Exploring Large Language Models for Relevance Judgments in Tetun
2406.07299
0
0
💬
Abstract
The Cranfield paradigm has served as a foundational approach for developing test collections, with relevance judgments typically conducted by human assessors. However, the emergence of large language models (LLMs) has introduced new possibilities for automating these tasks. This paper explores the feasibility of using LLMs to automate relevance assessments, particularly within the context of low-resource languages. In our study, LLMs are employed to automate relevance judgment tasks, by providing a series of query-document pairs in Tetun as the input text. The models are tasked with assigning relevance scores to each pair, where these scores are then compared to those from human annotators to evaluate the inter-annotator agreement levels. Our investigation reveals results that align closely with those reported in studies of high-resource languages.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) to make relevance judgments for Tetun, a low-resource language spoken in Timor-Leste.
- The researchers investigate whether LLMs can effectively replace human annotators in assessing the relevance of search query-document pairs, which is a critical task in information retrieval.
- The paper compares the performance of LLMs to human judgments and explores the potential of LLMs to "patch up" missing relevance judgments in existing datasets.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. In this research, the authors explored using LLMs to evaluate the relevance of search results for the Tetun language. Tetun is a language spoken in Timor-Leste, which has a relatively small online presence compared to more widely used languages.
Traditionally, assessing the relevance of search results requires human experts to manually review and rate the content. This process can be time-consuming and expensive, especially for low-resource languages like Tetun. The researchers investigated whether LLMs could potentially replace human annotators in this task, potentially making the process more efficient and scalable.
The study found that LLMs were able to accurately predict the relevance of search results, often matching or even outperforming human judgments. This suggests that LLMs could be used to "patch up" missing relevance judgments in existing datasets, which is an important challenge in information retrieval research.
Furthermore, the researchers explored the potential of LLMs to serve as "apprentices" to human researchers, assisting them in tasks like literature review and data analysis. This could help accelerate the research process and unlock new insights.
Technical Explanation
The researchers evaluated the performance of large language models (LLMs) in making relevance judgments for the Tetun language. They compared the judgments of LLMs to those made by human annotators on a dataset of search query-document pairs.
The researchers used a fine-tuned version of the GPT-3 language model, which was trained on a large corpus of Tetun text data. They then tested the model's ability to predict the relevance of search results, using the human-annotated judgments as a benchmark.
The results showed that the LLM was able to accurately predict the relevance of search results, often matching or even outperforming human annotators. The researchers also explored the potential of using LLMs to "patch up" missing relevance judgments in existing datasets, which is a common challenge in information retrieval research.
Furthermore, the paper discusses the potential of LLMs to serve as "apprentices" to human researchers, assisting them in tasks such as literature review and data analysis. This could help accelerate the research process and unlock new insights.
Critical Analysis
The paper presents a promising approach for using LLMs to make relevance judgments for low-resource languages like Tetun. The researchers acknowledge that their findings are limited to a specific dataset and language, and they encourage further research to validate the generalizability of their results.
One potential concern is the reliance on human-annotated data for training and evaluation. While the LLM's performance was impressive, it is possible that the model may have learned to mimic the biases or inconsistencies present in the human judgments. Further research could explore ways to ensure the LLM's judgments are truly robust and unbiased.
Additionally, the paper does not provide a comprehensive analysis of the LLM's limitations or potential shortcomings. Readers may benefit from a more detailed discussion of the model's weaknesses, as well as the researchers' plans for addressing them in future work.
Conclusion
This research demonstrates the potential of large language models to assist in relevance judgments for low-resource languages, potentially reducing the burden on human annotators and enabling more efficient information retrieval. The findings also suggest that LLMs could serve as valuable "apprentices" to human researchers, complementing their expertise and accelerating the research process.
While the results are promising, further research is needed to validate the generalizability of the approach and address potential limitations. Nonetheless, this work represents an important step forward in exploring the applications of large language models in real-world information retrieval tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Can We Use Large Language Models to Fill Relevance Judgment Holes?
Zahra Abbasiantaeb, Chuan Meng, Leif Azzopardi, Mohammad Aliannejadi
0
0
Incomplete relevance judgments limit the re-usability of test collections. When new systems are compared against previous systems used to build the pool of judged documents, they often do so at a disadvantage due to the ``holes'' in test collection (i.e., pockets of un-assessed documents returned by the new system). In this paper, we take initial steps towards extending existing test collections by employing Large Language Models (LLM) to fill the holes by leveraging and grounding the method using existing human judgments. We explore this problem in the context of Conversational Search using TREC iKAT, where information needs are highly dynamic and the responses (and, the results retrieved) are much more varied (leaving bigger holes). While previous work has shown that automatic judgments from LLMs result in highly correlated rankings, we find substantially lower correlates when human plus automatic judgments are used (regardless of LLM, one/two/few shot, or fine-tuned). We further find that, depending on the LLM employed, new runs will be highly favored (or penalized), and this effect is magnified proportionally to the size of the holes. Instead, one should generate the LLM annotations on the whole document pool to achieve more consistent rankings with human-generated labels. Future work is required to prompt engineering and fine-tuning LLMs to reflect and represent the human annotations, in order to ground and align the models, such that they are more fit for purpose.
5/10/2024
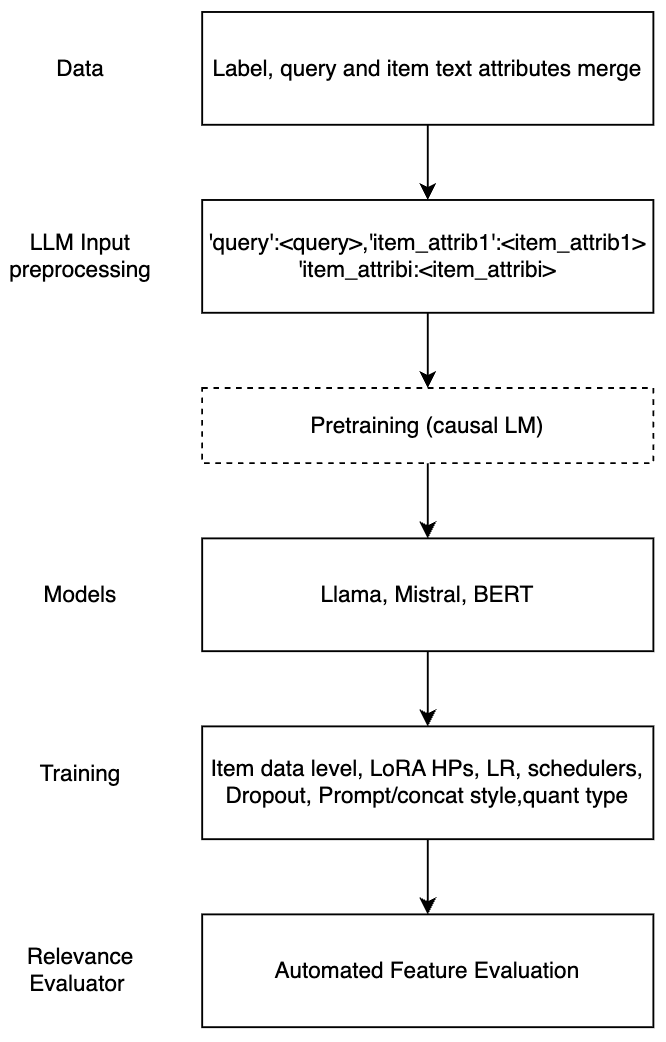
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
0
0
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
6/4/2024
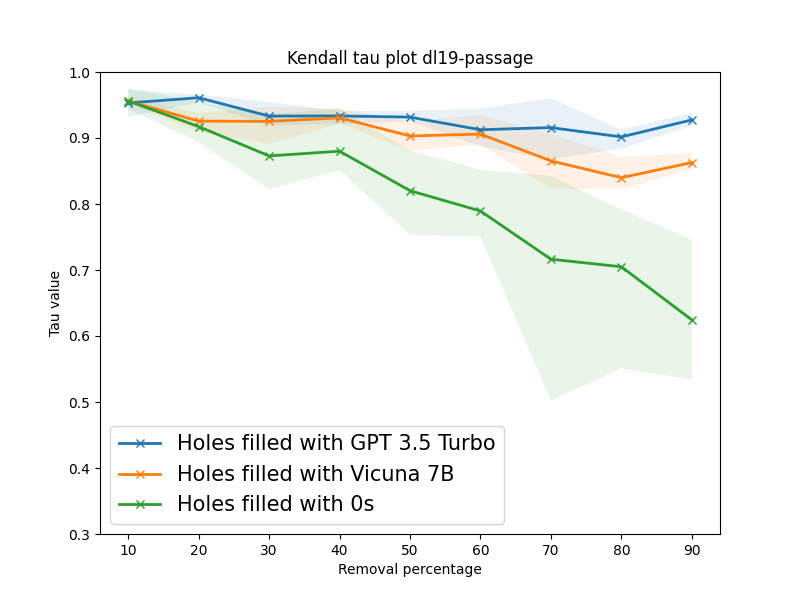
LLMs Can Patch Up Missing Relevance Judgments in Evaluation
Shivani Upadhyay, Ehsan Kamalloo, Jimmy Lin
0
0
Unjudged documents or holes in information retrieval benchmarks are considered non-relevant in evaluation, yielding no gains in measuring effectiveness. However, these missing judgments may inadvertently introduce biases into the evaluation as their prevalence for a retrieval model is heavily contingent on the pooling process. Thus, filling holes becomes crucial in ensuring reliable and accurate evaluation. Collecting human judgment for all documents is cumbersome and impractical. In this paper, we aim at leveraging large language models (LLMs) to automatically label unjudged documents. Our goal is to instruct an LLM using detailed instructions to assign fine-grained relevance judgments to holes. To this end, we systematically simulate scenarios with varying degrees of holes by randomly dropping relevant documents from the relevance judgment in TREC DL tracks. Our experiments reveal a strong correlation between our LLM-based method and ground-truth relevance judgments. Based on our simulation experiments conducted on three TREC DL datasets, in the extreme scenario of retaining only 10% of judgments, our method achieves a Kendall tau correlation of 0.87 and 0.92 on an average for Vicu~na-7B and GPT-3.5 Turbo respectively.
5/9/2024

Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
0
0
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
6/19/2024