Large language models can accurately predict searcher preferences
2309.10621
0
0
Abstract
Relevance labels, which indicate whether a search result is valuable to a searcher, are key to evaluating and optimising search systems. The best way to capture the true preferences of users is to ask them for their careful feedback on which results would be useful, but this approach does not scale to produce a large number of labels. Getting relevance labels at scale is usually done with third-party labellers, who judge on behalf of the user, but there is a risk of low-quality data if the labeller doesn't understand user needs. To improve quality, one standard approach is to study real users through interviews, user studies and direct feedback, find areas where labels are systematically disagreeing with users, then educate labellers about user needs through judging guidelines, training and monitoring. This paper introduces an alternate approach for improving label quality. It takes careful feedback from real users, which by definition is the highest-quality first-party gold data that can be derived, and develops an large language model prompt that agrees with that data. We present ideas and observations from deploying language models for large-scale relevance labelling at Bing, and illustrate with data from TREC. We have found large language models can be effective, with accuracy as good as human labellers and similar capability to pick the hardest queries, best runs, and best groups. Systematic changes to the prompts make a difference in accuracy, but so too do simple paraphrases. To measure agreement with real searchers needs high-quality gold labels, but with these we find that models produce better labels than third-party workers, for a fraction of the cost, and these labels let us train notably better rankers.
Create account to get full access
Overview
- This paper investigates how well large language models can predict searcher preferences for web search results.
- The researchers used a dataset of human-labeled search results from the TREC Robust track to train and evaluate their models.
- They found that large language models can accurately predict searcher preferences, suggesting they could be useful for offline evaluation of search quality.
Plain English Explanation
Large language models are artificial intelligence systems that can understand and generate human-like text. In this study, the researchers wanted to see if these models could accurately predict how users would judge the relevance of web search results.
To do this, they used a dataset of search results that had been manually labeled by people as more or less relevant. They trained large language models on this data, teaching the models to recognize the patterns of language and meaning that made a search result useful or not.
The researchers found that the language models were surprisingly good at predicting how users would rate the search results. This suggests that large language models could be helpful for evaluating search engine quality without needing to constantly get input from real users. The models could potentially spot when search results are not very useful, before the search engine is released to the public.
Overall, this research shows that the impressive language understanding capabilities of large language models can be applied to practical problems like improving search engines. By learning from human judgments, these AI systems can start to mimic how people assess the usefulness of information, which could lead to better search experiences in the future.
Technical Explanation
The researchers used a dataset from the TREC Robust information retrieval track, which contains human relevance judgments for search queries and web pages. They fine-tuned large language models like BERT and GPT-3 on this dataset, training the models to predict the relevance score that a human would assign to a given query-document pair.
The models were evaluated using standard information retrieval metrics like nDCG and MAP, which measure how well the predicted relevance scores match the ground truth human labels. The results showed that the fine-tuned language models could achieve strong performance, often outperforming traditional IR baselines.
The researchers also explored the interpretability of the language models' relevance predictions. By analyzing the attention weights within the models, they could identify which parts of the query and document text were most influential in the relevance assessment. This provides insights into how the models reason about relevance.
Overall, this work demonstrates that large language models can be effective at assessing searcher preferences without the need for explicit human labeling. This could enable more efficient offline evaluation of search quality, complementing traditional user studies and A/B tests.
Critical Analysis
The paper makes a compelling case that large language models can serve as accurate and scalable proxies for human relevance judgments in information retrieval. However, a few caveats are worth noting:
-
The experiments were limited to a single dataset (TREC Robust), which may not fully reflect the diversity of real-world search queries and content. Further testing on other datasets would strengthen the generalizability of the findings.
-
The models were fine-tuned on historical relevance judgments, which could bake in existing biases and blindspots of those human raters. Ensuring the models learn unbiased relevance assessment is an important area for future research.
-
While the attention analysis provides some interpretability, the inner workings of large neural networks can still be opaque. More research is needed to fully understand how these models arrive at their relevance predictions.
-
Offline evaluation is useful, but cannot fully substitute for real user testing. Combining language model insights with user feedback may yield the most robust search quality assurance.
Overall, this work represents an exciting step forward in leveraging large language models for practical applications in information retrieval. With further development and validation, these techniques could significantly enhance the efficiency and effectiveness of search engine optimization and improvement.
Conclusion
This paper demonstrates that large language models can be effectively trained to accurately predict human relevance judgments for web search results. By learning from historical data of how people evaluate the usefulness of search outputs, these AI systems can serve as scalable proxies for user preferences.
The implications of this research are significant. Large language models could enable more efficient offline evaluation of search engine quality, helping developers identify and fix relevance issues before releasing new search features. This could lead to better search experiences for users in the long run.
The work also highlights the remarkable capability of large language models to reason about complex, contextual information like relevance. As these AI systems continue to advance, they may find increasing applications in a wide range of information-centric domains beyond just web search.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
0
0
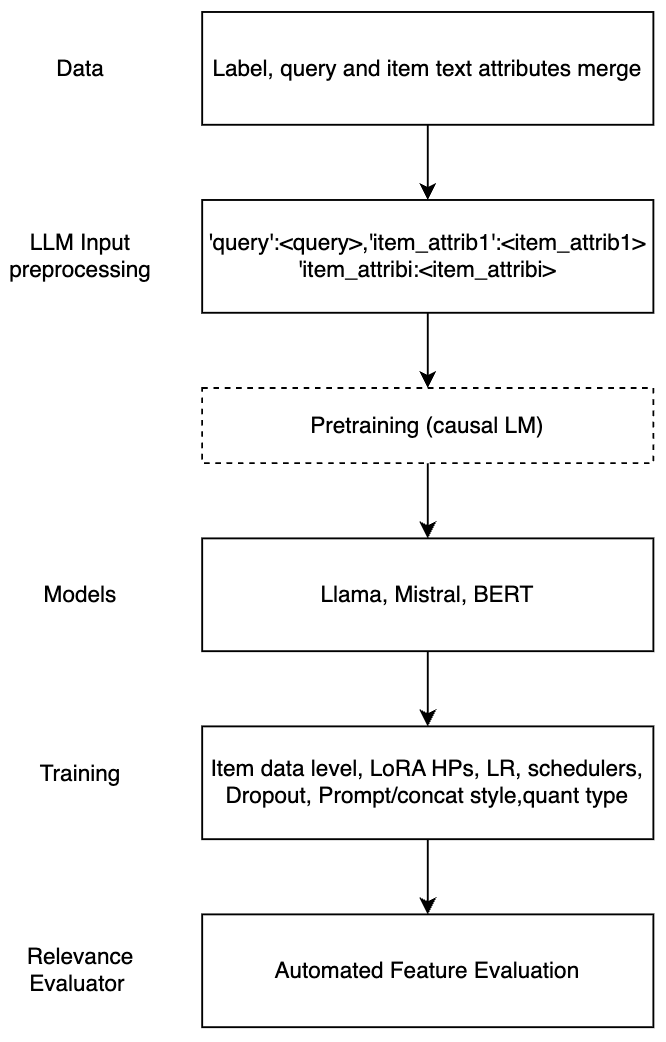
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
6/4/2024
💬
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
0
0
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
5/24/2024

Can We Use Large Language Models to Fill Relevance Judgment Holes?
Zahra Abbasiantaeb, Chuan Meng, Leif Azzopardi, Mohammad Aliannejadi
0
0
Incomplete relevance judgments limit the re-usability of test collections. When new systems are compared against previous systems used to build the pool of judged documents, they often do so at a disadvantage due to the ``holes'' in test collection (i.e., pockets of un-assessed documents returned by the new system). In this paper, we take initial steps towards extending existing test collections by employing Large Language Models (LLM) to fill the holes by leveraging and grounding the method using existing human judgments. We explore this problem in the context of Conversational Search using TREC iKAT, where information needs are highly dynamic and the responses (and, the results retrieved) are much more varied (leaving bigger holes). While previous work has shown that automatic judgments from LLMs result in highly correlated rankings, we find substantially lower correlates when human plus automatic judgments are used (regardless of LLM, one/two/few shot, or fine-tuned). We further find that, depending on the LLM employed, new runs will be highly favored (or penalized), and this effect is magnified proportionally to the size of the holes. Instead, one should generate the LLM annotations on the whole document pool to achieve more consistent rankings with human-generated labels. Future work is required to prompt engineering and fine-tuning LLMs to reflect and represent the human annotations, in order to ground and align the models, such that they are more fit for purpose.
5/10/2024
💬
Exploring Large Language Models for Relevance Judgments in Tetun
Gabriel de Jesus, S'ergio Nunes
0
0
The Cranfield paradigm has served as a foundational approach for developing test collections, with relevance judgments typically conducted by human assessors. However, the emergence of large language models (LLMs) has introduced new possibilities for automating these tasks. This paper explores the feasibility of using LLMs to automate relevance assessments, particularly within the context of low-resource languages. In our study, LLMs are employed to automate relevance judgment tasks, by providing a series of query-document pairs in Tetun as the input text. The models are tasked with assigning relevance scores to each pair, where these scores are then compared to those from human annotators to evaluate the inter-annotator agreement levels. Our investigation reveals results that align closely with those reported in studies of high-resource languages.
6/12/2024