High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning
2404.04953
0
0
Abstract
Zero-shot learning(ZSL) aims to recognize new classes without prior exposure to their samples, relying on semantic knowledge from observed classes. However, current attention-based models may overlook the transferability of visual features and the distinctiveness of attribute localization when learning regional features in images. Additionally, they often overlook shared attributes among different objects. Highly discriminative attribute features are crucial for identifying and distinguishing unseen classes. To address these issues, we propose an innovative approach called High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning (HDAFL). HDAFL optimizes visual features by learning attribute features to obtain discriminative visual embeddings. Specifically, HDAFL utilizes multiple convolutional kernels to automatically learn discriminative regions highly correlated with attributes in images, eliminating irrelevant interference in image features. Furthermore, we introduce a Transformer-based attribute discrimination encoder to enhance the discriminative capability among attributes. Simultaneously, the method employs contrastive loss to alleviate dataset biases and enhance the transferability of visual features, facilitating better semantic transfer between seen and unseen classes. Experimental results demonstrate the effectiveness of HDAFL across three widely used datasets.
Create account to get full access
Overview
- Proposes a method for high-discriminative attribute feature learning in generalized zero-shot learning (GZSL)
- Addresses the domain shift problem in GZSL by learning discriminative visual features for unseen classes
- Introduces a contrastive learning framework to capture both semantic and visual attributes
Plain English Explanation
This research paper presents a new method for generalized zero-shot learning (GZSL), which aims to classify images of objects that the model has not been trained on before. The key challenge in GZSL is the "domain shift" problem - the visual features of seen classes (those used for training) can be quite different from the unseen classes.
The proposed approach learns highly discriminative visual features for the unseen classes by using a contrastive learning framework. This framework captures both the semantic information (e.g., object attributes like "has wings") and the visual information (the actual appearance of the object) to better bridge the gap between seen and unseen classes.
The contrastive learning process encourages the model to learn visual features that are both informative about the object's attributes and highly distinct from other classes, seen or unseen. This helps the model better recognize and classify objects it has never encountered before during training.
Technical Explanation
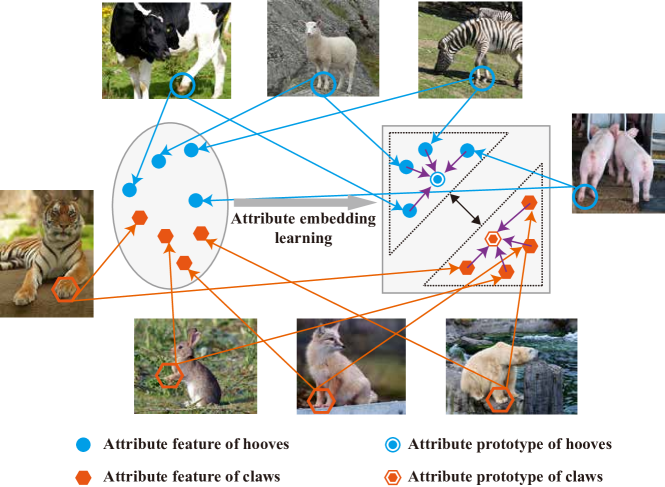
The paper introduces a new method called "High-Discriminative Attribute Feature Learning" (HDAFL) to address the domain shift problem in generalized zero-shot learning (GZSL).
HDAFL uses a contrastive learning framework to capture both semantic information (object attributes) and visual information (object appearance) in the learned visual features. Specifically, the model is trained to:
- Maximize the similarity between an image's visual features and its associated semantic attribute vector.
- Minimize the similarity between the image's visual features and the attribute vectors of other (dissimilar) classes, both seen and unseen.
This encourages the model to learn visual features that are highly discriminative - they are informative about the object's attributes while also being distinct from other classes. The authors hypothesize that this will help bridge the domain gap between seen and unseen classes, improving GZSL performance.
The contrastive learning objective is combined with a standard classification loss to jointly optimize the visual feature representation and the classification model. Extensive experiments on benchmark GZSL datasets demonstrate the effectiveness of the HDAFL approach compared to prior methods.
Critical Analysis
The paper presents a well-designed and thorough study on addressing the domain shift problem in generalized zero-shot learning. The key strengths of the HDAFL approach are:
- The use of contrastive learning to capture both semantic and visual attributes, which is a novel and promising direction for GZSL.
- The comprehensive experiments evaluating HDAFL on multiple datasets and comparing it to a wide range of state-of-the-art GZSL methods.
- The detailed analysis and ablation studies to understand the contributions of different components of the HDAFL framework.
However, the paper could be improved by discussing some potential limitations and areas for future work:
- The reliance on semantic attribute annotations, which may not be available for all datasets. Exploring zero-shot learning without such annotations could further enhance the practical applicability of the approach.
- The performance on extremely large-scale and open-ended GZSL scenarios, where the domain shift may be even more pronounced. Evaluating HDAFL on such challenging settings could provide additional insights.
- The computational complexity and training time of the contrastive learning framework, which may be a consideration for real-world deployment.
Overall, the HDAFL method represents a significant advancement in generalized zero-shot learning and the authors provide a solid technical foundation for future research in this important area.
Conclusion
This paper introduces a novel approach called "High-Discriminative Attribute Feature Learning" (HDAFL) to address the domain shift problem in generalized zero-shot learning (GZSL). HDAFL leverages a contrastive learning framework to capture both semantic and visual attributes in the learned visual features, making them highly discriminative between seen and unseen classes.
The extensive experiments demonstrate the effectiveness of HDAFL in improving GZSL performance compared to prior methods. While the reliance on semantic attributes and the computational complexity are potential limitations, the core ideas presented in this work represent a significant advancement in the field of zero-shot learning and can inspire future research directions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Exploring Data Efficiency in Zero-Shot Learning with Diffusion Models
Zihan Ye, Shreyank N. Gowda, Xiaobo Jin, Xiaowei Huang, Haotian Xu, Yaochu Jin, Kaizhu Huang
0
0
Zero-Shot Learning (ZSL) aims to enable classifiers to identify unseen classes by enhancing data efficiency at the class level. This is achieved by generating image features from pre-defined semantics of unseen classes. However, most current approaches heavily depend on the number of samples from seen classes, i.e. they do not consider instance-level effectiveness. In this paper, we demonstrate that limited seen examples generally result in deteriorated performance of generative models. To overcome these challenges, we propose ZeroDiff, a Diffusion-based Generative ZSL model. This unified framework incorporates diffusion models to improve data efficiency at both the class and instance levels. Specifically, for instance-level effectiveness, ZeroDiff utilizes a forward diffusion chain to transform limited data into an expanded set of noised data. For class-level effectiveness, we design a two-branch generation structure that consists of a Diffusion-based Feature Generator (DFG) and a Diffusion-based Representation Generator (DRG). DFG focuses on learning and sampling the distribution of cross-entropy-based features, whilst DRG learns the supervised contrastive-based representation to boost the zero-shot capabilities of DFG. Additionally, we employ three discriminators to evaluate generated features from various aspects and introduce a Wasserstein-distance-based mutual learning loss to transfer knowledge among discriminators, thereby enhancing guidance for generation. Demonstrated through extensive experiments on three popular ZSL benchmarks, our ZeroDiff not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code will be released upon acceptance.
6/6/2024

`Eyes of a Hawk and Ears of a Fox': Part Prototype Network for Generalized Zero-Shot Learning
Joshua Feinglass, Jayaraman J. Thiagarajan, Rushil Anirudh, T. S. Jayram, Yezhou Yang
0
0
Current approaches in Generalized Zero-Shot Learning (GZSL) are built upon base models which consider only a single class attribute vector representation over the entire image. This is an oversimplification of the process of novel category recognition, where different regions of the image may have properties from different seen classes and thus have different predominant attributes. With this in mind, we take a fundamentally different approach: a pre-trained Vision-Language detector (VINVL) sensitive to attribute information is employed to efficiently obtain region features. A learned function maps the region features to region-specific attribute attention used to construct class part prototypes. We conduct experiments on a popular GZSL benchmark consisting of the CUB, SUN, and AWA2 datasets where our proposed Part Prototype Network (PPN) achieves promising results when compared with other popular base models. Corresponding ablation studies and analysis show that our approach is highly practical and has a distinct advantage over global attribute attention when localized proposals are available.
4/16/2024
🌐
Dual Relation Mining Network for Zero-Shot Learning
Jinwei Han, Yingguo Gao, Zhiwen Lin, Ke Yan, Shouhong Ding, Yuan Gao, Gui-Song Xia
0
0
Zero-shot learning (ZSL) aims to recognize novel classes through transferring shared semantic knowledge (e.g., attributes) from seen classes to unseen classes. Recently, attention-based methods have exhibited significant progress which align visual features and attributes via a spatial attention mechanism. However, these methods only explore visual-semantic relationship in the spatial dimension, which can lead to classification ambiguity when different attributes share similar attention regions, and semantic relationship between attributes is rarely discussed. To alleviate the above problems, we propose a Dual Relation Mining Network (DRMN) to enable more effective visual-semantic interactions and learn semantic relationship among attributes for knowledge transfer. Specifically, we introduce a Dual Attention Block (DAB) for visual-semantic relationship mining, which enriches visual information by multi-level feature fusion and conducts spatial attention for visual to semantic embedding. Moreover, an attribute-guided channel attention is utilized to decouple entangled semantic features. For semantic relationship modeling, we utilize a Semantic Interaction Transformer (SIT) to enhance the generalization of attribute representations among images. Additionally, a global classification branch is introduced as a complement to human-defined semantic attributes, and we then combine the results with attribute-based classification. Extensive experiments demonstrate that the proposed DRMN leads to new state-of-the-art performances on three standard ZSL benchmarks, i.e., CUB, SUN, and AwA2.
5/7/2024

Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Jiaqi Yue, Jiancheng Zhao, Chunhui Zhao
0
0
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.
5/24/2024