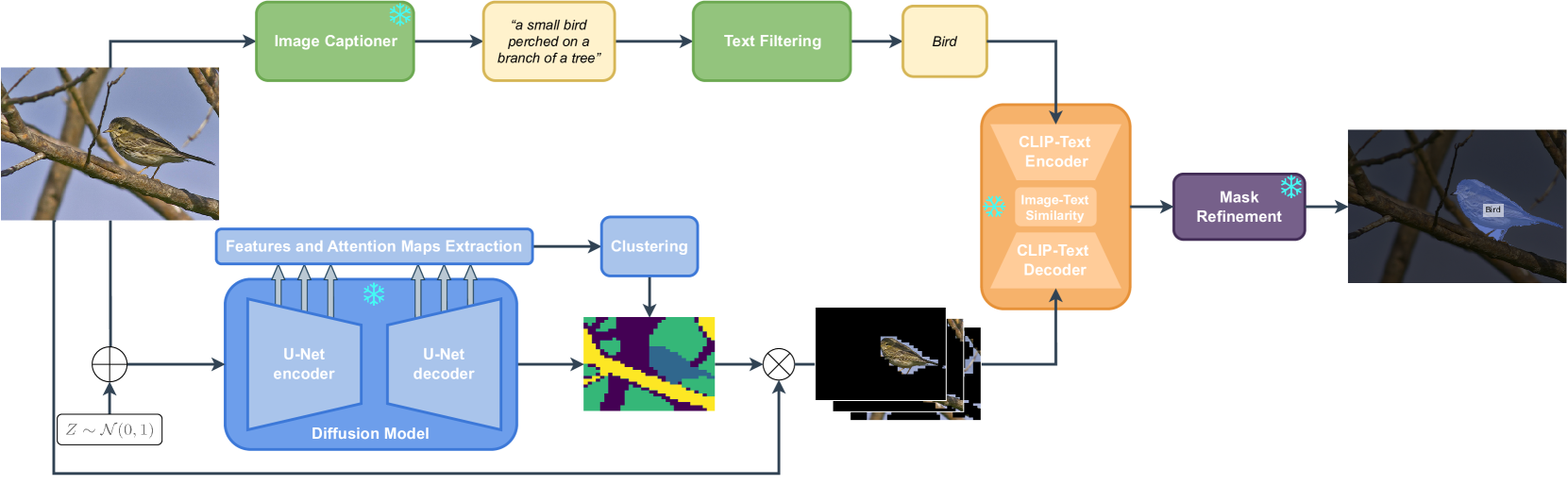
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024