Exploring Italian sentence embeddings properties through multi-tasking

0

Sign in to get full access
Overview
- This paper explores the properties of Italian sentence embeddings by training models on multiple tasks.
- The researchers investigate how different pre-training tasks affect the linguistic information captured in the sentence embeddings.
- They evaluate the models on various downstream tasks to understand the strengths and limitations of the embeddings.
Plain English Explanation
The researchers wanted to better understand the properties of sentence embeddings for the Italian language. Sentence embeddings are mathematical representations of sentences that capture the meaning and structure of the text. These embeddings are widely used in natural language processing tasks, but their inner workings are not always well understood.
To explore the Italian sentence embeddings, the researchers trained several models using different pre-training tasks. For example, some models were trained to predict the next word in a sentence, while others were trained to classify the sentiment of a sentence. By looking at how the models performed on various downstream tasks, the researchers could gain insights into what kind of linguistic information was being captured in the embeddings.
The key findings were that the pre-training task had a significant impact on the properties of the resulting sentence embeddings. Models trained on certain tasks were better at capturing syntactic information, while others were better at encoding semantic meaning. The researchers also identified specific strengths and weaknesses of the different embedding models when applied to real-world language tasks.
This research provides valuable insights for anyone working with Italian language models or trying to understand the inner workings of sentence embeddings more broadly. By shedding light on how the pre-training process shapes the properties of the embeddings, it can help researchers and practitioners make more informed choices when selecting or designing sentence embedding models for their applications.
Technical Explanation
The paper begins by reviewing the related work on sentence embeddings and the various techniques used to evaluate their linguistic properties. The researchers then describe their approach to training Italian sentence embedding models using different pre-training tasks, including next-sentence prediction, sentiment classification, and masked language modeling.
To assess the resulting embeddings, the team evaluated the models on a range of downstream tasks, such as sentence similarity, natural language inference, and dependency parsing. By analyzing the performance of the models on these tasks, they were able to gain insights into the types of linguistic information captured by the embeddings, such as syntactic structure, semantic meaning, and discourse-level features.
The key findings indicate that the pre-training task has a significant impact on the properties of the resulting sentence embeddings. For example, the models trained on next-sentence prediction tended to better capture discourse-level features, while the sentiment classification models were stronger at encoding semantic meaning. The researchers also observed that the embeddings could be further improved by fine-tuning the models on specific downstream tasks.
Critical Analysis
The paper provides a thorough and well-designed investigation of Italian sentence embeddings, but it also acknowledges several limitations and areas for further research. For instance, the researchers note that their study focused on a limited set of pre-training tasks and downstream evaluations, and that exploring a wider range of tasks could yield additional insights.
Additionally, the paper does not delve deeply into the potential biases or fairness implications of the sentence embedding models, which is an important consideration for real-world applications. The researchers also do not discuss the computational and memory requirements of the different models, which could be a relevant factor for some use cases.
Despite these limitations, the study makes a valuable contribution to the understanding of sentence embeddings and their linguistic properties. The findings can help inform the development of more sophisticated and context-appropriate Italian language models, and the general approach could be applied to other languages as well.
Conclusion
This paper presents a comprehensive investigation into the properties of Italian sentence embeddings, highlighting how the choice of pre-training task can significantly impact the linguistic information captured in the embeddings. The researchers' thorough evaluation on a range of downstream tasks provides valuable insights for researchers and practitioners working with Italian language models.
The findings suggest that there is no one-size-fits-all sentence embedding solution, and that the optimal approach may depend on the specific requirements of the application. By understanding the strengths and weaknesses of different embedding models, developers can make more informed decisions when selecting or designing sentence representations for their Italian natural language processing tasks.
Overall, this research contributes to a deeper understanding of sentence embeddings and their linguistic underpinnings, paving the way for more robust and versatile language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Italian sentence embeddings properties through multi-tasking
Vivi Nastase, Giuseppe Samo, Chunyang Jiang, Paola Merlo
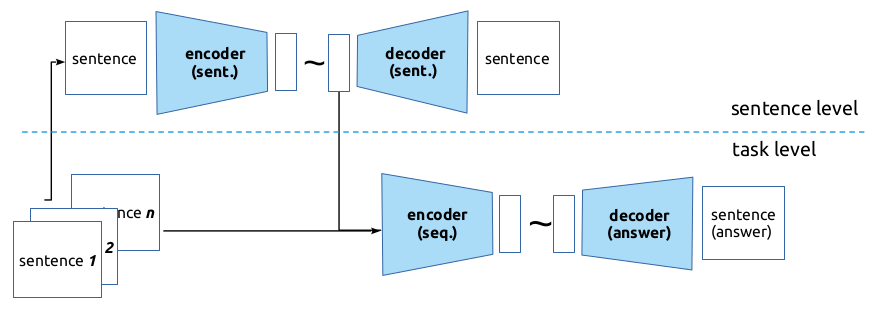
We investigate to what degree existing LLMs encode abstract linguistic information in Italian in a multi-task setting. We exploit curated synthetic data on a large scale -- several Blackbird Language Matrices (BLMs) problems in Italian -- and use them to study how sentence representations built using pre-trained language models encode specific syntactic and semantic information. We use a two-level architecture to model separately a compression of the sentence embeddings into a representation that contains relevant information for a task, and a BLM task. We then investigate whether we can obtain compressed sentence representations that encode syntactic and semantic information relevant to several BLM tasks. While we expected that the sentence structure -- in terms of sequence of phrases/chunks -- and chunk properties could be shared across tasks, performance and error analysis show that the clues for the different tasks are encoded in different manners in the sentence embeddings, suggesting that abstract linguistic notions such as constituents or thematic roles does not seem to be present in the pretrained sentence embeddings.
Read more9/11/2024
0
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Vivi Nastase, Chunyang Jiang, Giuseppe Samo, Paola Merlo
In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
Read more9/11/2024

0
Are there identifiable structural parts in the sentence embedding whole?
Vivi Nastase, Paola Merlo
Sentence embeddings from transformer models encode in a fixed length vector much linguistic information. We explore the hypothesis that these embeddings consist of overlapping layers of information that can be separated, and on which specific types of information -- such as information about chunks and their structural and semantic properties -- can be detected. We show that this is the case using a dataset consisting of sentences with known chunk structure, and two linguistic intelligence datasets, solving which relies on detecting chunks and their grammatical number, and respectively, their semantic roles, and through analyses of the performance on the tasks and of the internal representations built during learning.
Read more6/26/2024

0
Tracking linguistic information in transformer-based sentence embeddings through targeted sparsification
Vivi Nastase, Paola Merlo
Analyses of transformer-based models have shown that they encode a variety of linguistic information from their textual input. While these analyses have shed a light on the relation between linguistic information on one side, and internal architecture and parameters on the other, a question remains unanswered: how is this linguistic information reflected in sentence embeddings? Using datasets consisting of sentences with known structure, we test to what degree information about chunks (in particular noun, verb or prepositional phrases), such as grammatical number, or semantic role, can be localized in sentence embeddings. Our results show that such information is not distributed over the entire sentence embedding, but rather it is encoded in specific regions. Understanding how the information from an input text is compressed into sentence embeddings helps understand current transformer models and help build future explainable neural models.
Read more7/26/2024