Exploring Hint Generation Approaches in Open-Domain Question Answering

0

Sign in to get full access
Overview
- Explores different approaches for generating helpful hints in open-domain question answering systems
- Introduces a new dataset called TriviaHG for evaluating hint generation
- Proposes two novel hint generation models and compares their performance to existing methods
Plain English Explanation
The paper explores ways to generate useful hints to assist users when they are struggling to answer open-ended questions. Open-domain question answering systems are designed to provide answers to a wide variety of questions, but users may still need some guidance or prompting to reach the final answer.
The researchers created a new dataset called TriviaHG, which contains questions along with annotated hints that can help users arrive at the correct answer. They then developed two new hint generation models and tested them against existing techniques.
The first model, called Internal Hint Generation, generates hints by learning to "awaken" relevant knowledge within the model. The second model, Retrieval-Augmented Generation, combines retrieval of relevant information with natural language generation to produce tailored hints.
The paper evaluates the performance of these new hint generation approaches on the TriviaHG dataset and compares them to prior methods. The results provide insights into effective strategies for developing open-domain question answering systems that can better support users in finding the right answers.
Technical Explanation
The paper introduces two novel hint generation approaches for open-domain question answering:
-
Internal Hint Generation: This model learns to "awaken" relevant knowledge within the language model to generate helpful hints. It uses a multi-task training procedure that combines question answering and hint generation objectives.
-
Retrieval-Augmented Generation: This approach combines information retrieval and natural language generation to produce tailored hints. It first retrieves relevant passages from a knowledge base, then uses that context to generate a hint.
The researchers also introduce a new dataset called TriviaHG, which contains questions along with annotated hints that can assist users in arriving at the correct answer. This dataset is used to evaluate the performance of the proposed hint generation models.
Experiments show that the Internal Hint Generation and Retrieval-Augmented Generation models outperform previous hint generation approaches on the TriviaHG dataset. The results indicate that leveraging internal knowledge and retrieving relevant information can be effective strategies for generating high-quality hints in open-domain question answering systems.
Critical Analysis
The paper makes a valuable contribution by exploring innovative approaches to hint generation, which can enhance the user experience and learning outcomes of open-domain question answering systems. The introduction of the TriviaHG dataset also provides a useful benchmark for evaluating hint generation techniques.
However, the paper does not deeply explore the limitations or potential biases of the proposed models. For example, it is unclear how the models would perform on more complex or ambiguous questions, or how well the generated hints would work for users with different backgrounds and knowledge levels.
Additionally, the paper does not address the potential ethical concerns around hint generation, such as the risk of providing misleading or biased information to users. Further research could examine these issues and explore ways to ensure the generated hints are reliable, unbiased, and beneficial to users.
Conclusion
This paper presents compelling approaches for generating helpful hints in open-domain question answering systems. The proposed Internal Hint Generation and Retrieval-Augmented Generation models demonstrate improved performance over existing methods, suggesting that leveraging internal knowledge and external information can be effective strategies for producing high-quality hints.
The introduction of the TriviaHG dataset also provides a valuable resource for evaluating and advancing hint generation techniques. Overall, this research offers insights that could lead to the development of more user-friendly and effective open-domain question answering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Hint Generation Approaches in Open-Domain Question Answering
Jamshid Mozafari, Abdelrahman Abdallah, Bhawna Piryani, Adam Jatowt
Automatic Question Answering (QA) systems rely on contextual information to provide accurate answers. Commonly, contexts are prepared through either retrieval-based or generation-based methods. The former involves retrieving relevant documents from a corpus like Wikipedia, whereas the latter uses generative models such as Large Language Models (LLMs) to generate the context. In this paper, we introduce a novel context preparation approach called HINTQA, which employs Automatic Hint Generation (HG) techniques. Unlike traditional methods, HINTQA prompts LLMs to produce hints about potential answers for the question rather than generating relevant context. We evaluate our approach across three QA datasets including TriviaQA, NaturalQuestions, and Web Questions, examining how the number and order of hints impact performance. Our findings show that the HINTQA surpasses both retrieval-based and generation-based approaches. We demonstrate that hints enhance the accuracy of answers more than retrieved and generated contexts.
Read more9/25/2024
0
TriviaHG: A Dataset for Automatic Hint Generation from Factoid Questions
Jamshid Mozafari, Anubhav Jangra, Adam Jatowt
Nowadays, individuals tend to engage in dialogues with Large Language Models, seeking answers to their questions. In times when such answers are readily accessible to anyone, the stimulation and preservation of human's cognitive abilities, as well as the assurance of maintaining good reasoning skills by humans becomes crucial. This study addresses such needs by proposing hints (instead of final answers or before giving answers) as a viable solution. We introduce a framework for the automatic hint generation for factoid questions, employing it to construct TriviaHG, a novel large-scale dataset featuring 160,230 hints corresponding to 16,645 questions from the TriviaQA dataset. Additionally, we present an automatic evaluation method that measures the Convergence and Familiarity quality attributes of hints. To evaluate the TriviaHG dataset and the proposed evaluation method, we enlisted 10 individuals to annotate 2,791 hints and tasked 6 humans with answering questions using the provided hints. The effectiveness of hints varied, with success rates of 96%, 78%, and 36% for questions with easy, medium, and hard answers, respectively. Moreover, the proposed automatic evaluation methods showed a robust correlation with annotators' results. Conclusively, the findings highlight three key insights: the facilitative role of hints in resolving unknown questions, the dependence of hint quality on answer difficulty, and the feasibility of employing automatic evaluation methods for hint assessment.
Read more5/13/2024
🛸
0
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Read more5/30/2024
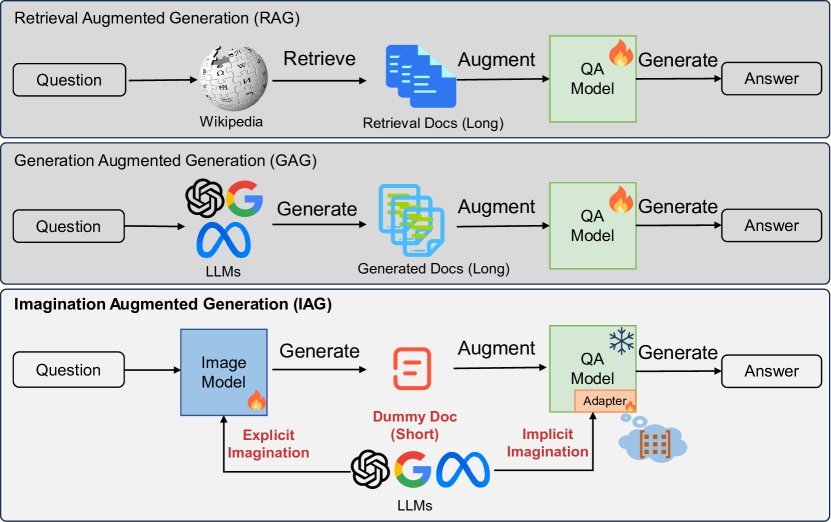
0
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Huanxuan Liao, Shizhu He, Yao Xu, Yuanzhe Zhang, Kang Liu, Shengping Liu, Jun Zhao
Retrieval-Augmented-Generation and Generation-Augmented-Generation have been proposed to enhance the knowledge required for question answering with Large Language Models (LLMs) by leveraging richer context. However, the former relies on external resources, and both require incorporating explicit documents into the context, which increases execution costs and susceptibility to noise data during inference. Recent works indicate that LLMs model rich knowledge, but it is often not effectively activated and awakened. Inspired by this, we propose a novel knowledge-augmented framework, $textbf{Awakening-Augmented-Generation}$ (AAG), which mimics the human ability to answer questions using only thinking and recalling to compensate for knowledge gaps, thereby awaking relevant knowledge in LLMs without relying on external resources. AAG consists of two key components for awakening richer context. Explicit awakening fine-tunes a context generator to create a synthetic, compressed document that functions as symbolic context. Implicit awakening utilizes a hypernetwork to generate adapters based on the question and synthetic document, which are inserted into LLMs to serve as parameter context. Experimental results on three datasets demonstrate that AAG exhibits significant advantages in both open-domain and closed-book settings, as well as in out-of-distribution generalization. Our code will be available at url{https://github.com/Xnhyacinth/IAG}.
Read more9/23/2024