Exploring Effects of Hyperdimensional Vectors for Tsetlin Machines

0

Sign in to get full access
Overview
- Explores the use of hyperdimensional vectors in Tsetlin Machines, a type of AI model
- Evaluates the performance and characteristics of this "Hypervector Tsetlin Machine"
- Compares the Hypervector Tsetlin Machine to standard Tsetlin Machines across various datasets and tasks
Plain English Explanation
The paper investigates the effects of using hyperdimensional vectors in a type of AI model called a Tsetlin Machine. Tsetlin Machines are known for their interpretability and ability to solve complex problems with simple rules.
The researchers created a new version called the "Hypervector Tsetlin Machine" that leverages high-dimensional vectors instead of the standard binary features used in regular Tsetlin Machines. The goal was to see if this change could improve the model's performance on various tasks.
The paper compares the Hypervector Tsetlin Machine to standard Tsetlin Machines across different datasets and problem types. It evaluates factors like classification accuracy, stability, and training time. The results suggest the Hypervector approach can offer advantages in certain scenarios, such as better handling of noisy or high-dimensional data.
Overall, the research explores an interesting way to enhance a widely-used AI model, with potential benefits for applications requiring interpretable and robust machine learning.
Technical Explanation
The paper proposes a variant of the Tsetlin Machine called the "Hypervector Tsetlin Machine" that uses high-dimensional vectors instead of binary features.
In a standard Tsetlin Machine, each input feature is represented by a pair of Tsetlin automata that learn to detect the presence or absence of that feature. The Hypervector Tsetlin Machine replaces these binary feature representations with high-dimensional (e.g. 10,000 dimensional) random vectors.
The researchers hypothesized that the Hypervector representation could better capture complex patterns in the data, leading to improved performance. To test this, they conducted experiments on several benchmark datasets, comparing the Hypervector Tsetlin Machine to regular Tsetlin Machines in terms of classification accuracy, stability, and training time.
The results showed that the Hypervector Tsetlin Machine outperformed standard Tsetlin Machines on noisy or high-dimensional datasets, demonstrating higher accuracy and more stable performance. However, the Hypervector model also had longer training times due to the increased computational complexity of the high-dimensional vector operations.
Critical Analysis
The paper provides a thorough investigation of the Hypervector Tsetlin Machine approach, including thoughtful comparisons to standard Tsetlin Machines across multiple datasets and tasks. The researchers acknowledge the trade-off between the potential performance benefits and the increased computational cost of the Hypervector representation.
One limitation mentioned is that the Hypervector Tsetlin Machine may not provide advantages in simpler or lower-dimensional datasets, where the standard Tsetlin Machine approach may be more efficient. Further research could explore ways to dynamically adjust the dimensionality of the Hypervectors based on the complexity of the problem.
Additionally, the paper does not delve into the interpretability of the Hypervector Tsetlin Machine compared to the standard version. As Tsetlin Machines are valued for their transparency, it would be interesting to understand how the high-dimensional vector representations impact the model's interpretability and ability to provide explanations for its decisions.
Overall, the research presents a promising direction for enhancing the capabilities of Tsetlin Machines, with potential applications in domains requiring robust and interpretable machine learning. The findings motivate further exploration of hyperdimensional representations in other AI models and architectures.
Conclusion
This paper investigates the use of hyperdimensional vectors in Tsetlin Machines, a type of interpretable AI model. The researchers developed a "Hypervector Tsetlin Machine" that replaces the standard binary feature representations with high-dimensional random vectors.
The results show that the Hypervector approach can offer advantages in terms of classification accuracy and stability, particularly on noisy or high-dimensional datasets. However, this comes at the cost of increased computational complexity and longer training times.
The findings contribute to the ongoing research on enhancing the capabilities of Tsetlin Machines, with potential applications in domains requiring interpretable and robust machine learning. Further work could explore ways to balance the performance benefits and computational efficiency of the Hypervector representation, as well as its impacts on the model's interpretability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Effects of Hyperdimensional Vectors for Tsetlin Machines
Vojtech Halenka, Ahmed K. Kadhim, Paul F. A. Clarke, Bimal Bhattarai, Rupsa Saha, Ole-Christoffer Granmo, Lei Jiao, Per-Arne Andersen
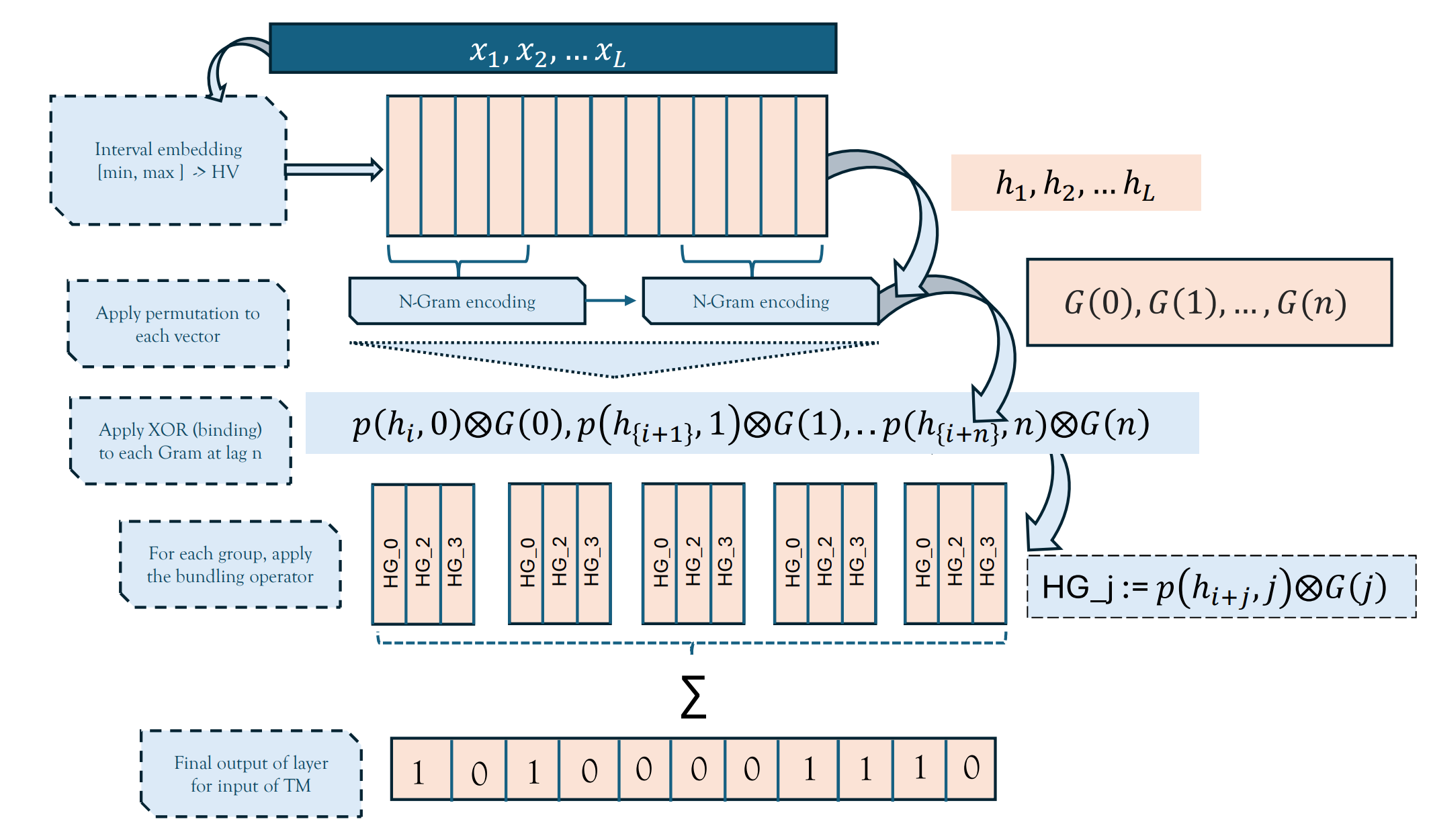
Tsetlin machines (TMs) have been successful in several application domains, operating with high efficiency on Boolean representations of the input data. However, Booleanizing complex data structures such as sequences, graphs, images, signal spectra, chemical compounds, and natural language is not trivial. In this paper, we propose a hypervector (HV) based method for expressing arbitrarily large sets of concepts associated with any input data. Using a hyperdimensional space to build vectors drastically expands the capacity and flexibility of the TM. We demonstrate how images, chemical compounds, and natural language text are encoded according to the proposed method, and how the resulting HV-powered TM can achieve significantly higher accuracy and faster learning on well-known benchmarks. Our results open up a new research direction for TMs, namely how to expand and exploit the benefits of operating in hyperspace, including new booleanization strategies, optimization of TM inference and learning, as well as new TM applications.
Read more6/6/2024
0
Hyperdimensional Vector Tsetlin Machines with Applications to Sequence Learning and Generation
Christian D. Blakely
We construct a two-layered model for learning and generating sequential data that is both computationally fast and competitive with vanilla Tsetlin machines, adding numerous advantages. Through the use of hyperdimensional vector computing (HVC) algebras and Tsetlin machine clause structures, we demonstrate that the combination of both inherits the generality of data encoding and decoding of HVC with the fast interpretable nature of Tsetlin machines to yield a powerful machine learning model. We apply the approach in two areas, namely in forecasting, generating new sequences, and classification. For the latter, we derive results for the entire UCR Time Series Archive and compare with the standard benchmarks to see how well the method competes in time series classification.
Read more8/30/2024
0
Hyperdimensional Quantum Factorization
Prathyush Poduval, Zhuowen Zou, Alvaro Velasquez, Mohsen Imani
This paper presents a quantum algorithm for efficiently decoding hypervectors, a crucial process in extracting atomic elements from hypervectors - an essential task in Hyperdimensional Computing (HDC) models for interpretable learning and information retrieval. HDC employs high-dimensional vectors and efficient operators to encode and manipulate information, representing complex objects from atomic concepts. When one attempts to decode a hypervector that is the product (binding) of multiple hypervectors, the factorization becomes prohibitively costly with classical optimization-based methods and specialized recurrent networks, an inherent consequence of the binding operation. We propose HDQF, an innovative quantum computing approach, to address this challenge. By exploiting parallels between HDC and quantum computing and capitalizing on quantum algorithms' speedup capabilities, HDQF encodes potential factors as a quantum superposition using qubit states and bipolar vector representation. This yields a quadratic speedup over classical search methods and effectively mitigates Hypervector Factorization capacity issues.
Read more6/19/2024

0
HVT: A Comprehensive Vision Framework for Learning in Non-Euclidean Space
Jacob Fein-Ashley, Ethan Feng, Minh Pham
Data representation in non-Euclidean spaces has proven effective for capturing hierarchical and complex relationships in real-world datasets. Hyperbolic spaces, in particular, provide efficient embeddings for hierarchical structures. This paper introduces the Hyperbolic Vision Transformer (HVT), a novel extension of the Vision Transformer (ViT) that integrates hyperbolic geometry. While traditional ViTs operate in Euclidean space, our method enhances the self-attention mechanism by leveraging hyperbolic distance and Mobius transformations. This enables more effective modeling of hierarchical and relational dependencies in image data. We present rigorous mathematical formulations, showing how hyperbolic geometry can be incorporated into attention layers, feed-forward networks, and optimization. We offer improved performance for image classification using the ImageNet dataset.
Read more9/27/2024