Multi-method Integration with Confidence-based Weighting for Zero-shot Image Classification
2405.02155
0
0
Abstract
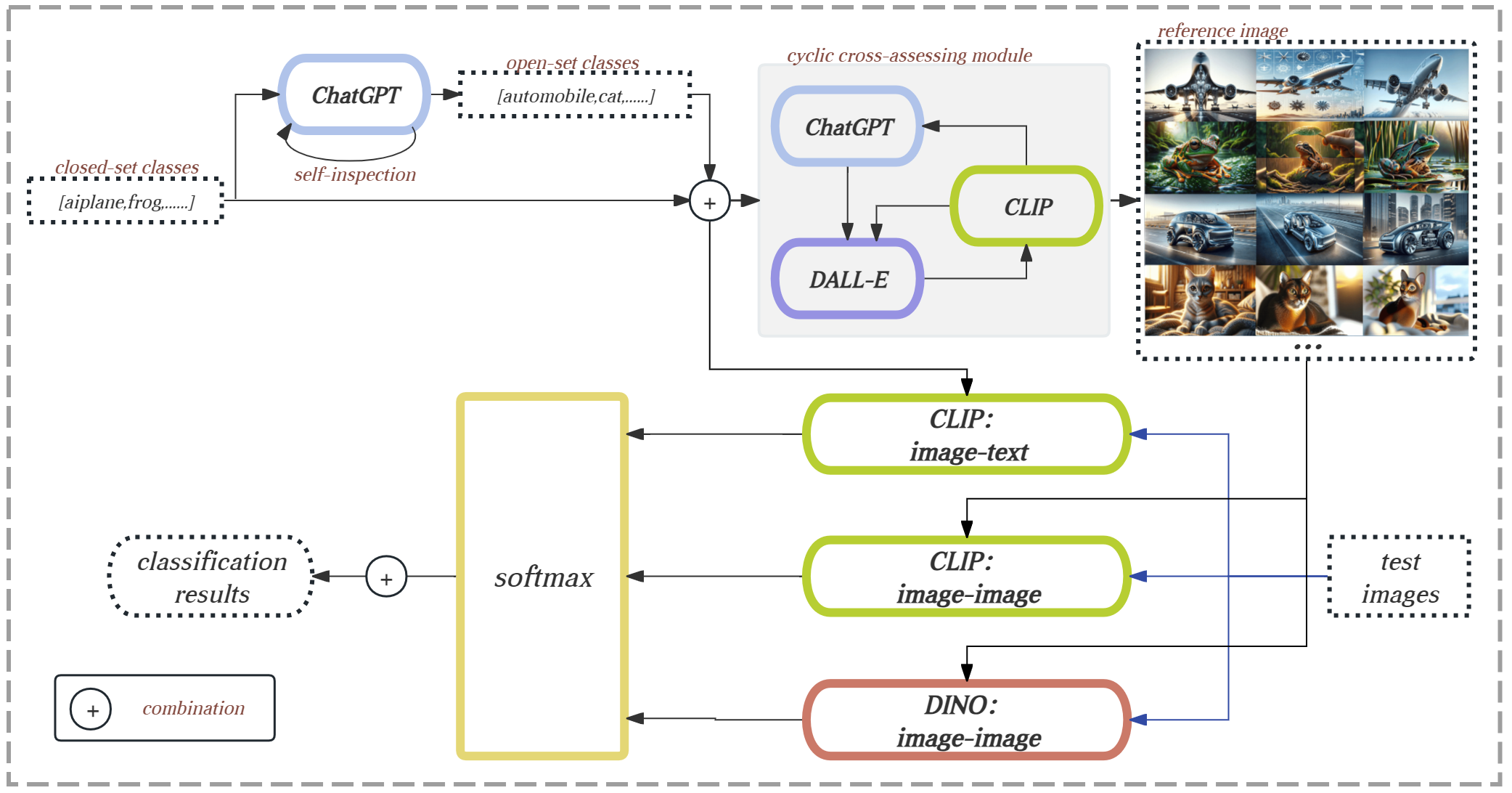
This paper introduces a novel framework for zero-shot learning (ZSL), i.e., to recognize new categories that are unseen during training, by using a multi-model and multi-alignment integration method. Specifically, we propose three strategies to enhance the model's performance to handle ZSL: 1) Utilizing the extensive knowledge of ChatGPT and the powerful image generation capabilities of DALL-E to create reference images that can precisely describe unseen categories and classification boundaries, thereby alleviating the information bottleneck issue; 2) Integrating the results of text-image alignment and image-image alignment from CLIP, along with the image-image alignment results from DINO, to achieve more accurate predictions; 3) Introducing an adaptive weighting mechanism based on confidence levels to aggregate the outcomes from different prediction methods. Experimental results on multiple datasets, including CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate that our model can significantly improve classification accuracy compared to single-model approaches, achieving AUROC scores above 96% across all test datasets, and notably surpassing 99% on the CIFAR-10 dataset.
Create account to get full access
Overview
- This paper proposes a multi-method integration approach with confidence-based weighting for zero-shot image classification tasks.
- The method combines multiple pre-trained models, each with its own strengths, and weights their predictions based on the model's confidence to improve overall performance.
- The approach is evaluated on several zero-shot image classification benchmarks and shows significant improvements over using a single model.
Plain English Explanation
In the field of image classification, zero-shot learning is a challenging task where the model must classify images of objects it has never seen before. To tackle this problem, the researchers in this paper developed a method that combines the predictions of multiple pre-trained models, each with its own unique capabilities, and then weights those predictions based on how confident each model is in its predictions.
The idea is that by drawing on the strengths of multiple models, the system can make more accurate classifications than any single model alone. For example, one model might be really good at identifying animals, while another excels at recognizing vehicles. By combining their predictions and weighting them based on confidence, the overall system can take advantage of the best of both models to classify a wider range of objects accurately.
The researchers tested their approach on several standard benchmarks for zero-shot image classification and found that it outperformed using a single model significantly. This suggests that their multi-method integration with confidence-based weighting is a promising approach for improving the performance of zero-shot image classification systems.
Technical Explanation
The key elements of the paper's approach are:
-
Multi-method Integration: The system combines the predictions of multiple pre-trained models, each trained on a different dataset or using a different architecture. This allows the system to leverage the unique strengths of each model.
-
Confidence-based Weighting: The model predictions are weighted based on the confidence score output by each model. Models that are more confident in their predictions are given higher weights, allowing their predictions to carry more influence in the final decision.
-
Zero-shot Learning: The system is evaluated on zero-shot image classification tasks, where the model must classify images of objects it has never seen before during training.
The researchers conducted experiments on several zero-shot image classification benchmarks, including ProgSV, DZTN, and CREST. They found that their multi-method integration approach with confidence-based weighting significantly outperformed using a single model, demonstrating the effectiveness of their technique for zero-shot image classification.
Critical Analysis
The paper provides a solid technical contribution to the field of zero-shot image classification. However, some potential limitations and areas for further research are:
-
Model Selection: The paper does not provide a systematic approach for selecting the pre-trained models to be integrated. The performance of the system may be heavily dependent on the choice of models, and further research could explore automated or principled methods for model selection.
-
Confidence Estimation: The paper relies on the confidence scores output by the pre-trained models, but these scores may not always be well-calibrated or accurately reflect the true uncertainty of the predictions. Exploring alternative ways of estimating model confidence could further improve the weighting scheme.
-
Generalization to Other Tasks: While the paper demonstrates the effectiveness of the approach for zero-shot image classification, it is unclear how well the method would generalize to other zero-shot learning problems, such as zero-shot text classification or zero-shot multi-label classification. Further research is needed to assess the broader applicability of the technique.
Conclusion
This paper presents a promising approach for improving zero-shot image classification by integrating multiple pre-trained models and weighting their predictions based on confidence. The results demonstrate significant performance gains over using a single model, suggesting that this multi-method integration technique could be a valuable tool for researchers and practitioners working on challenging zero-shot learning problems. As with any research, there are opportunities for further refinement and exploration, but this work represents an important step forward in addressing the challenges of zero-shot image classification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CICA: Content-Injected Contrastive Alignment for Zero-Shot Document Image Classification
Sankalp Sinha, Muhammad Saif Ullah Khan, Talha Uddin Sheikh, Didier Stricker, Muhammad Zeshan Afzal
0
0
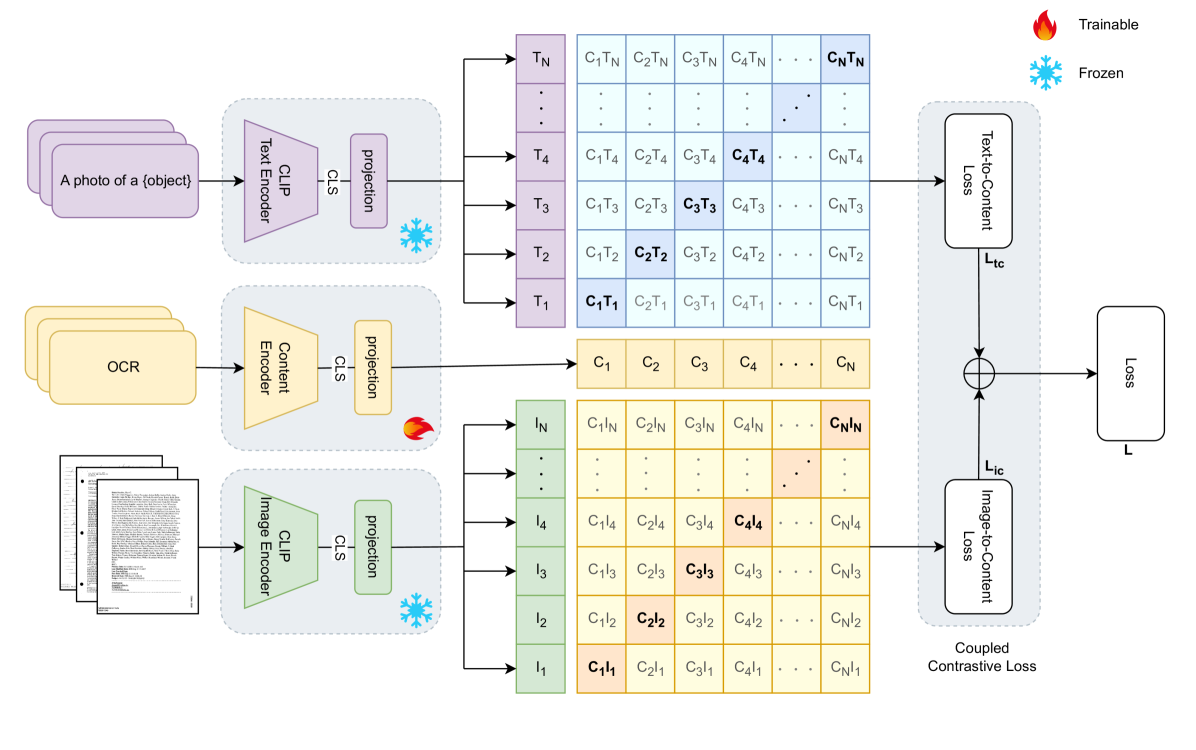
Zero-shot learning has been extensively investigated in the broader field of visual recognition, attracting significant interest recently. However, the current work on zero-shot learning in document image classification remains scarce. The existing studies either focus exclusively on zero-shot inference, or their evaluation does not align with the established criteria of zero-shot evaluation in the visual recognition domain. We provide a comprehensive document image classification analysis in Zero-Shot Learning (ZSL) and Generalized Zero-Shot Learning (GZSL) settings to address this gap. Our methodology and evaluation align with the established practices of this domain. Additionally, we propose zero-shot splits for the RVL-CDIP dataset. Furthermore, we introduce CICA (pronounced 'ki-ka'), a framework that enhances the zero-shot learning capabilities of CLIP. CICA consists of a novel 'content module' designed to leverage any generic document-related textual information. The discriminative features extracted by this module are aligned with CLIP's text and image features using a novel 'coupled-contrastive' loss. Our module improves CLIP's ZSL top-1 accuracy by 6.7% and GZSL harmonic mean by 24% on the RVL-CDIP dataset. Our module is lightweight and adds only 3.3% more parameters to CLIP. Our work sets the direction for future research in zero-shot document classification.
5/7/2024
📊
Exploring Data Efficiency in Zero-Shot Learning with Diffusion Models
Zihan Ye, Shreyank N. Gowda, Xiaobo Jin, Xiaowei Huang, Haotian Xu, Yaochu Jin, Kaizhu Huang
0
0
Zero-Shot Learning (ZSL) aims to enable classifiers to identify unseen classes by enhancing data efficiency at the class level. This is achieved by generating image features from pre-defined semantics of unseen classes. However, most current approaches heavily depend on the number of samples from seen classes, i.e. they do not consider instance-level effectiveness. In this paper, we demonstrate that limited seen examples generally result in deteriorated performance of generative models. To overcome these challenges, we propose ZeroDiff, a Diffusion-based Generative ZSL model. This unified framework incorporates diffusion models to improve data efficiency at both the class and instance levels. Specifically, for instance-level effectiveness, ZeroDiff utilizes a forward diffusion chain to transform limited data into an expanded set of noised data. For class-level effectiveness, we design a two-branch generation structure that consists of a Diffusion-based Feature Generator (DFG) and a Diffusion-based Representation Generator (DRG). DFG focuses on learning and sampling the distribution of cross-entropy-based features, whilst DRG learns the supervised contrastive-based representation to boost the zero-shot capabilities of DFG. Additionally, we employ three discriminators to evaluate generated features from various aspects and introduce a Wasserstein-distance-based mutual learning loss to transfer knowledge among discriminators, thereby enhancing guidance for generation. Demonstrated through extensive experiments on three popular ZSL benchmarks, our ZeroDiff not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code will be released upon acceptance.
6/6/2024

Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Shiming Chen, Wenjin Hou, Salman Khan, Fahad Shahbaz Khan
0
0
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2.
4/12/2024
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
Abdelrahman Abdelhamed, Mahmoud Afifi, Alec Go
0
0
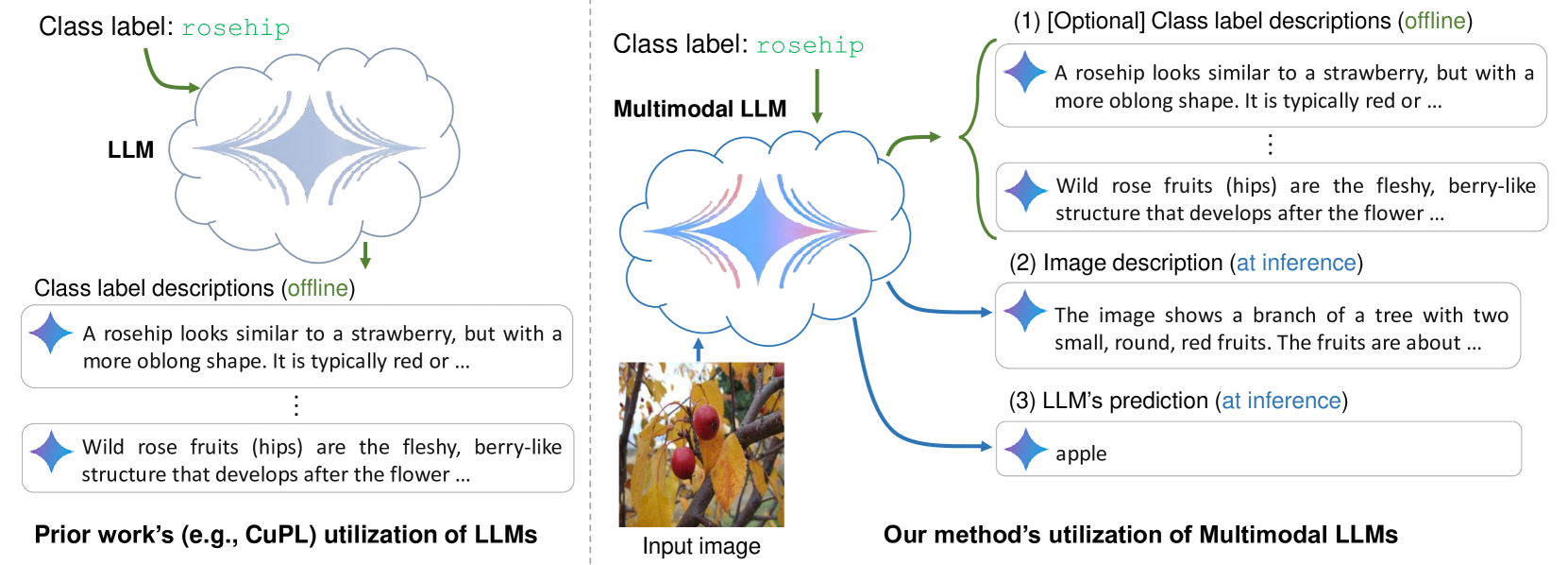
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
5/27/2024