Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement

0
Sign in to get full access
Overview
- Explores the syntax information captured in sentence embeddings using a subject-verb agreement (SVA) task across multiple languages
- Introduces BLM-Agr, a new multilingual dataset for evaluating SVA performance of sentence encoders
- Investigates the relationship between syntactic and semantic information in sentence embeddings
Plain English Explanation
This research paper examines how well sentence embedding models, which represent the meaning of sentences, are able to capture the syntactic structure of language. The researchers focus on the subject-verb agreement (SVA) task, which tests whether a model can correctly identify if a verb matches the subject of a sentence.
The key idea is that if a sentence embedding model understands the syntactic structure of a sentence, it should be able to perform well on the SVA task. The researchers create a new multilingual dataset called BLM-Agr to evaluate the SVA performance of different sentence encoding models across several languages.
By testing the models on this SVA task, the researchers can gain insights into the types of linguistic information that is represented in the sentence embeddings. This helps us understand the strengths and limitations of these powerful language models and how they might be improved to better capture the full richness of human language.
Technical Explanation
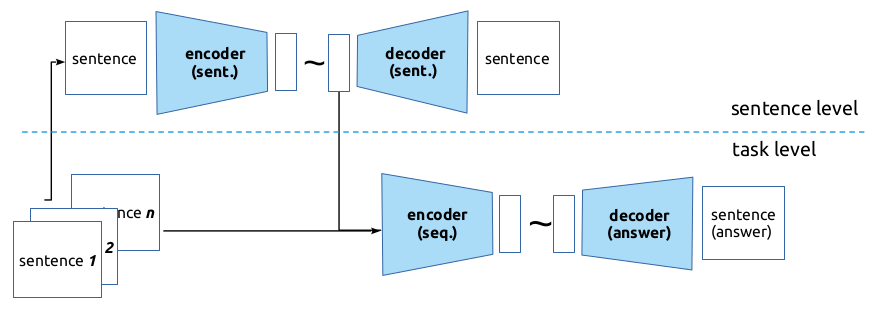
The paper introduces the Boundary Language Model (BLM) task as a way to evaluate the syntactic information in sentence embeddings. In the BLM task, the model must predict whether a given sentence is grammatically correct or not.
The researchers then create a new dataset called BLM-Agr, which extends the BLM task to focus specifically on subject-verb agreement (SVA) across multiple languages. The BLM-Agr dataset contains pairs of sentences that differ only in the agreement between the subject and verb, allowing the model's SVA capabilities to be directly assessed.
The paper evaluates several popular sentence encoding models, including BERT, RoBERTa, and InferSent, on the BLM-Agr dataset. The results show that while these models perform well on semantic tasks, they struggle to fully capture the syntactic relationships required for accurate SVA prediction.
The authors further analyze the relationship between syntactic and semantic information in the sentence embeddings. They find that the syntactic and semantic spaces are somewhat disentangled, suggesting that improving a model's syntactic understanding may require different training approaches than improving its semantic capabilities.
Critical Analysis
The paper provides a valuable contribution by introducing a new multilingual dataset (BLM-Agr) and using it to probe the syntactic capabilities of state-of-the-art sentence encoding models. The findings that current models have limitations in capturing fine-grained syntactic relationships are important for understanding the current limitations of these powerful language models.
However, the paper does not provide a comprehensive solution for how to better incorporate syntactic information into sentence embeddings. The authors mention that "further research is needed to fully understand the relationship between syntactic and semantic information in sentence representations," but do not offer concrete suggestions for how to address this challenge.
Additionally, the paper focuses only on the specific task of subject-verb agreement, which may not fully capture the breadth of syntactic phenomena in natural language. Exploring a wider range of syntactic tasks could provide a more complete picture of the models' syntactic understanding.
Overall, this paper is a valuable contribution to the field of natural language processing, but further research is needed to develop sentence encoding models that can more robustly capture both the semantic and syntactic aspects of language.
Conclusion
This research paper investigates the extent to which popular sentence encoding models can capture the syntactic structure of language, as measured by their performance on a subject-verb agreement (SVA) task. The authors introduce a new multilingual dataset called BLM-Agr to evaluate the SVA capabilities of models like BERT, RoBERTa, and InferSent.
The results show that while these models perform well on semantic tasks, they struggle to fully capture the fine-grained syntactic relationships required for accurate SVA prediction. This suggests that the syntactic and semantic information in sentence embeddings may be somewhat disentangled, and that improving a model's syntactic understanding may require different training approaches than improving its semantic capabilities.
The paper provides important insights into the limitations of current sentence encoding models and the need for further research to develop representations that can more robustly capture both the syntactic and semantic aspects of language. This work has implications for a wide range of natural language processing applications, from machine translation to question answering, where a deeper understanding of language structure is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Vivi Nastase, Chunyang Jiang, Giuseppe Samo, Paola Merlo
In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
Read more9/11/2024

0
Exploring Italian sentence embeddings properties through multi-tasking
Vivi Nastase, Giuseppe Samo, Chunyang Jiang, Paola Merlo
We investigate to what degree existing LLMs encode abstract linguistic information in Italian in a multi-task setting. We exploit curated synthetic data on a large scale -- several Blackbird Language Matrices (BLMs) problems in Italian -- and use them to study how sentence representations built using pre-trained language models encode specific syntactic and semantic information. We use a two-level architecture to model separately a compression of the sentence embeddings into a representation that contains relevant information for a task, and a BLM task. We then investigate whether we can obtain compressed sentence representations that encode syntactic and semantic information relevant to several BLM tasks. While we expected that the sentence structure -- in terms of sequence of phrases/chunks -- and chunk properties could be shared across tasks, performance and error analysis show that the clues for the different tasks are encoded in different manners in the sentence embeddings, suggesting that abstract linguistic notions such as constituents or thematic roles does not seem to be present in the pretrained sentence embeddings.
Read more9/11/2024
✨
0
Linear Cross-Lingual Mapping of Sentence Embeddings
Oleg Vasilyev, Fumika Isono, John Bohannon
Semantics of a sentence is defined with much less ambiguity than semantics of a single word, and we assume that it should be better preserved by translation to another language. If multilingual sentence embeddings intend to represent sentence semantics, then the similarity between embeddings of any two sentences must be invariant with respect to translation. Based on this suggestion, we consider a simple linear cross-lingual mapping as a possible improvement of the multilingual embeddings. We also consider deviation from orthogonality conditions as a measure of deficiency of the embeddings.
Read more6/28/2024
🔎
0
A Corpus for Sentence-level Subjectivity Detection on English News Articles
Francesco Antici, Andrea Galassi, Federico Ruggeri, Katerina Korre, Arianna Muti, Alessandra Bardi, Alice Fedotova, Alberto Barr'on-Cede~no
We develop novel annotation guidelines for sentence-level subjectivity detection, which are not limited to language-specific cues. We use our guidelines to collect NewsSD-ENG, a corpus of 638 objective and 411 subjective sentences extracted from English news articles on controversial topics. Our corpus paves the way for subjectivity detection in English and across other languages without relying on language-specific tools, such as lexicons or machine translation. We evaluate state-of-the-art multilingual transformer-based models on the task in mono-, multi-, and cross-language settings. For this purpose, we re-annotate an existing Italian corpus. We observe that models trained in the multilingual setting achieve the best performance on the task.
Read more5/27/2024